


Volume 17 Number 2
Tool criticism in practice. On methods, tools and aims of computational literary studies
Abstract
This paper is a case-driven contribution to the discussion on the method-theory relationship in practices within the field of Computational Literary Studies (CLS). Progress in this field dedicated to the computational analysis of literary texts has long revolved around the new, digital tools: tools, as computational devices for analysis, have had here a comparatively strong status as research entities of their own, while their ontological status has remained unclear to the day. As a rule, they have widely been imported from the fields of data science and NLP, while less often being hand-tailored to specific tasks within interdisciplinary settings. Although studies within CLS are evolving to both a higher degree of specialization in method (going beyond the limitations of out-of-the-box tools) and a stronger theoretical modeling, the technological dimension remains a defining factor. An unreflective adoption of technology in the shape of tools can compromise the plausibility and the reproducibility of the results produced using these tools.
Our paper presents a multi-faceted intervention to the discussion around tools, methods, and the research questions that are answered with them. It presents research perspectives first conceived at the ADHO SIG-DLS workshop Anatomy of tools: A closer look at textual DH methodologies that took place in Utrecht in July 2019. At that event, the authors discussed selected case studies to address tool criticism from several angles. Our goal was to leverage a tool-critical perspective, in order to “take stock, reflect upon and critically comment upon our own practices” within CLS.
We identified Textométrie, Stylometry, and Semantic Text Mining as three central types of hands-on CLS. For each of these sub-fields, we asked: What are our tools and methods-in-use? What are the implications of using a tool-oriented perspective as opposed to a methodology-oriented one? How do either relate to research questions and theory? These questions were explored by case-studies on an exemplary basis.
The unifying perspective of this paper is an applied tool criticism – a critical inquiry leveraged towards crucial dimensions of CLS practices. Here we re-compose the original oral papers and add entirely new sections to it, to create a useful overview of the issue through a combination of perspectives. While we elaborated the thematic connections between the individual case studies, we hope the interactive spirit of an exemplary exchange remains palpable: individual research perspectives shape the case studies reported for Textométrie, Stylometry and Semantic Text Mining, are complemented by further studies showcasing CLS-specific perspectives on replicability and domain-specific research, and a short section discussing a tool inventory as a practical, community-based incarnation of tool criticism.
The article reflects thus a rich array of perspectives on tool criticism, including the complementary perspective of tool defense – arguing that we need tools and methods as a basic common ground on how to carry out fundamental operations of analysis and interpretation within a community.
0. Preliminaries
At the most basic level, in the present paper, a tool is a computational device used for carrying out “analyses”. This potentially includes aids for diverse sub-processes such as data collection, data pre-processing, annotation and indexing, as well as “analyses proper”, which may or may not involve frequency counts, algorithmic and statistical modeling, or visualization. A tool is here thus understood as a type of methodological vehicle used for contributing to the pursuit of a particular research goal on some aspect of literary discourse treated as data. In the context of CLS, a tool digitally retrieves, and/or represents, and/or operates upon and/or manipulates literary data,[4] which principally includes annotations and metadata.[5] This includes for instance text analysis tools such as Voyant, program libraries for R or Python, as well as general-purpose tools such as Excel spreadsheets or visualization tools.
By contrast to a method, a tool is further defined by its typically reified and closed character. As a computational implementation of a method, it exists as a distinctive entity with a limited set of functions. A tool often includes a graphical user interface (GUI), which makes it also phenomenologically perceived as a particular device rather than a potentially adaptable set of conditions. Another relevant dimension of tools is its transformative power, as emphasized by Weizenbaum and others: “[T]he tool is much more than a mere device: It is an agent for change” [Weizenbaum 1984, p. 18]. If a tool is successful, which means widely and conventionally used in order to carry out a task, this change does not only happen at the level of the method of doing something, but potentially also extends to the object to which method is applied. The object is then co-constructed by the method – which in turn has effects on the scholarly subject using the tool, for example, on their epistemological framework.[6]
Introduction
As the role of digital tools in these [sic!] type of studies grows, it is important that scholars are aware of the limitations of these tools, especially when these limitations might bias the outcome of the answers to their specific research questions. While this potential bias is sometimes acknowledged as an issue, it is rarely discussed in detail, quantified or otherwise made explicit. On the other hand, computer scientists (CS) and most tool developers tend to aim for generic methods that are highly generalisable, with a preference for tools that are applicable to a wide range of research questions. As such, they are typically not able to predict the performance of their tools and methods in a very specific context. This is often the point where the discussion stops. [Traub and van Ossenbruggen 2015]
2. Three Methodological Schools within CLS
2.1 Textométrie: Applying a general tool to a specific research question
- If style is conceived of as a dynamic factor, how may Apollinaire's heterogeneous poetry be analyzed textometrically as a homogeneous unit?
- How may the evolution of Apollinaire's style be textometrically traced over the years?
- Can we textometrically re-assess value judgments predominantly based on thematic aspects?
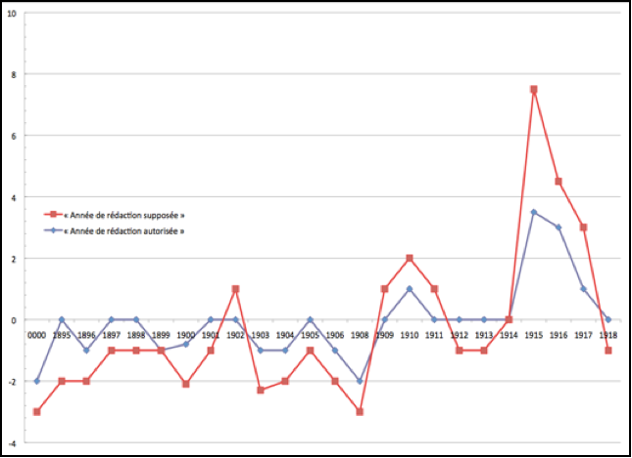
2.2 Word Frequencies in Stylometry
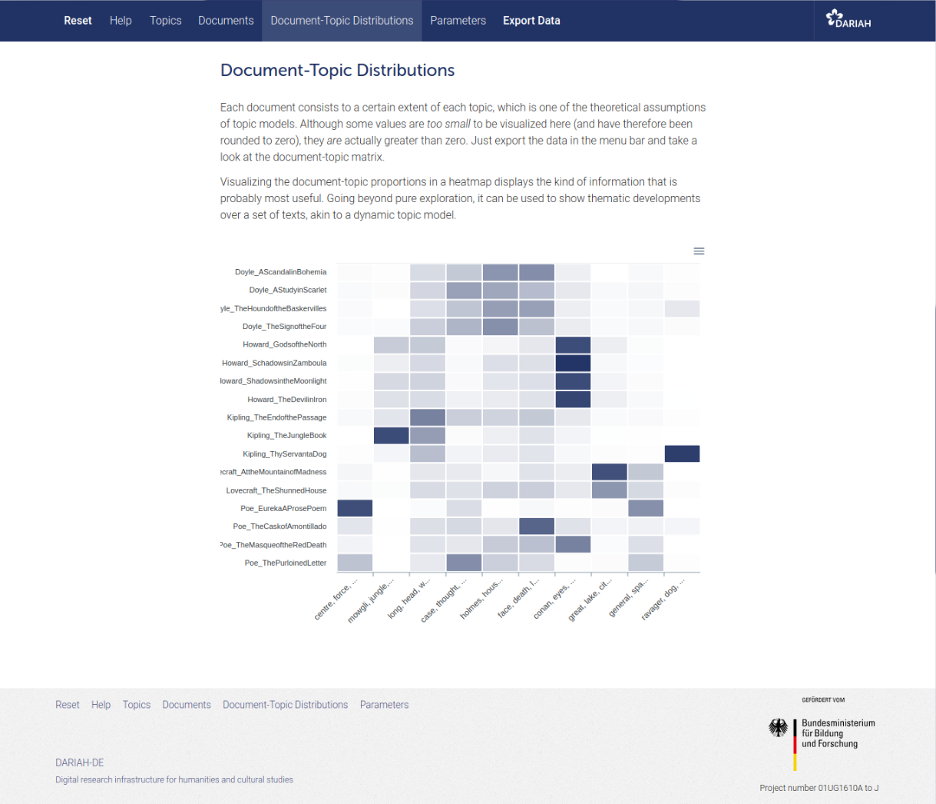
2.3 Semantic Text Mining
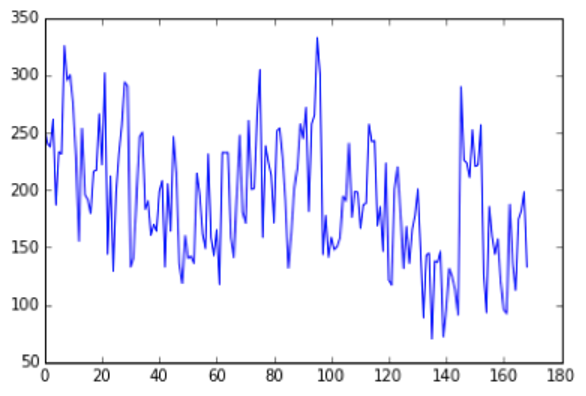
3. Recapitulation, Replication, Reanalysis, Repetition, or Revivication
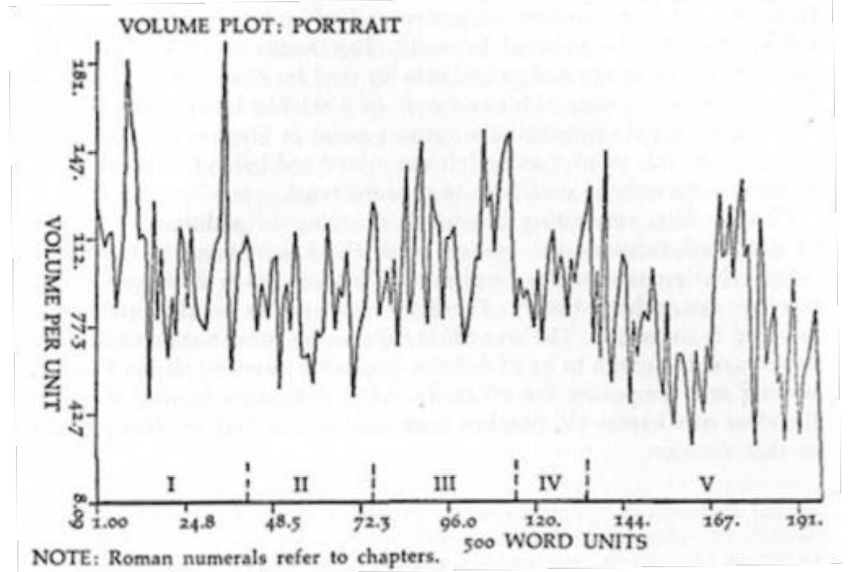
- Talk about Smith's visualization and how it was brought back to life,
- Show some examples of experiments in revivification of techniques, and
- Reflect on what the practice might be doing and what we might call it.
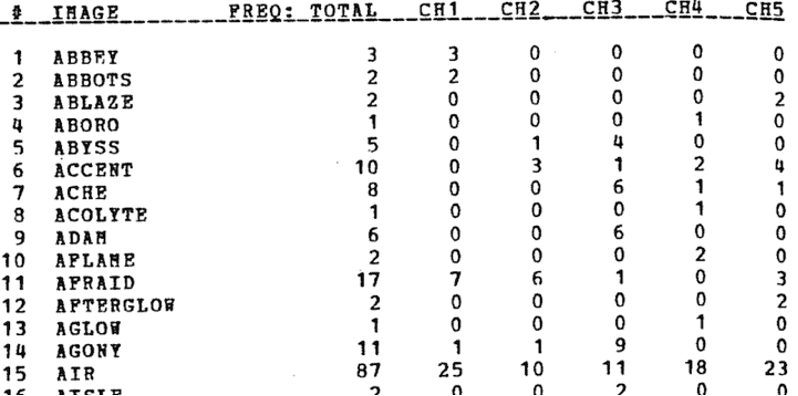
Part of the reason instruments have largely escaped the notice of scholars and others interested in our modern techno-scientific culture is language, or rather its lack. Instruments are developed and used in a context where mathematical, scientific, and ordinary language is neither the exclusive vehicle of communication nor, in many cases, the primary vehicle of communication. Instruments are crafted artifacts, and visual and tactile thinking and communication are central to their development and use. [Baird 2004, XV]
- Lack of clear aims
- Insufficient detail on materials and methods
- Compromises over authentic materials
- Inappropriate parameters
- Lack of academic context
4. Domain Specificity. The Example of Plotting Poetry
5. The Digital Literary Stylistics-Tool Inventory (DLS-TI)
- it is based on bottom up contributions of descriptions by researchers;
- it is intended to be use-case-oriented; the idea is not just to collect lists of tools but concrete real-world usage; crucially we aim to collect contributions which do not come from the developers of the tool;
- it relies on a simple method of collection and a limited set of descriptors, aimed at identifying the name and type of tool, including with reference to the TaDiRAH ontology, and the type of use in real DH scenarios such as published research, such as papers, books, blog posts, but also projects, or academic courses.
6. Conclusions. The many facets of tool criticism
Notes
Works Cited

Comments: dhqinfo@digitalhumanities.org
Published by: The Alliance of Digital Humanities Organizations and The Association for Computers and the Humanities
Affiliated with: Digital Scholarship in the Humanities
DHQ has been made possible in part by the National Endowment for the Humanities.
Copyright © 2005 -

Unless otherwise noted, the DHQ web site and all DHQ published content are published under a Creative Commons Attribution-NoDerivatives 4.0 International License. Individual articles may carry a more permissive license, as described in the footer for the individual article, and in the article’s metadata.
