


Volume 17 Number 3
Developing Computational Models for Formalizing Concepts in the British Colonial India Corpus
Abstract
The concepts embedded in humanities materials are unstructured and possess multifaceted attributes. New insights from these materials are derived through systematic qualitative study. However, for the purpose of quantitative analysis using digital humanities methods and tools, formalizing these concepts becomes imperative. The functionality of digital humanities relies on the deployment of formalized concepts and models. Formalization converts unstructured data into a more structured form. Concurrently, models function as representations created to closely examine the modeled subject, while metamodels define the structure and properties of these models. In this case, the absence of formalized concepts and models for studying the British India colonial corpus hampers the computational application to address humanities research questions quantitatively. The texts are intricate, and the format is non-standard, as colonial officials documented extensive information to govern and control the colonized people and land. In this scenario, the British India colonial corpus cannot be effectively utilized for topic-specific research questions employing advanced text mining without formalizing the concepts within it. This article addresses the questions of what the most effective approach is for identifying multifaceted concepts within the non-standard British colonial India corpus through models and how these concepts can be formalized using formal models. It also explores how metamodels can be developed based on this experiment for a similar corpus.
1. Introduction
2. Creating computational models to formalize concepts in the British India colonial corpus
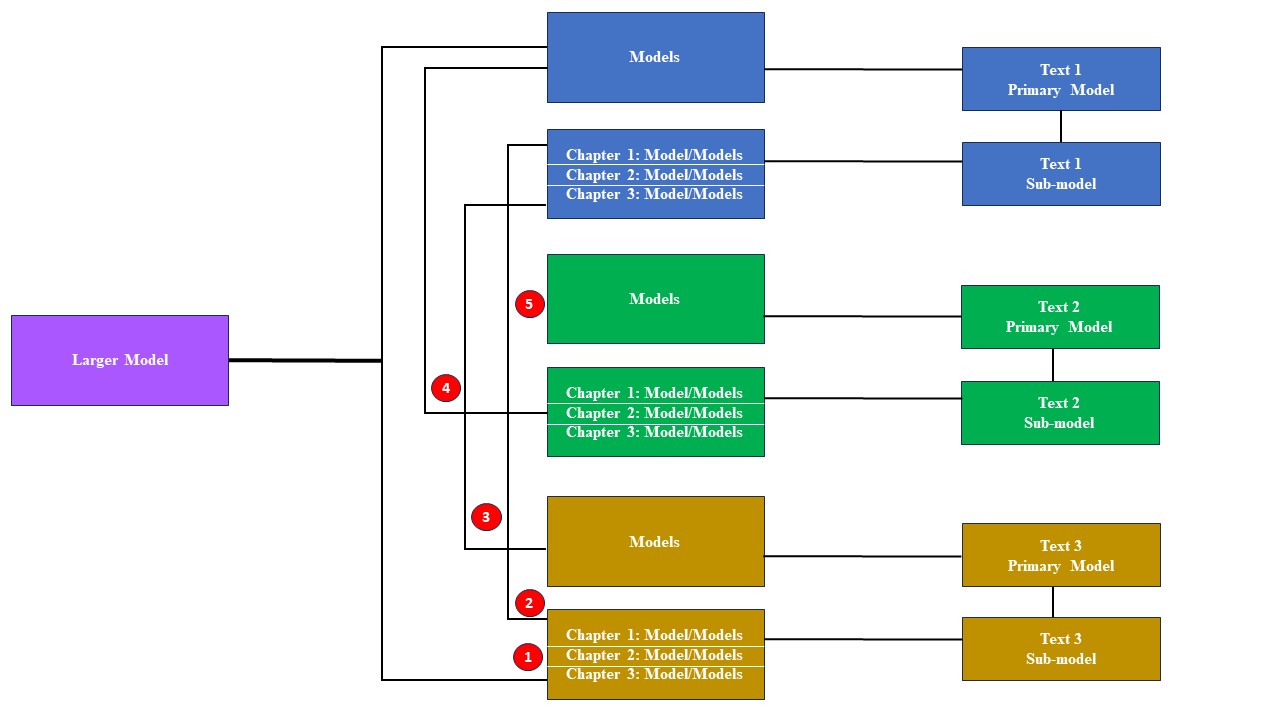
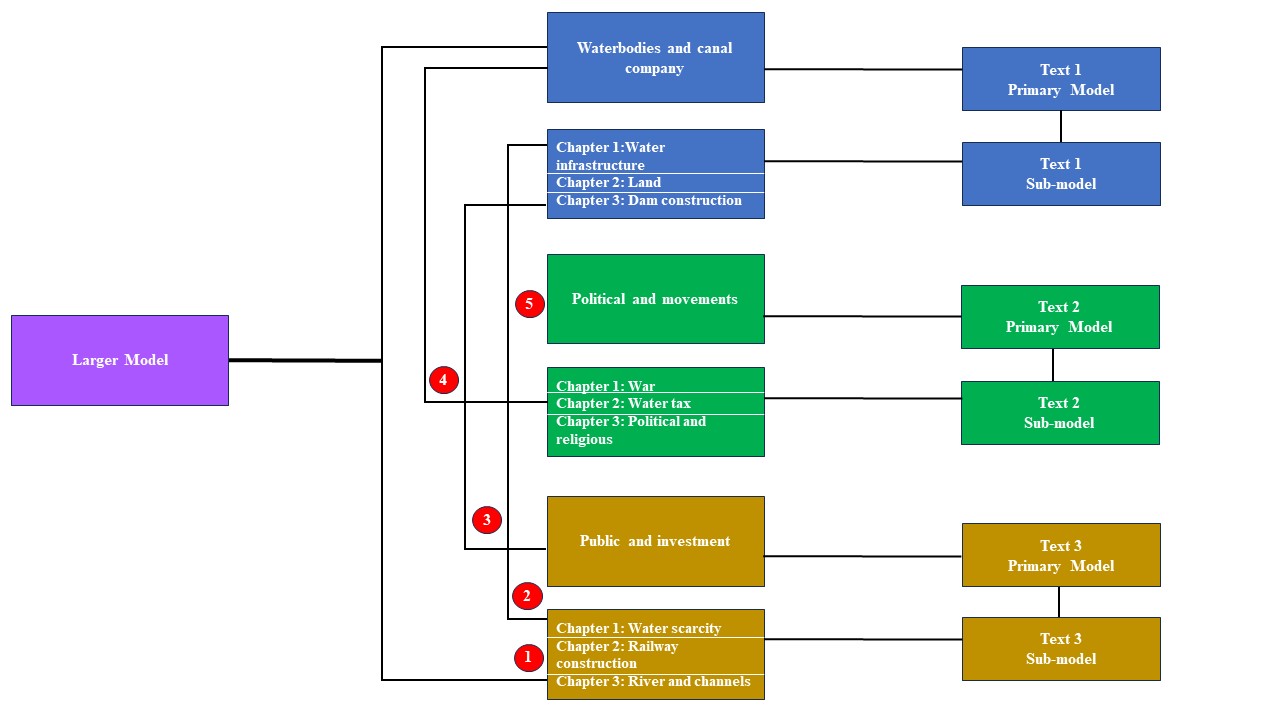
3. Methodology
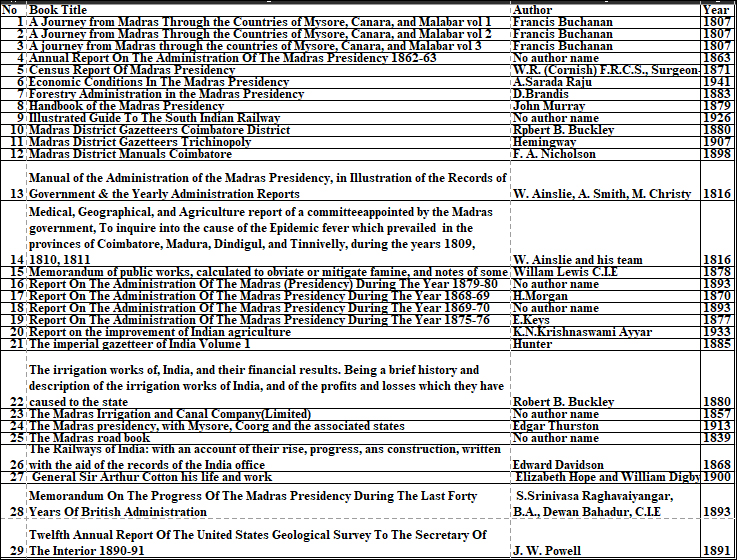
4. Discussion
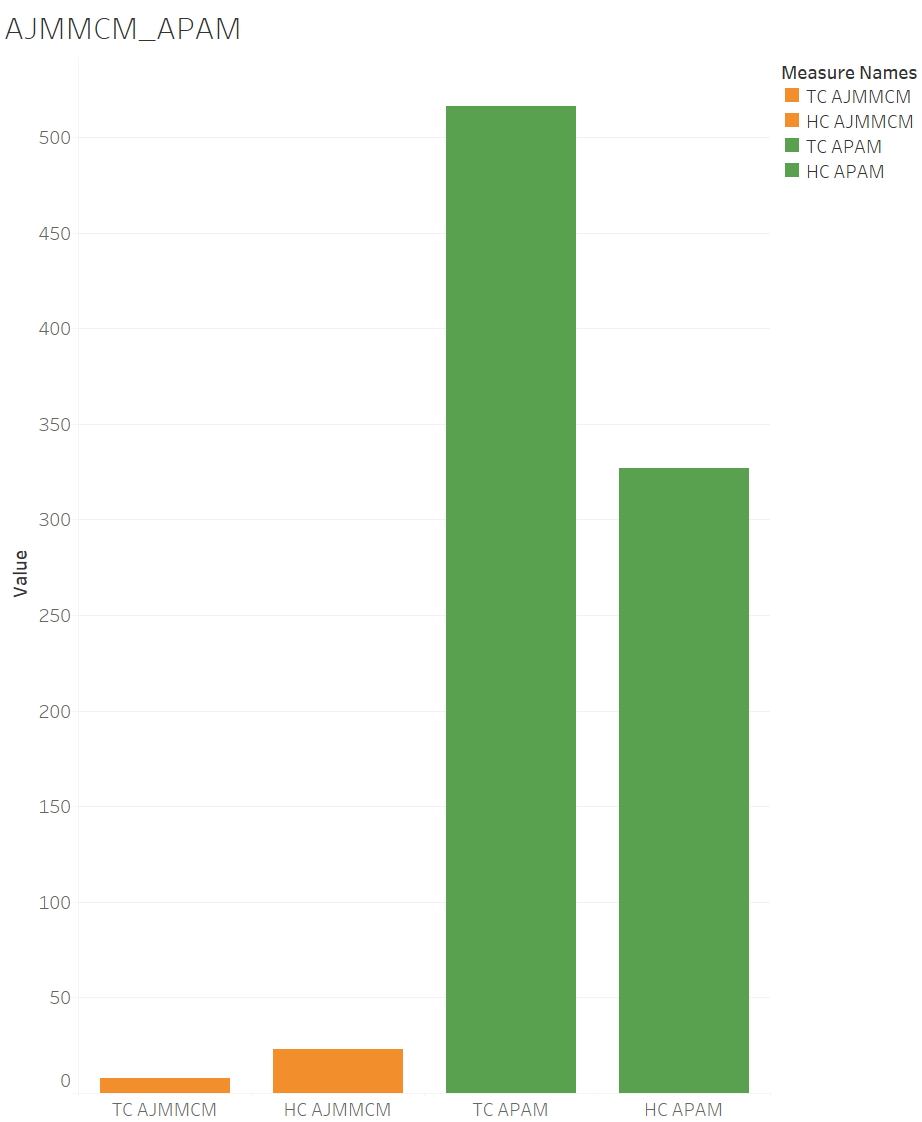
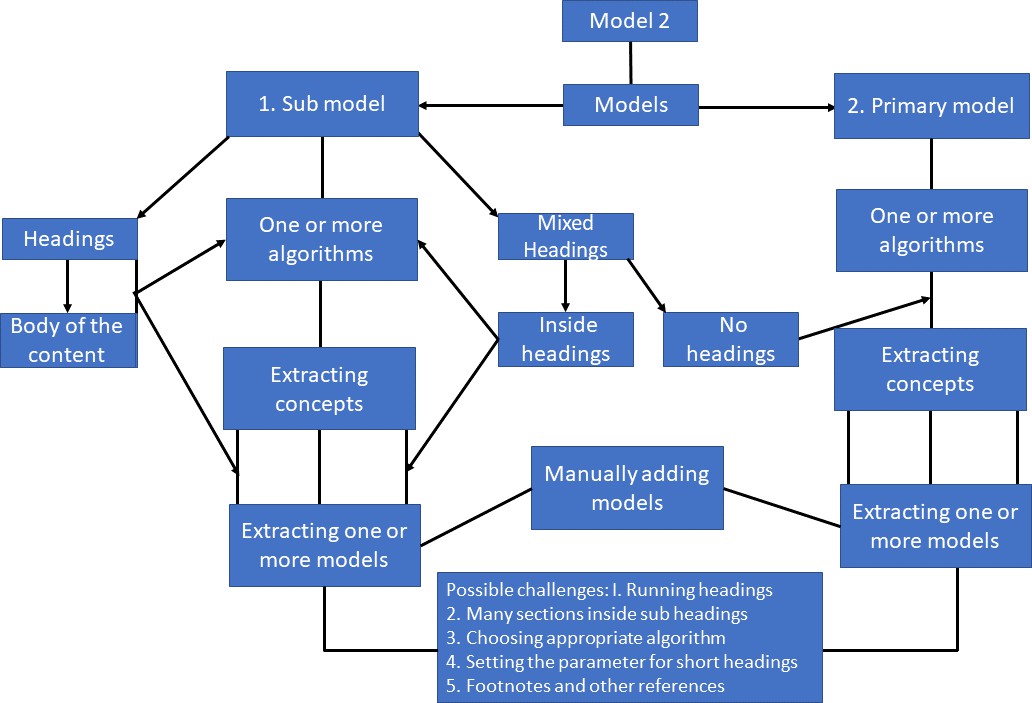
Distribution of concepts in sub-model and primary model
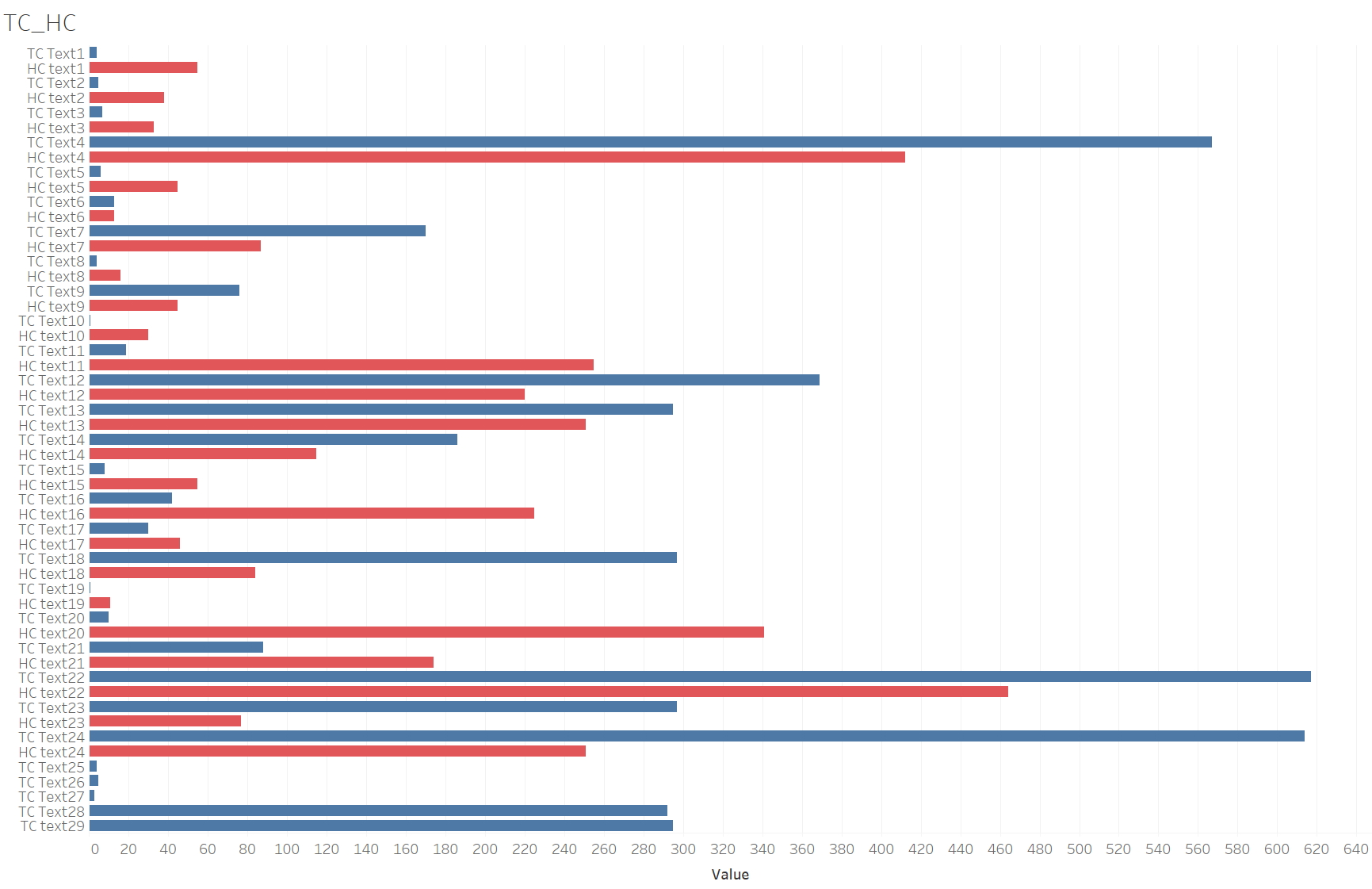
For many British officials, India was a vast collection of numbers. This mentality began in the early seventeenth century with the arrival of British merchants who compiled and transmitted lists of products, prices, customs and duties, weights and measures, and the values of various coins. [Cohn 1996, 8]
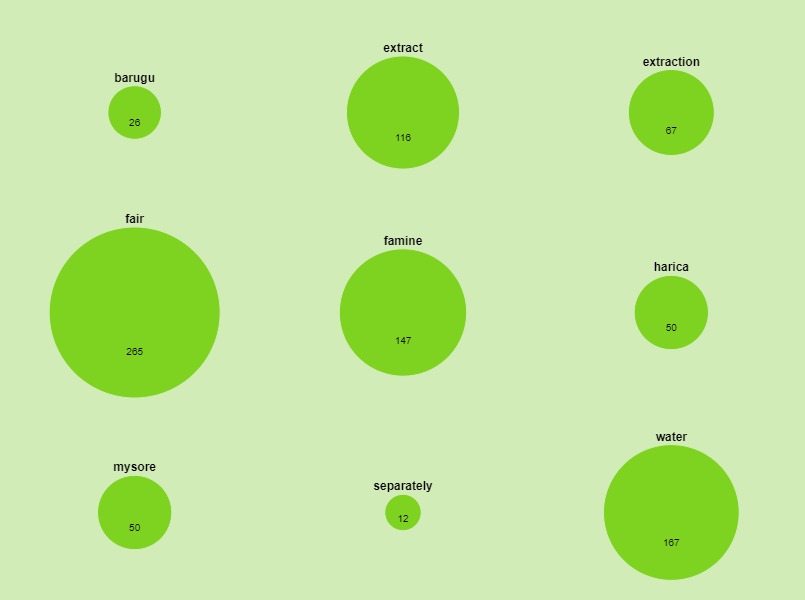
Studying the models
Of these crops Jola (Holcus sorghum) is the greatest. There are two kinds of it, the white and the red which are sometimes kept separate, and sometimes sown mixed. The red is the most common. Immediately after cutting the Vaisaka, crop: of, rice, plough four times in the course of twenty days. [Buchanan 1807, 283]
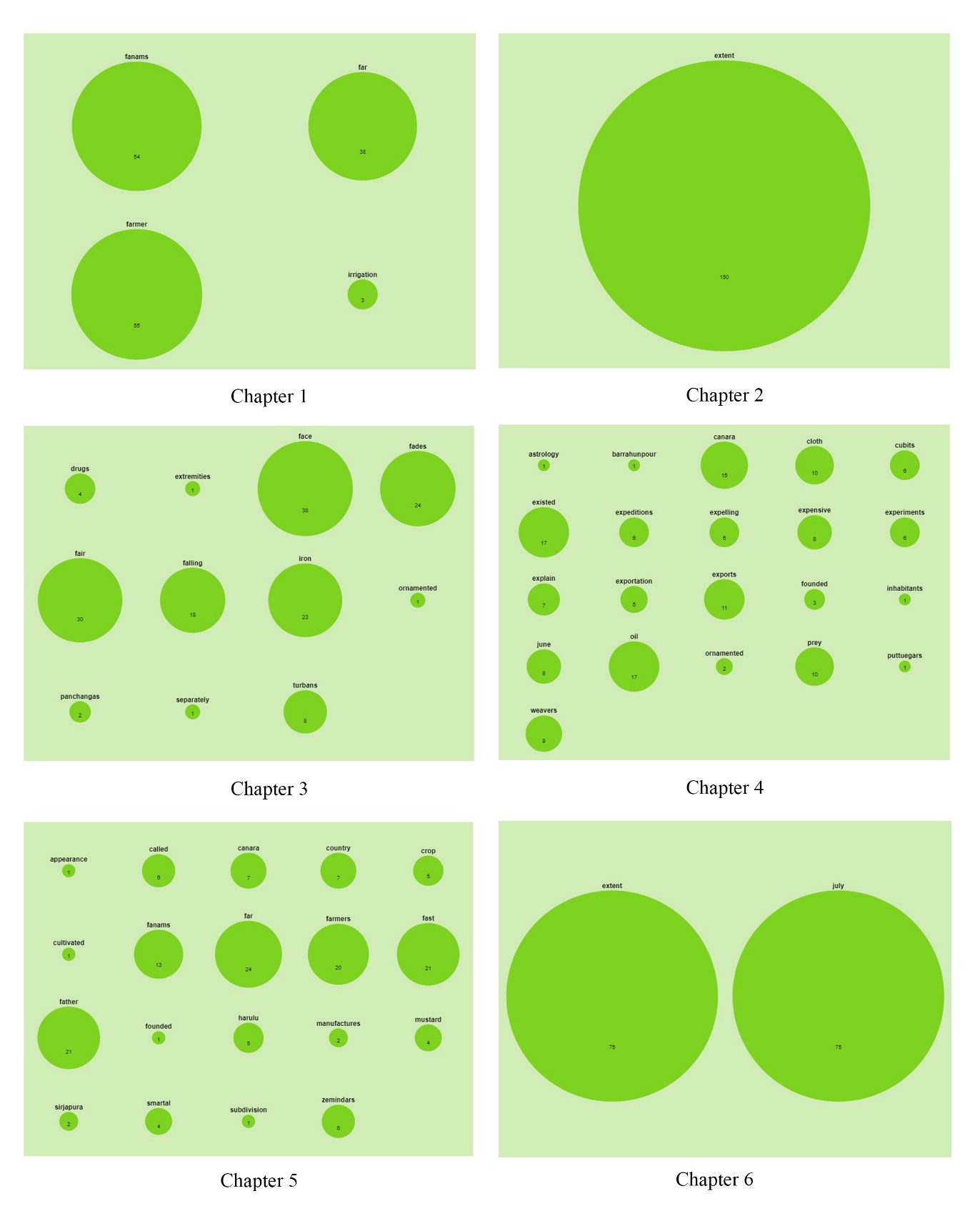
Drugs. A kind of drug merchants at Bangalore, called Gandhaki, trade to a considerable extent. Some of them are Banijigaru, and others are Ladaru, a kind of Mussulmans. They procure the medicinal plants of the country by means of a set of people called Pacanat Jogalu, who have huts in the woods, and, for leave to collect the drugs, pay a small rent to the Gaudas of the villages. They bring the drugs hither in small caravans of tea or twelve oxen, and sell them to the Gandhaki, who retail them. None of them are exported. [Buchanan 1807, 204]
Iron forges. About two miles from Naiekan Eray, a torrent, in the rainy season, brings down from the hills a quantity of iron ore in the form of black sand, which in the dry season is smelted. The operation is performed by Malawanlu, the Telinga name for the cast called Parriar by the natives of Madras. Each forge pays a certain quantity of iron for permission to carry on the work. [Buchanan 1807]
Disadvantages, challenges and future work
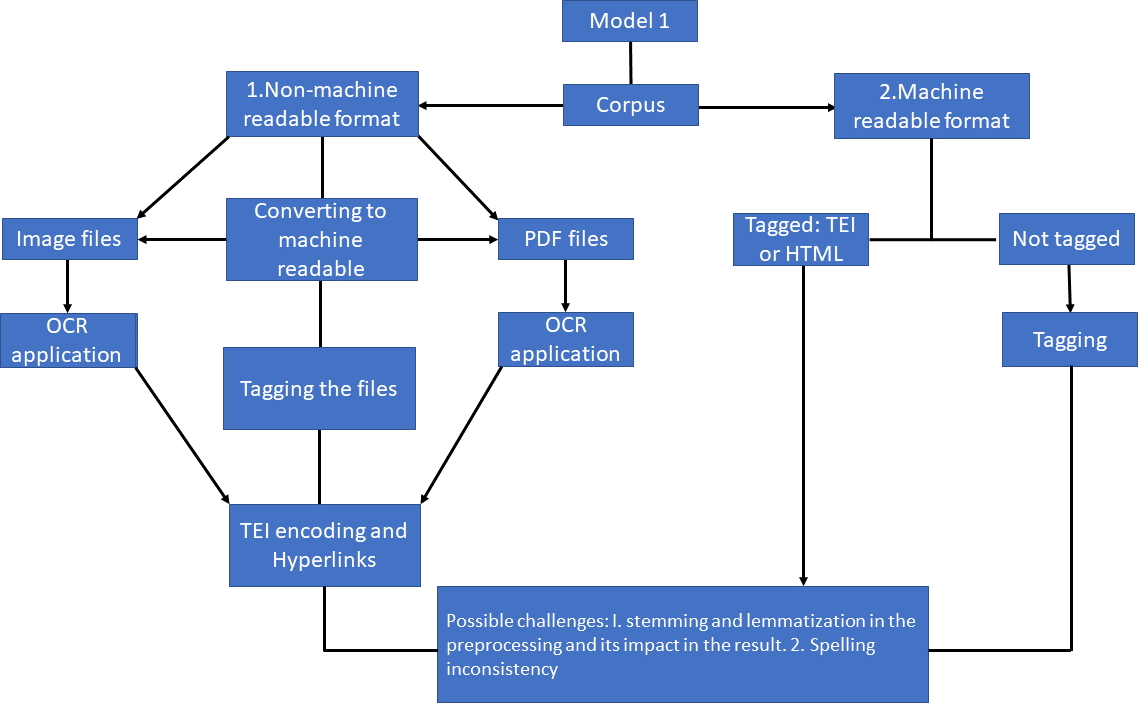
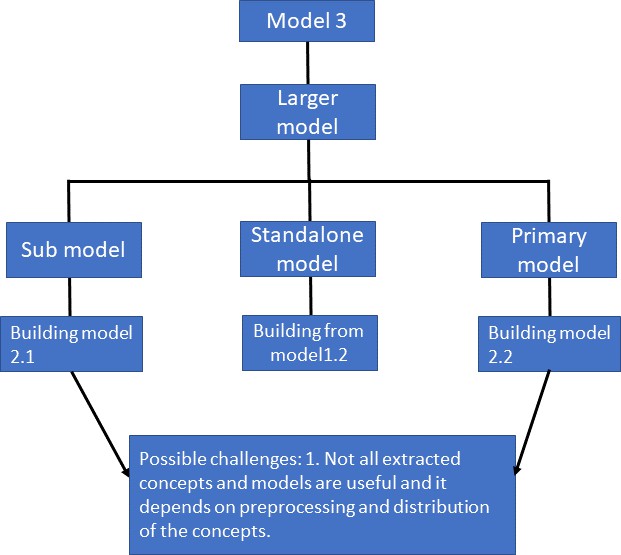
5. Metamodel for concept-based corpus building
6. Conclusion
- Quantitative studies in DH typically prioritize the identification of trend patterns within a corpus. However, the computational approach proposed in this work assigns equal importance to both trend and non-trend patterns in the text, as the latter also significantly contributes to shaping the overall trend pattern. This stands in contrast to traditional approaches to studying historical concepts, which often rely on limited texts through qualitative studies or use computational methods to identify broader conceptual patterns. The recommended model enables a comprehensive study of concepts, even within extensive datasets.
- Additionally, the concept-based model emerges as a convincing and promising framework, not only illustrating how concepts are distributed across the text and its headings but also capable of formalizing nuanced concepts to construct a more comprehensive model. The construction of the concept involves studying exemplars and their associated terms, underscoring the significance of domain knowledge in the decision-making process. Nevertheless, this model introduces a novel computational approach to trace concepts and provides insight into the curation of colonial knowledge.
- The application of the theoretical framework, as outlined in Section 2, is highly effective in exploring the chosen corpus. This model proposes to categorize the text into two types: the text itself and the units of the text based on its peritext. The development of formal models can be accomplished using this categorization. However, as mentioned in Section 3, some challenges arose in these divisions, as a few texts could not be segmented into units due to the absence of peritext. Nevertheless, these challenges were addressed by manipulating the formal models to extract units based on categorization within the text (headings).
- The analysis in Section 4 reveals that the number of models between sub-models and primary models may vary based on the distribution of concepts within the unit and the text. The examination of the extracted models from the chosen text underscores the significance of the sub-model in deriving nuanced concepts from the text, which are overlooked in the primary model and vice versa. However, in the process of constructing and studying the corpus for topic-specific research, both models are indispensable and can mutually enhance exploration of the concepts within the text, aligning with the primary objective of this proposed model.
- Lastly, Section 5 delineates the metamodels, a facet not prioritized in theoretical DH. Derived from the experiment, it provides insights into the general properties, possibilities, and challenges involved in studying a similar corpus.
- The current corpus is relatively modest in size. In subsequent work, an expansion of the corpus by curating additional texts is planned and the texts will be categorized based on its forms and genres, including documents, surveys, and reports. Moreover, the adoption of TEI guidelines to generate tags for the texts will be considered. Systematic categorization and tagging systems aim to enhance the formalization process.
- While the APA computational algorithm demonstrates efficacy for the proposed model, there are limitations in the exemplar features and clustering patterns, notably a surge in outliers, and not all exemplars convey meaningful insights. Future investigations will explore alternative advanced computational models or combinations thereof to achieve more efficient pattern clustering. Additionally, efforts will be made to fine-tune parameters for extracting more than one exemplar per cluster based on content density.
- The next research focus involves formalizing the spelling of Indian names. As highlighted in the final subsection of Section 4, a considerable number of Indian names did not appear in the cluster due to inconsistencies in their spellings. Ongoing efforts are dedicated to addressing this issue, with a specific emphasis on formalizing concepts based on Indian names [Shanmugapriya 2023].
Acknowledgements
Notes
Works Cited

Comments: dhqinfo@digitalhumanities.org
Published by: The Alliance of Digital Humanities Organizations and The Association for Computers and the Humanities
Affiliated with: Digital Scholarship in the Humanities
DHQ has been made possible in part by the National Endowment for the Humanities.
Copyright © 2005 -

Unless otherwise noted, the DHQ web site and all DHQ published content are published under a Creative Commons Attribution-NoDerivatives 4.0 International License. Individual articles may carry a more permissive license, as described in the footer for the individual article, and in the article’s metadata.
