


Volume 17 Number 2
Automatic Identification of Rhetorical Elements in classical Arabic Poetry
Abstract
A novel, rule-based, automatic framework for identifying rhetorical elements in classical Arabic poetry is described. Since rule-based approaches have well-known limitations, it is proposed as an interim solution until a sufficient quantity of annotated text has been amassed with which to train a machine-learning algorithm. The manual process of identifying rhetorical features in classical Arabic poetry is both time-consuming and requires high-level expertise in Arabic literature. Hence, an automatic recognition system will solve this challenge. Automatic identification is, however, challenging, mainly because there is no existing annotated corpus with which to train a machine-learning-based classifier. The framework proposed here combines natural language-processing techniques with a rule-based reasoning approach, and will continually improve as more examples become available. It is intended as an initial step toward building the essential annotated corpus. Its focus is 20 rhetorical elements, all of importance according to classical Arabic rhetoricians, and it achieves the extremely encouraging result of an overall F-measure of 0.902.
1. Introduction
- Most discuss badīʿ in separate and randomly chosen verses rather than in complete poems. Considering this style in complete poems gives a far more accurate picture of the nature of badīʿ in classical Arabic poetry.
- Since the main hypothesis of modern research (and of classical scholars) is that badīʿ is more important in ʿAbbāsid than in the pre-Islamic era, modern studies focus on the badīʿ of this poetry in the later period.
2. Background and Related Work
<imobiyriyAliy~_1; a;0;0.125;50; NIL;02746897; NIL zrAEap_1; n;0;0;100;100861982;00916464; ziraAoEap_n1AR
3. Features of classical Arabic Poems
ولا عيب فيهم غير أن سيوفهم - بهن فلول من قراع الكتائبThere is no fault in them, excepting that their swords
have suffered dents in clashes with battalions
- 1. Simile (تشبيه): comparing directly two objects; indicating that A is similar to B.
- We have divided the following eight elements (nos. 2.1, 2.2, 2.3, 3.1, 3.2, 3.3, 4, 5) into four main groups(nos. 2–5), according to the identification method:
- 2. Repetition1 (تكرار1),
comprising three minor elements:
- 2.1. Repetition (تكرار): repeating the same word/s at least twice in the same verse while preserving the same meaning and the same grammatical structure and context (such as “we are here; we are here”).
- 2.2 Ploce (ترديد): repeating the same word at least twice in the same verse; having the same meaning, but with a different grammatical structure/context (such as “we are here; they are here ”).
- 2.3. Perfect Paronomasia/Perfect Pun; also Complete Paronomasia (جناس تامّ): Two words that are repeated in the same verse, each having a different meaning. The different meaning is a main difference between repetition and paronomasia.
- 3. Repetition2 (تكرار 2),
comprising three minor elements:
- 3.1. Extraction/Etymology (اشتقاق): Mentioning a personal name and another verb derived from this name — such as Ṣāliḥ (personal name) and ṣaluḥa (“becoming good”).
- 3.2. Semblance (مشاكلة): A word is used in a certain, actual (often non-metaphoric) sense; it is then repeated in another, non-actual (often metaphoric) sense within the same verse (such as “we breathe the fresh air outside; while you remain in your room breathing the data from your books”).
- 3.3. Free paronomasia (جناس مطلق): two words mentioned in the same verse, derived from the same root, or they look as if they have derived from the same root, and they have different meanings (such as fiḍḍa (“silver”) and faḍāʾ (“space”).
- 4. Repetition3 (3تكرار), echoing the rhyme at the beginning of the line (رد الاعجاز على الصدور): the final word in a verse is repeated (with the same meaning or with different meanings; with the same form or in a derivative form) anywhere in the first hemistich of the same verse or as the first word in the second hemistich such as (A....//....A; or ..../A....A).
- 5. Repetition4, key words (كلمات مفتاح): a root that is repeated in more than one verse in the same poem.
- 6. Flowing (اطّراد): praising a person by noting the names of his father and grandfather/s. The word ibn (“the son of”) separates the names (“A is the son of B the son of C....”).
- 7. Afterthought/Retraction (رجوع): mentioning one thought, then negating it in the same verse (“the abodes have not been changed through ages. Nay, I see that they have been totally demolished”).
- 8. Catchword Verbal (تشابه الأطراف اللفظي): A verse opens with the same rhyming word which closed the previous verse ((1) A…. B; (2)B….C; (3)C….D).
- 9. Distribution Characters/Alliteration (توزيع)
- 9.1. Distribution Characters/Alliteration 1 (توزيع 1): a single vowel or consonant is included in each word of a given verse.
- 9.2. Distribution Characters/Alliteration 2 (توزيع 2): a certain vowel or consonant is repeated in all or most words of an entire poem.
- 10. Hemming (تصريع): the two hemistiches of a given verse end with the same rhyming letters.
- 11. Unraveling (توشيع): the verse ends with a general word in the dual form, followed by two single words that specify the two objects constituting this duality (“I am suffering from two different situations: fear and hope”).
- 12. Counterchange (عكس, تبديل): two or more words appear in a certain order and are repeated in the same verse in reverse order (AB...BA).
- 13. Repartee (مراجعة): a conversation between different persons/objects in the same verse or in several verses in the same poem (He said.... I replied....).
- 14. Rhyming – in general – homoeoteleuton (سجع), dividing discourse into periods with similar-sounding last
syllables. It is said to be:
- 14.1. Congruent (مُوازَن): the verse includes several phrases; their final words agree in measure and rhyme.
- 14.2. Terminal (مُطَرَّف): as in 14.1, but with the final words agreeing in measure only.
- 14.3. Tucking (تشطير): each of the two hemistiches in a verse is divided into two phrases that share the same rhyming letters. The rhyming letters in the phrases of the second hemistich differ from those in the first (A..A // B..B).
- 14.4. Embroidery (ترصيع): each word in the first hemistich shares the same rhyming letter (and sometimes the same measure) with its equivalent word in the second hemistich (ABCD//ABCD).
- 15. Verbal Congruence (مناسبة لفظيّة): the second hemistich includes a phrase that rhymes with an equivalent phrase in the first hemistich. The two phrases often open the two hemistiches.
- 16. Paronomasia/Pun (جناس), using
or suggesting in a single verse words that differ in meaning but are phonetically
and/or graphically alike or almost alike.
- 16.1. Conjunct Paronomasia (جناس مركب - مَرْفُوّ): the paronomasia consists of two parts: a single word (the first part) and two words (the second part) which, when combined, are similar phonetically and graphically to the first part of the paronomasia (amradā (“beardless”) and am radā (“or a death?”).
- 16.2. Tipped Paronomasia (جناس ناقص - مُطَرَّف): one of the matching words of the paronomasia is longer than the other with at least one initial consonant (badā “appear” and abadā “ever”).
- 16.3. Tailed Paronomasia (جناس ناقص - مُذيَّل): one of the matching words of the paronomasia is longer than the other with at least one ending consonant (qanā “lances” and qabābil “squadrons of horses”).
- 16.4. Consonantal/Distorted Paronomasia (جناس محرف): the two matching words differ only in their vocalisation (and of course their meaning) (ʿabra “a tear” and ʿibra “a lesson”).
- 16.5. Substitutive or Variant Paronomasia (جناس التصريف): the two matching words have a single differing consonant (ilḥāḥ “insistence” and ilḥāf “importuning”).
- 16.6. Metathetic/Reverse Paronomasia (جناس مقلوب): all or some of the letters of one of the two matching words is in reverse order (sāqin “cup-bearer” and qāsin “cruel”).
- 16.7. Graphic Paronomasia (جناس تصحيف): The two matching words, when written, are shaped alike, differing only in their dots which, in the Arabic script, differentiates some letters from others (ḥabs حَبس “to restrain” and jins جِنس “type”).
- 17. Negative Antithesis (طباق سلب): a word is introduced and then negated with a negation particle (“A” and “not A” (“I know” and “I do not know”)).
- 18. Positive Antithesis (طباق إيجاب): two different words that have contrary meanings (“new” and “old”).
- 19. The Satirist’s Feint (تأكيد الذّم بما يشبه المدح): Criticising an attribute in an individual, then exempting this by alluding that a positive attribute will be noted. The poet, however, disappoints expectations by referring to another negative feature rather than a positive (“he has no good attribute, except of being the worst person in universe”).
- 20. The Encomiast’s Feint (تأكيد المدح بما يشبه الذّم): praising an attribute in an individual, then exempting this, alluding that a negative attribute will follow. Here too, expectation is disappointed with another positive feature, instead of the expected negative (“they have no fault, except their swords which they broke on the heads of their enemies”).
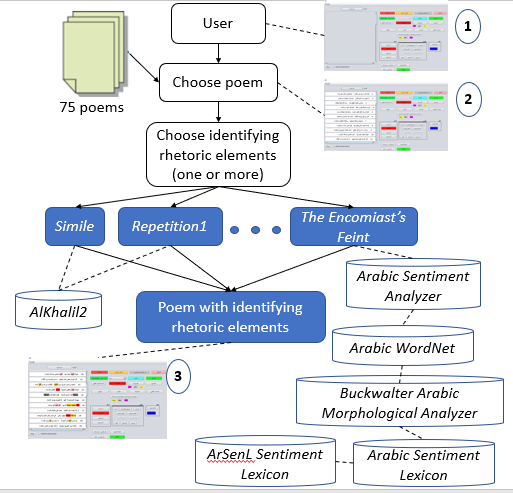
4. Tools and Methods
i. Poems Dataset
ii. NLP Tools and Data Sources
- AlKhalil2, The AlKhalil2 [Boudchiche et al. 2017] was chosen because of its large database and because it is a morpho-syntactic analyzer of standard Arabic words out of context. The system analyses either partially or totally vowelized words. We used their morphological features, including prefix, stem and type of word, all of which are very useful in identifying most of the rhetorical elements. It is important to note, however, that AlKhalil2 was designed for modern Arabic whereas the classical Arabic poetry with which we worked differs from modern Arabic. As a first step, we report on evaluating it on our corpus and then discuss its implications.
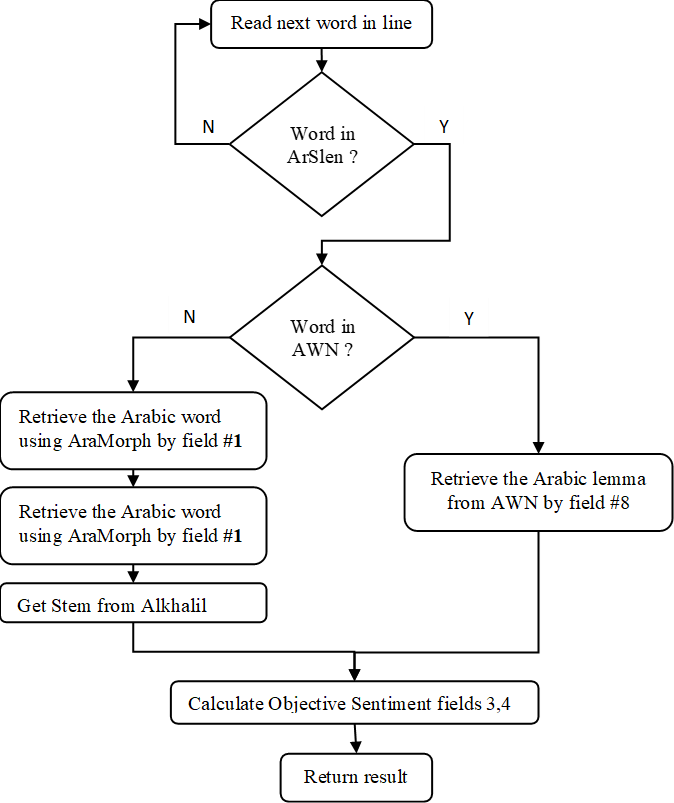
- ArSenL Sentiment Lexicon, The ArSenL [Badaro et al. 2014] was selected for its large sentiment lexicon (154,396 entries). They comprise the eight fields shown in our background section — positive sentiment score (3), negative sentiment score (4) and AWN lemma (8). When the AWN lemma includes NIL (i.e., not in language), we interpreted the morphological word in the first field according to the Buckwalter Arabic Morphological Analyzer [Buckwalter 2002b] to retrieve the Arabic word-form. Where the field AWN lemma included a valid offset (i.e., not NIL), we retrieved the Arabic word from AWN [Al-Khaṭīb 2003]. The final step was calculating the objective score of each word, which is the sum of the fields of positive and negative sentiment scores. It should be noted that most words scored neutral.
- Arabic WordNet. We used the AWN source code to retrieve Arabic words from sentiment lexicons (described below).
- Buckwalter Arabic Morphological Analyzer [Buckwalter 2002b] helped build a sentiment lexicon (tool 2), because entries in ArSenL [Badaro et al. 2014] contain fields that include NIL. This tool was used to convert Morphologic Arabic words to Arabic words (e.g., <imobiyriyAliy~ to إمبيريالي).
- Arabic Sentiment Lexicon. We developed an Arabic sentiment lexicon, comprising 8,765 positive words and 9,813 negative words, in three phases. The first phase involved automatically retrieving Arabic words and their sentimental polarities from ArSenL [Badaro et al. 2014], using the Buckwalter Arabic Morphological Analyzer [Buckwalter 2002b] and AWN [Elkateb et al. 2006]. The second phase manually retrieved Arabic words and their polarities from another lexicon [ElSahar and El-Beltagy 2015], and the final phase was manually enriching the lexicon with Arabic words and their polarities from the internet.[5]
-
Arabic Sentiment Analyser. We developed a word
polarity-based Arabic Sentiment Analyzer using the lexicon described above (see
Figure 7).
- Step 1 was building a lexicon of sentiment words. It comprised two text files — the first file consisting of positive words, the second of negative. In addition, we manually created a text file of negative words.
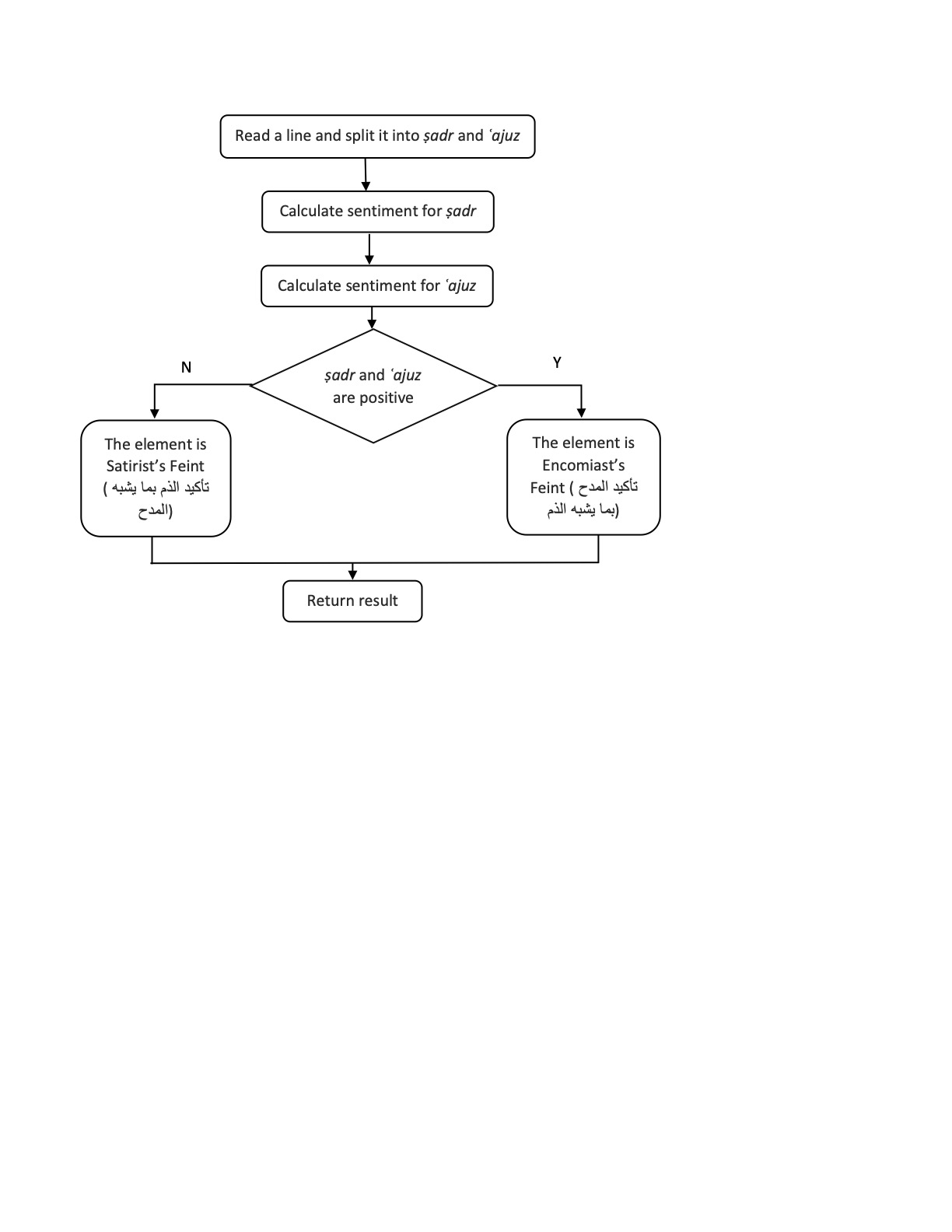
- Step 2 was building an Arabic Sentiment Analyzer based on polarity. Text verses were inputted, each verse devoted to one word in all its possible forms. (All words in each verse appear without diacritics because the lexicon includes words without diacritics.) The analyzer checks each word in the verses. Should it appear in one of the lexicons, its polarity value is set according to that lexicon. If, however, there is a negation particle before the word (in Arabic, they are mainly بلى, ليس, لكن,لم، لا، لن), its polarity is assigned the opposite value of the lexicon. The analyzer then calculates the final sentiment of the input: if the number of positive words is greater than that of negative words, the analyzer returns a value of 1; if negative words comprise the greater number, it returns -1; where they are equal, it returns 0 (i.e., neutral). This serves to identify the Satirist’s and Encomiast’s Feints (see Figure 6).
- Arabic Lexicon for Antithesis. We developed an Arabic lexicon for words with contradictory meanings. It comprises 453 pairs of opposites, compiled in two stages. First was retrieving English words and their opposites from the internet ([Englisch-hilfen.de n.d.] [Perfectyourenglish.com 2019]), and using the AWN Browser 2.0.1 to get their Arabic opposites and synonyms. Second was manually enriching these opposites with Arabic words and their synonyms [Al-Jāhiẓ 2019].
- Graphical User Interface (GUI) (see Figures 2 and 4).
iii. Rhetoric Elements Identification Framework and Prototype
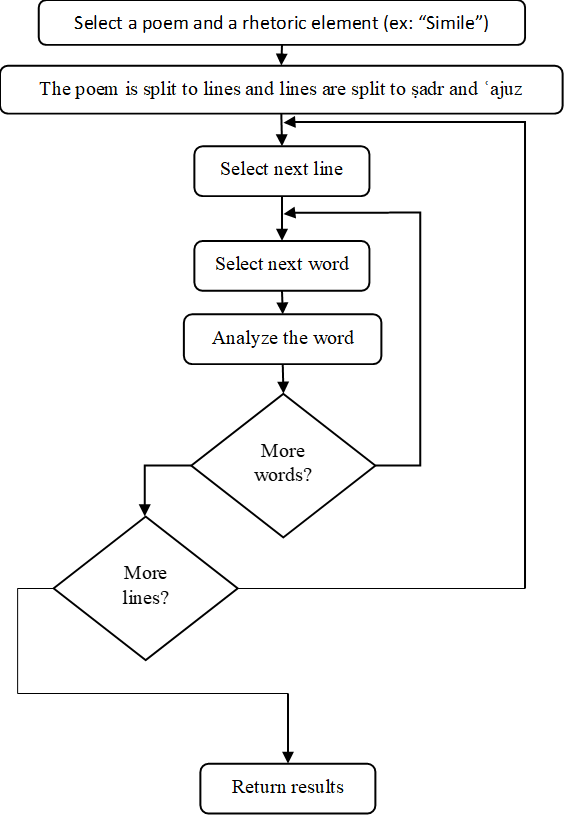
- Activate the system (1), and select a poem (2).
- Select a rhetorical element from the 20 in the GUI.
- Run the tools to identify the selected element for each verse. If more than one element is chosen, repeat the process for each
- The color-coded results are visualized (3).
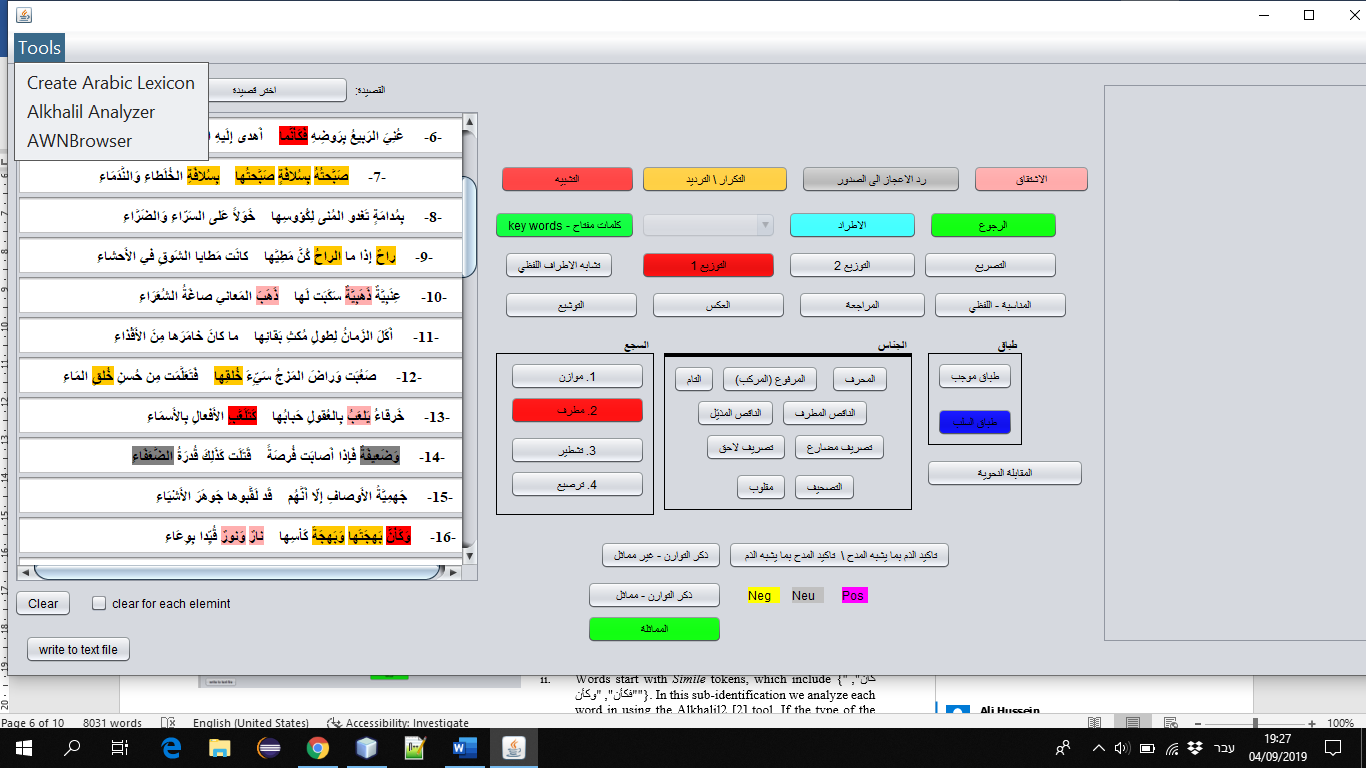
iv. Identifying Rhetorical Elements (Rules)
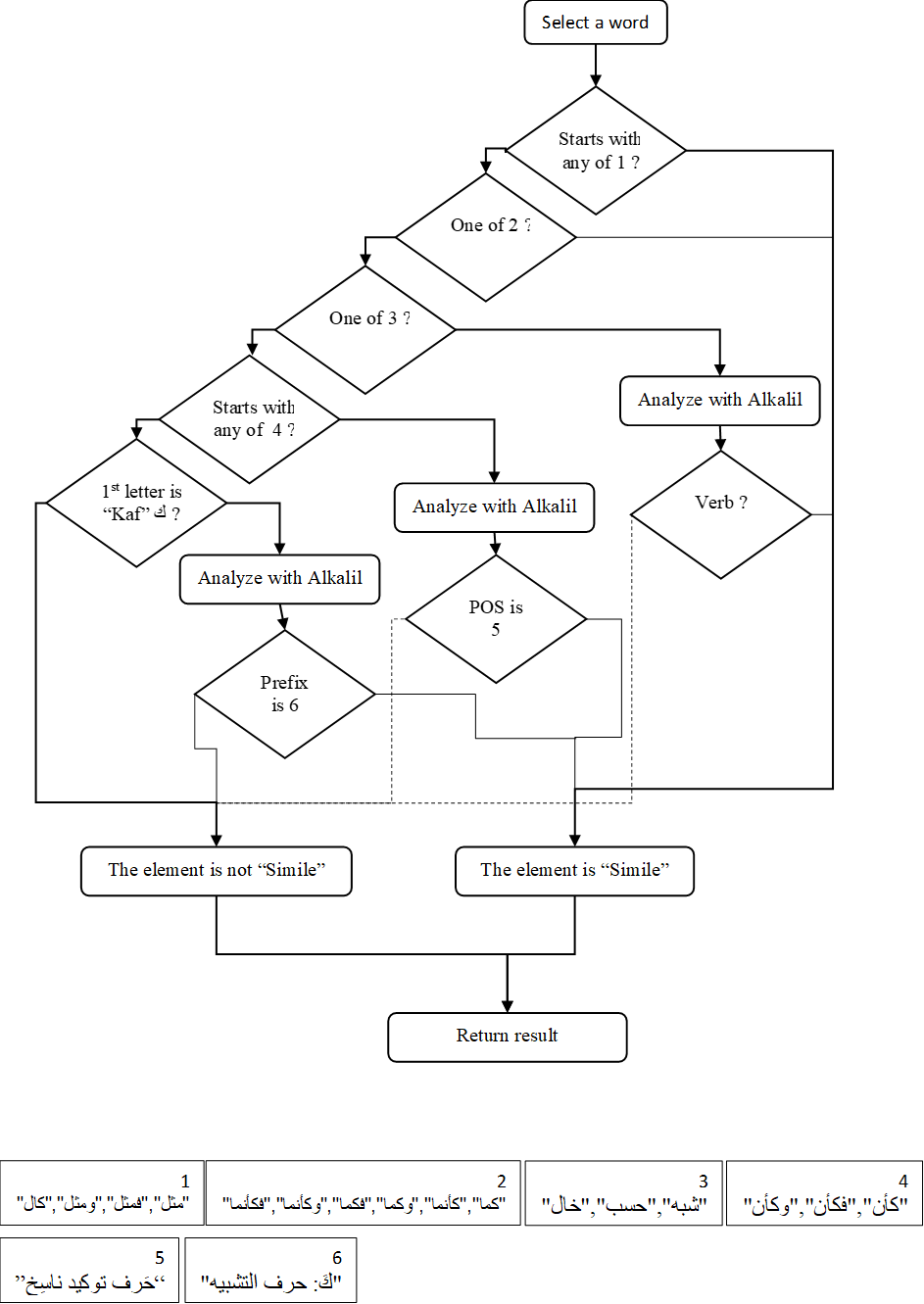
- 1. Simile (تشبيه). This can appear with and without word tokens. The
latter is not included in our system. This rhetorical element is identified
in two steps. The first identifies it by full word tokens in one of four
groups (see also Figure 5): The second step is identifying similes by the letter k- كـ. Each word is analyzed using AlKhalil2 [Boudchiche et al. 2017] to check whether it is a prefix. If the prefix is equal to كَ: حرف التشبيه, it is a Simile.
- 1.1. Words starting with the tokens مثل, فمثل, ومثل ,كالـ for which the system searches.
- 1.2. Words starting with the simile tokens كأن, فكأن ,وكأن. Each word is analyzed using the AlKhalil2 [Boudchiche et al. 2017] tool. If the type of the word is a حرف مشبّه بالفعل (particle that resembles the verb; a group of particles including إن – أن / كأن – لكن / ليت – لعل) and the word is one of the three tokens mentioned above, it is considered a simile.
- 1.3. All word tokens كما, كأنما, وكما, فكما, وكأنما فكأنما. The system searches for whole tokens. For each, vocalization (تشكيل) is removed, and it is then checked as to whether it is equal to one of the tokens. Where a match is found, it is a simile.
- 1.4. Verb tokens ظن, خال, حسب, شبه are analyzed using the AlKhalil2 [Boudchiche et al. 2017] tool to retrieve type and root. If its type is a verb and its root is equal to one of the tokens, it is a simile.
- 2. Repetition 1-4 (تكرار). These rhetorical elements are identified by two tests. The first is when two identical words appear in the same verse. This is Repetition. The second is finding the same stem in more than one word, with different predefined prefixes. We exclude words of the following types: { حرف جر- preposition, حرف نداء – interjections, حرف عطف – copulative particle, and particles that indicate حرف نصب – accusative, حرف نفي – negation, حرف جزاء – compensation, حرف عطف – disjunctive, and حرف جزم – apocopative, أداة شرط - conditional particle}. Such particles are frequently repeated in poetry and are not, therefore, considered part of the text’s rhetorical texture. To exclude these words, we analyze every word in the verse using AlKhalil2 [Boudchiche et al. 2017] to determine its type. Where the type matches one of those mentioned above, the word is excluded. These tests also eliminate words used in the “flowing” “rhetorical element no. 6” identifications. To identify Repetition1-4-type (see Appendix 1) rhetorical elements, contextual association is also needed — for example, Semblance (مشاكله). At this point, however, it is sufficient to recognise repetition of the same word without reference to context.
- 3. The Flowing (اطراد) is when the word بن appears at least twice in the same verse.
- 4. Afterthought/Retraction (رجوع) is when the first word in the second part of the verse matches one of the predefined negation words — وما - “and it is not,” بلى - “yes, it is!,” وغير – “but it is”.
- 5. Catchword Verbal (تشابه الاطراف اللفظي) is when the last word in a verse reappears as the first word of the following verse.
- 6. Distribution Characters/Alliteration (توزيع). Type 1 is when the same consonant appears in all or almost of all words of a given verse. Type 2 is when the same consonant appears in all or most of the verses in the poem. The vowels ا, و, ي are ignored.
- 7. Hemming (تصريع) compares two-word suffixes — the last word in the first and second parts of the verse.
- 8. Unraveling (توشيع) is when the verse ends with a phrase containing a noun in dual form (مثنى), followed by two singular nouns connected with the particles wa or fa (“and”). Each word in the second part of the verse is analyzed with AlKhalil2 [Abdul-Mageed, Diab, and Kübler 2013] to check whether it is dual form.
- 9. Counterchange (عكس وتبديل) is when two sentences are composed of the same words, but in reverse order.
- 10. Repartee (مراجعة) is when two consecutive verses contain a reported conversation. The system finds this by searching for the word “said” and its derivatives.
- 11. Rhyming – in general – homoeoteleuton (سجع) is when the concluding syllables (the end of two parts) in two sentences within the same verse end with the same consonants. Where they sound similar, it is a sajʿ.
- 12. Verbal Congruence (مناسبة لفظيّة) is when the first and second parts of the poem contain individual words in the same locations that resemble one another, either in terms of their suffix (their final letter) or in their metrical pattern, or in both.
- 13. Paronomasia (جناس) comprises seven types that are identified in two phases. First, the prefixes and suffixes of each word are removed, and then the letter, vocalization and type of word-pair are examined.
- 14. Negative Antithesis (طباق سلب) is when two words (the same words or words that are derived from the same root) are repeated, and a negation particle precedes one of them.
- 15. Positive Antithesis (طباق إيجاب) is identified using our Arabic Lexicon of Opposites, which lists words and their opposites. It searches for words and their opposites within the same verse.
- The following two rhetorical elements are based on sentiment analysis. To identify them, we used an Arabic Sentiment Analyser.
- 16. The Satirist’s Feint (تأكيد المدح بما يشبه الذّم) searches each verse for predefined terms — , ان ريغ , أن ريغ ان ىوس , أن ىوس , أن لاإ ,. Where found, the sentiment values of the words that precede and follow the term are calculated separately. When both values are positive, it is a Satirist’s Feint.
- 17. The Encomiast’s Feint (تأكيد الذّم بما يشبه المدح) is calculated as above. When both sentiment values are negative, it is an Encomiast’s Feint.
5. Experiments and Results
i. Dataset
ii. Procedure
iii. Evaluating AlKhalil2
| Poem Details | Number of Words | Correct | Incorrect |
| Imruʾ al-Qays poem no. 8 | 194 | 131 (67.5%) | 63 (32.4%) |
| Al-Aʿshā Maymūn 78 | 224 | 153 (68.3%) | 71 (31.7%) |
| Abū Dulāma (1) | 116 | 84 (72.4%) | 32 (27.6%) |
| Al-Najāshī l-Ḥārithī 41 | 116 | 85 (73.2%) | 31 (26.7%) |
| Jarīr 11 | 195 | 173 (88.7%) | 22 (11.3%) |
| Ibn Qays al-Ruqayyāt 50 | 207 | 135 (65.3%) | 72 (34.7%) |
| Dīk al-Jinn al-Ḥimṣī 38 | 86 | 72 (83.7%) | 14 (16.3%) |
| Al-Namir b. Tawlab 34 | 195 | 156 (79.9%) | 39 (20%) |
| Total | 1,333 | 989 (74.2%) | 344 (25.8%) |
iv. Framework Evaluation Results
| Precision | Recall | F1 | |
| Simile (التشبيه) | 0.916 | 0.891 | 0.904 |
| Repetition1 (التكرار) | 0.962 | 0.838 | 0.896 |
| Repetition2 (الاشتقاق) | 0.902 | 0.925 | 0.913 |
| Repetition3 (رد الاعجاز على الصدور) | 0.941 | 0.941 | 0.941 |
| Repetition4 – Key Words | 1 | 1 | 1 |
| Flowing (الاطراد) | 1 | 1 | 1 |
| Afterthought/ Retraction (الرجوع) | 1 | 1 | 1 |
| Catchword Verbal (تشابه الاطراف لفظي) | 1 | 1 | 1 |
| Distribution Characters/Alliteration 1 (التوزيع) | 1 | 1 | 1 |
| Distribution Characters/Alliteration 2 (توزيع 2) | 1 | 1 | 1 |
| Hemming (تصريع) | 1 | 1 | 1 |
| Unraveling (توشيع) | 1 | 1 | 1 |
| Counterchange (عكس وتبديل) | 1 | 0.8 | 0.889 |
| Repartee (مراجعة) | 1 | 1 | 1 |
| Rhyming – in general – homoeoteleuton (سجع) | 1 | 0.875 | 0.933 |
| Verbal Congruence (مناسبة لفظيّة) | 0.778 | 0.875 | 0.824 |
| Paronomasia (جناس) | 0.857 | 0.75 | 0.8 |
| Negative Antithesis (طباق سلب) | 0.636 | 1 | 0.777 |
| Positive Antithesis (طباق إيجاب) | 0.551 | 0.457 | 0.5 |
|
Satirist’s, Encomiast’s Feint تأكيد الذّم بما يشبه المدح تأكيد المدح بما يشبه الذّم |
0.818 | 0.692 | 0.75 |
| Average | 0.918 | 0.9o2 | 0.906 |
| T-P | F-P | F-N | |
| Simile (التشبيه) | 33 | 3 | 4 |
| Repetition1 (التكرار) | 26 | 1 | 5 |
| Repetition2 (الاشتقاق) | 37 | 4 | 3 |
| Repetition3 (رد الاعجاز على الصدور) | 16 | 1 | 1 |
| Repetition4 – Key Words | 45 | 0 | 0 |
| Flowing (الاطراد) | 3 | 0 | 0 |
| Afterthought/ Retraction (الرجوع) | 5 | 0 | 0 |
| Catchword Verbal (تشابه الاطراف لفظي) | 8 | 0 | 0 |
| Distribution Characters/Alliteration 1 (التوزيع) | 5 | 0 | 0 |
| Distribution Characters/Alliteration 2 (توزيع 2) | 56 | 0 | 0 |
| Hemming (تصريع) | 5 | 0 | 0 |
| Unraveling (توشيع) | 14 | 0 | 0 |
| Counterchange (عكس وتبديل) | 4 | 0 | 1 |
| Repartee (مراجعة) | 7 | 0 | 0 |
| Rhyming – in general – homoeoteleuton (سجع) | 21 | 0 | 3 |
| Verbal Congruence (مناسبة لفظيّة) | 7 | 2 | 1 |
| Paronomasia (جناس) | 18 | 3 | 6 |
| Negative Antithesis (طباق سلب) | 7 | 4 | 0 |
| Positive Antithesis (طباق إيجاب) | 13 | 16 | 19 |
|
Satirist’s, Encomiast’s Feint تأكيد الذّم بما يشبه المدح تأكيد المدح بما يشبه الذّم |
9 | 4 | 2 |
6. Discussion
وَمَا زَالَ مِنْ هَمْدَانَ خَيْلٌ تَدُوسُهُمْ *** سِمَانٌ وَأُخْرَى غَيْرُ جِدّ سِمَانِThe horses of the Hamdān tribe continued to trample upon them. These include both fat and not-fatted horses.
مِكَرٍّ مِفَرٍّ مُقْبِلٍ مُدْبِرٍ مَعًا *** كتيس ظِبَاءِ الْحُلَّبِ الْغَذَوَانِReady to charge, ready to fell, advancing, retreating equally well; [its speed] like [that of] a lively buck-gazelle that feeds upon the ḥullab trees, rock brought down from on high by [a raging] torrent.
7. Conclusion and Future Work
Appendices
Appendix 1: Definitions of the 20 Rhetorical Elements (based mainly on [Cachia 1998])
- 1. Simile (تشبيه)
The indication, by the use of the word “like” (“similar”) or some such word (مثل، كأن، كأنما، كما، كـ، شبه، حسب، خال), whether an object or condition explicitly or implicitly shares an attribute with another. The former object or condition is the tenor or primum compartionis, the latter is the vehicle or secundum comparationis. This is an example from the Syrian poet Abū Tammām (d. 846 C.E.):خَلَطَ الشجاعةَ بالحَيَاء فأصْبَحا ... كالحُسنِ شِيبَ لِمُغْرَمٍ بدلالِ
He mingled bravery (shajāʿa) with reticence (bi-l-ḥayāʾi) so that it seemed like (ka-) beauty (l-ḥusni) joined to coquetry (dalāli) in a lover’s eyes - 2. Repetition1 (تكرار
1)
This comprises two minor rhetorical elements:- 2.1. Repetition (تكرار ) is use of the same word or words, more than once,
in the same form, and with the same meaning and context for the sake of
emphasis in description, praise or another purpose. This example is from
ʿAbd al-Ghanī al-Nābulsī (d. 1731 C.E.):
والجِسْمُ والجسْمُ قدْ أوْدَى السّقامُ بهِ ... والجَفْنُ والجفنُ طولَ اللّيل ما هَجَعا
My body (wa-l-jismu) — My body (wa-l-jismu) is reduced by languor, My eyes (wa-l-jafnu) —my eyes (wa-l-jafnu) have known no sleep all night - 2.2. Ploce (ترديد) uses the same word more than once, each time with a
different application or context (sometimes it is a different grammatical
context; that is, each of the two repeated words is attributed to a
different subject/object/pronoun etc.). This, from Sayf al-Dawla, Emir of
Aleppo (d. 967 CE), describes a slave-girl whom he was sending to a
fortress to protect her from the jealousy of his other favorites:
رُبَّ هَجْرٍ يَكونُ مِنْ خَوْفِ هَجْر وفِراقٍ يكونُ خَوْفَ فِرَاق ...
A break (hajr) may be due to the fear of a break (hajr), And parting (firāq) be caused by the fear of parting (firāq). - 2.3. Perfect Paronomasia/Pun (جناس تامّ; also Complete
Paronomasia) is the use in a single context of two words
pronounced and written exactly alike but carrying different meanings.
This example is from the poet Abū Tammām:
مَا مَاتَ مِنْ كَرَمِ الزَّمَانِ فإنَّهُ ... يَحْيَا لَدَى يَحْيَى بْنِ عَبْدِ الله
All generosity that have perished is still living (yaḥyā) in the court of Yaḥyā the son of Abdallah
- 2.1. Repetition (تكرار ) is use of the same word or words, more than once,
in the same form, and with the same meaning and context for the sake of
emphasis in description, praise or another purpose. This example is from
ʿAbd al-Ghanī al-Nābulsī (d. 1731 C.E.):
- 3. Repetition2 (تكرار2)
This comprises three minor rhetorical elements:- 3.1. Extraction (اشتقاق; also Etymology) draws
from a personal name an idea that serves the poetic motif, satirical,
panegyric, erotic or other. This example, from Abū l-Ḥasan ʿAlī ibn
Muḥammmad al-Anṭākī (d. 988 C.E.), is to a patron called Ṣāliḥ:
يا صالِحَ الخيراتِ ما صَلَحا ... إلا لك التأييدُ والأمْرُ
O Şāliḥ, [the name of the patron], the patron of all bounties, the two virtues of ordering and being obedient befit (ṣalaḥa) only your personality - 3.2. Semblance (مشاكلة) replaces the denotative of an object or action with
another word for reasons of contextual association. An example from Abū
Tammām:
والدّهْرُ ألأَمُ مَنْ شَرِقْتَ بِلَومِهِ ... إلا إذا أشَرَقْتَهُ بكَريمِ
Fate is the vilest of all that chokes you (shariqta) with vileness,
Unless you choke it (ashraqtahu) with [the succour of] a generous man - 3.3. Free Paronomasia (جناس مطلق) uses or suggests in one context
words that differ in meaning but are phonetically and/or graphically
alike or nearly alike — that is, matching words differ in their letters
and vocalisation but have at least two radical consonants in common,
sometimes falsely making them appear derivatives from the same root.
(Sometimes they do derive from the same root). For example:
ذَهَبٌ حَيْثُما ذَهَبْنَا ودُرٌّ ... حيْثُ دُرْنا وفضّةٌ في الفضَاء
ِ Gold (dhahab) wherever we go (dhahabnā), pearls (durr) Wherever we roam (durnā), and silver (fiḑḑa) even in space (fī l-faḍāʾ)
- 3.1. Extraction (اشتقاق; also Etymology) draws
from a personal name an idea that serves the poetic motif, satirical,
panegyric, erotic or other. This example, from Abū l-Ḥasan ʿAlī ibn
Muḥammmad al-Anṭākī (d. 988 C.E.), is to a patron called Ṣāliḥ:
- 4. Repetition3 (تكرار
3)
This echoes the rhyme at the beginning of the line (رد الاعجاز على الصدور). It takes two words — which are identical in pronunciation and meaning, or almost alike in pronunciation but not in meaning, or derived (either genuinely or apparently) from the same root — placing one near the beginning of the discourse and the other at its end. This example is from Ibn al Fāriḍ (d. 1235 C.E.):يا ساكنِي البطْحاء هلْ من زورةٍ ... أحْيا بها يا ساكنِي البطْحاءِ
Desert dwellers (yā sākinī l-baṭḥāʾi), will you not allow one visit That I may live by it, O desert dwellers (yā sākinī l-baṭḥāʾi)? - 5. Repetition4 — Key Words (كلمات مفتاح)
We suggest a new rhetorical element, in which a root is repeated in different verses of the same poem. While this includes Repetition1 and 2 (repetition, ploce, extraction/etymology, semblance and paronomasia), we identify it in all verses of the poem. - 6. Flowing (اطراد)
This features in a single verse the given personal name of the individual praised, as well as the name of his father and grandfather and that of the tribe, all in the appropriate order. This example is from Ibn Durayd al-Azdī (d. 933 C.E.):عِيادُ بْنُ عَمْرو بْنِ الحَلِيسِ بن جابِرِ بْنِ زَيْدِ بْنِ مَنْظُورِ بْنِ زَيْدِ بْنِ وارثِ
ِʿIyād, the son of (bnu) ʿAmr, the son of (bni) al-Ḥalīs, the son of (bni) Jābir, the son of (bni) Zayd, the son of (bni) Manẓūr, the son of (bni) Zayd, the son of (bni) Wārith (the u and the i at the end of the word indicate two different grammatical forms — nominative for the first, and genitive for the second).
- 6. Flowing (اطراد)
- 7. Afterthought (رجوع; also translated as Retraction)
This reverses an earlier statement. The first word in the second part of the verse usually matches one of the predefined words {بل, بلى, ليس, لكن, نعم. لم، لا، لن}. This example is from the pre-Islamic poet Zuhayr ibn Abī Sulmā (d. 609 C.E.):قِفْ بالدِيار التي لم يَعْفُها القِدَمُ ... بَلَى وغَيّرها الأرواحُ والدَّيمُ
Halt by a deserted abode that age has not obliterated (lam yaʿfihā l-qidamu)–
Nay (balā), that winds and rain have altered! - 8. Catchword Verbal (تشابه الأطراف اللفظيّ)
This is of two types. We consider one type only — the verbal — which corresponds to anadiplosis, gradatio, reduplication. It starts each of a succession of verses with the preceding rhyme word, for example, from the poetess Laylā l-Akhyaliyya (d. 700 C.E.):إذا نَزلَ الحجّاجُ أرْضًا مريضةً ... تَتَبَّعَ أقْصَى دائها فشفاها
شَفاها من الدّاءِ العُضال الذي بها ... غُلامٌ إذا هَزٌ القَناةَ سقاها
سَقاها فَرَوّاها بشرْبٍ سِجالُها ... دِماءُ رجالٍ يَحْلِبونَ ضَراها
Whenever al-Ḥajjāj visits a sick land,
He treats its illness and cures it (shafāhā);
It is cured (shafāhā) of its chronic disease
By a warrior who always shakes his spear, and quenches the land’s thirst (saqāhā);
He quenches the land’s thirst (saqāhā) by drinking buckets of the blood of his enemies. - 9. Distribution Characters (توزيع; also Alliteration)
- 9.1 Distribution Characters/Alliteration
1 (توزيع 1)
This distributes to the poet or speaker the same consonant or vowel in every word of a verse. The programme checks for such a letter. This verse is by Ṣafiyy al-Dīn al-Ḥillī (d. 1349 C.E.):محمدُ المُصطَفى المُختارُ مَنْ خُتِمَتْ ... بمجدِهِ مُرْسَلو الرَّحْمَنِ للأُمَمِ
Muhammad the favourite and choices from all His creations.
One who is the last of the messengers of the Merciful God to the nations (the translation lacks starting each word with the m consonant). - 9.2 Distribution Characters/Alliteration
2 (توزيع 2)
This type distributes the same consonant or vowel in every word or most words of the entire poem. The programme checks, and we choose to record how many times the top three letters appear.
- 9.1 Distribution Characters/Alliteration
1 (توزيع 1)
- 10. Hemming (تصريع)
This is when the end of the first hemistich matches the end of the verse in meter and final vowel. The following verse is by Abū Nuwās (d. 814 C.E.)دَعْ عَنْكَ لَوْمِي فأنّ اللَّوْمَ إِغْراءُ ... وَداوِني بالّتي كانَتْ هيَ الدّاءُ
Censure me not, for censure but tempts me (ighrāʾu); cure me rather with the cause of my ill (al-dāʾu). - 11. Unraveling (التوشيع)
This is use of a noun in dual form near the end of the second hemistich, followed by two single words specifying what constitutes this duality, the second being the rhyme word. An example from Mayyās al-Mawṣilī (no date of death is given):أبيتُ في لجَج التّذْكارِ منْكَ وبي ... حالان مخْتَلفانِ اليَأسُ والأمَل
ُ لا يَهتدي لي طيْفٌ مُذْ هجرْتَ ولا ... يَزُورُني المُسلْيان الكُتْبُ والرُّسُلُ
أسائلُ الدّارَ مِنْ وَجْدي عليْكَ فلا ... يُجيبُني المُقْفران الرّبْعُ والطللُ
I spend the night importuned by memories of you, and in me
Are two opposite conditions: despair and hope.
No phantom finds its way to me since you deserted me,
Nor am I visited by the two comforters: letters and messengers.
My passion for you makes me question the site where I have halted, but
I get no answer from either of the two desolate spots: the old encampment and its half-obliterated traces. - 12. Counterchange (عكس
وتبديل)
This is repetition of words in a different order. It is of two kinds: (1) a hemistich is recast to complete the verse without any change in meaning, and (2) a hemistich or part thereof is re-arranged to produce a different meaning.يا بَدَني يا بَدَني بالفِراقِ مُتْ كمدا مُتْ ... كمَداً بالفراقِ
فارَقَني مَنْ أحبُّ واحزَني ... واحزَني مَنْ أحبُ فارَقَني
Body of mine, now we are parted, die of grief!
Die of grief now we are parted, o body of mine!
He has left me, whom I love – O wretchedness!
Wretchedness, he whom I love has left me! - 13. Repartee (مراجعة)
This is a reported conversation, combining pithy expression, subtle ideas, elegant composition, and flowing diction. This example is from the poetry of the Egyptian Ibn Maṭrūḥ (d. 1251 C.E.):سَألتُ مَنْ أمْرَضَني ... في قُبْلَةٍ تشْفي الألْمْ
فقال لا لا أبداً ... قُلتُ له نَعَمْ نَعَمْ
I asked of him who caused my languor for a kiss to ease the pain.
He answered, “No, no, never!” (faqāla: lā lā abadan)
I insisted, “Yes, oh yes!” (qultu lahu: naʿam naʿam) - 14. Rhyming – in general – homoeoteleuton
(سجع)
When the discourse is divided into sections with similar-sounding last syllables, it is said to be:- 14.1. Congruent موازَن when the final words agree in measure as well as in rhyme, or
- 14.2. Terminal
مطرف when they have rhyme but not
measure in common. An example of congruent rhyming from the Qur`ān
88:13-14:
An example of terminal rhyming from al-Waʾwāʾ al-Dimashqī (d. 995 C.E.):فيها سررٌ مرفوعة وأكوابٌ موضوعة
In it are thrones that are raised (marfūʿa), and goblets placed ready (mawḑūʿa).قُمْ يا غُلامُ إلى المُدام ... قُمْ داوِني منِها بِجام
Up, boy! To the wine (al-mudām), Medicate me with a silver goblet (bi-jām) - 14.3. Tucking
تشطير. The division of each hemistich
into rhyming parts, but with different rhymes in each hemistich
(producing the arrangement bbaa, where “a” is the rhyme common to
all verses of the poem). An example from Abū Tammām in praise of the
caliph al- Muʿtaşim bi-llāh (re. 833-842 C.E.), playing on the literal
meaning of the honorific title:
تَدْبيرُ مُعْتَصِم بالله مُنْتقِمٍ ... للهِ مُرْتقبٍ في الله مُرْتغِبٍ
He revenges [his enemies by the help of] God (bi-l-lāhi muntaqimin), and acts while finding refuge in God (tadbīru muʿtaṣimin)
He places his hope in God (fī l-lāhi murtaghibin), waiting to meeting Him (li-lāhi murtaqibin) - 14.4. Embroidery
ترصيع– Making every word in a hemistich
or prose versicle agree in rhyme and possibly in measure, as well as in
grammatical case with the correspondingly placed word in the next
hemistich or versicle [Qurʾān 82: 13]:
إنّ الأبْرارَ لَفي نَعيم, وإنّ الفُجّارَ لَفي جَحيم
The (inna) righteous (abrāra) are in (la-fī) bliss (naʿīmin), and the (wa-inna) ungodly (al-fujjāra) are in (la-fī) hell (jaḥīmin)
- 15. Verbal Congruence (مناسبة لفظيّة)
Verbal congruence is the use of two words or sets of words cast in the same metrical pattern. It is of two varieties: perfect and imperfect. In the first, congruent words or versicles rhyme with one another. In the second, they do not. We focus on one of them: the verbal congruence perfect. An example of perfect verbal congruence, nūru l-ghayāhibi (“the light of darkness”) and jammu l-mawāhibi (“abounding in gifts”) from ʿAbd al-Ghanī al-Nābulsī:نُورُ الغَياهِبِ في يَوْم الوَغى بَطَلٌ ... جمُّ المواهِبِ بَحْرُ الجُودِ والكَرَمِ
He is a light in darkness (nūru l-ghayāhibi), a hero on the day of strife,
Abounding in gifts (jammu l-mawāhibi), a sea of bounty and generosity - 16. Paronomasia/Pun (جناس)
This is use or suggestion in one context of words that differ in meaning but are phonetically and/or graphically alike or nearly alike. They are of seven main types:- 16.1. Conjunct Paronomasia (جناس
مركّب - مَرْفُوّ)
A paronomasia in which a single word is matched by a combination of more than one. An example from Ibn Nubāta (d. 1366 C.E.), in which amradā, “beardless youth” , is matched by am radā, “or death:”قمراً نَراهُ أمْ مليحا أمْرَدَا ... ولِحاظُه بينَ الجَوانِحِ أمْ رَدَى
Is it a moon that we see, or a handsome beardless youth (amradā)?
Is it his glances [wreaking havoc] in my breast, or is it death (am radā)? - 16.2. Tipped Paronomasia (جناس ناقص - مُطَرَّف)
A paronomasia in which one of the matching terms is longer than the other by at least one initial consonant. An example from Ibn al-Fāriḑ (d. 1235 C.E.):إنْ كانَ فِراقُنا مع الصُبْح بَدا لا أسْفَرَ بَعْدَ ذاكَ صُبْحٌ ... أبَدا
If with the dawn your parting must occur (badā),
Then may no dawn hereafter ever (abadā) break - 16.3. Tailed Paronomasia (جناس ناقص - مُذَيَّل)
A paronomasia in which one of the matching terms is longer than the other by one or more terminal consonants. An example by Ḥassān ibn Thābit (d. 674 C.E.):وُكنّا متى يَغْزُ النّبيُّ قَبيلَةًٌ ... نَصِلْ جانِبيْها بالقنا والقنابِل
Whenever the Prophet attacked a tribe,
We struck both flanks with lances (qanā) and with squadrons of horse (qanābil) - 16.4. Consonantal Paronomasia (جناس مُحَرَّف; also Distorted Paronomasia)
A paronomasia in which the two matching terms consist of the same letters in the same order, differing only in vocalization. An example from Sharaf al-Dīn al-Anṣārī (d. 1264 C.E.):لِعَيْني كُلّ يَوْمٍ ألفُ عَبْرَه ... تُصيّرُني لأهْل العِشْق عِبْرَه
My eyes shed every day a thousand tears (ʽabra)
So that to my lovers I have become an object lesson (ʽibra) - 16.5. Substitutive and Variant
Paronomasia (جناس تصريف
)
A paronomasia in which one of the matching terms has one letter – initial, medial or terminal – which differs from the corresponding letter in the other term, or is similar or close to their points of emission but does not differ in its dots (so that it belongs to a different or the same phonetic category). An example from Abū Firās al-Ḥamdānī (d. 968 C.E.):تَعِسَ الحَرِيصُ وَقَلَّ ما يأتي بِهِ ... عِوَضًا عنِ الإلْحاحِ وَالإلْحافِ
Wretched is the miser, and he seldom gets a return for his insistence (ilḥāḥ) and importuning (ilḥāf) - 16.6. Metathetic Paronomasia (جناس مقلوب; also Reverse
Paronomasia)
A paronomasia in which the two matching terms consist of the same letters, without addition or omission, but in different orders. An example from Shams al-Dīn Muḥammad al-Bakrī (d.1060 C.E.):قلتُ مستعطفاً لساقٍ سقاني ... من طلا نِيلِ مِصْرَ أعذبَ كاسِ
أنتَ عندي أعزّ منه ولكنْ ... قلبُه ليّنٌ وقلبُكَ قاسِ
Pleadingly, I said to a cupbearer (sāqī) who poured out to me of the liquor of Egypt’s Nile (nīl) a most limpid cup: You are dearer to me than it, and yet its heart is soft (layyin; the y in Arabic is written like the ī. Without the diacritics, the word layyin looks like līn), but yours is cruel (qāsī) - 16.7. Graphic Paronomasia (جناس تصحيف)
A paronomasia such that, when written, the two matching terms are shaped alike, differing only in their dots (which, in Arabic script, differentiate many letters from one another). An example:إنْ كان شرْعُ هواك أطْلَقَ أدمُعي ... فوَكيلُ شوْقي عاجزٌ عن حَبْسه
أوْ كان منكَ الطَّرْفُ أسْهَرَ ناظِرِي ... فَلِكُلّ شَيْءٍٍ آفَةٌ مِنْ جِنْسِه
Though the law of your love set free my tears,
Yet is the advocate of my yearning incapable of restraining it (ḥabsihi حبسه)
And, if your eyes deprive mine of sleep
[It is admitted that] all things are vulnerable to kindred ill (jinsihi جنسه)
- 16.1. Conjunct Paronomasia (جناس
مركّب - مَرْفُوّ)
- 17. Negative Antithesis (طباق سلب)
Combining the object (word) and its opposite in Arabic literature produces two main kinds of antithesis — positive and negative. Our focus was the negative, which is considered a type of Repetition, with the opposite word preceded by a negation article {لا, ما, لم, لن, ليس, لات, غير}. This example is from the poem by al-Buḥturī (d. 898 C.E.) between the phrases knowing and not knowing:يقيّض لي من حيث لا أعلم النوى ... ويسري إليّ الشوق من حيث أعلم
Separation is predestined to me from a source that I do not know (lā aʿlamu);
But I feel the longing of a source that I do know (aʿlamu). - 18. Positive Antithesis/Oxymoron (طباق إيجاب)
This is when words and their opposites appear in the same verse. Opposites formed by negation words are not positive antitheses. An example from Ibn Nubāta:دعوتُ ألْفاظ المَليح وكأسَه ... فنعمْتُ بينَ حديثه وعَتيقه
I call forth the fair one’s conversation and his cup, and so delight in his present discourse (ḥadīthihi) and old wine (qadīmihi). - 19. The Satirist’s Feint (تأكيد الذّم بما يشبه المدح)
This either (a) denies that the subject has any praiseworthy quality, or (b) ascribes to the subject a pejorative attribute then, after exempting him/her from it or rectifying it, names another pejorative attribute. An example from al-Nābulsī:فإن مَنْ لامَني لا خيرَ فيه سِوَى ... وصفي له بأخس الناس كًلّهِمِ
My reprover has no good qualities except (lā khayra fīhi siwā)
being the vilest among all people (akhassa l-nāsi kullihimi). - 20. The Encomiast’s Feint (تأكيد المدح بما يشبه الذّم)
This either (a) denies that the subject has any pejorative attributes, then exempts him/her from that denial, as if reversing it, a praiseworthy quality. Or (b) ascribes to the subject a praiseworthy quality then, after an exempting or rectifying word, names another praiseworthy quality. The following example is from the pre-Islamic poet an-Nābigha l-Dhubyānī (d. ca. 604 C.E.):ولا عَيْبَ فيهم غيرَ أنّ سُيوفَهُمْ ... بهنّ فلولٌ مِنْ قِراع الكَتائبِ
There is no fault in them, excepting that their swords — have
Suffered dents in clashes with battalions.
Appendix 2: Poets and Number of Poems
| Name of Poet | Number of poems in training set | Number of pomes in text set |
| Al-Buḥturī | 3 | |
| Ibn al-Rūmī | 7 | 1 |
| Abū Tammām | 9 | 1 |
| Al-Mutanabbī | 2 | |
| Dīk al-Jinn al-Ḥimṣī | 10 | |
| Al-Najāshī al-Ḥārithī | 2 | |
| Al-Kumayt ibn Zayd | 2 | |
| Ibn Qys al-Ruqayyāt | 2 | |
| Al-Ṭirimmāḥ b. Ḥakīm | 2 | |
| Jarīr | 2 | |
| Al-Farazdaq | 3 | |
| Abū Dhuʾayb al-Hudhalī | 2 | |
| Bashshār b. Burd | 1 | |
| Al-Aʿshā Maymūn | 1 | 1 |
| Imruʾ al-Qays | 1 | |
| Mulayḥ b. al-Ḥakam | 1 | |
| Abū Arāka | 1 | |
| Ayman b. Khuraym | 1 | |
| ّTaʾabbaṭa Sharran | 1 | |
| Dhū l-Rumma | 1 | |
| ʿUbaydallāh b. al-Ḥurr | 1 | |
| ʿImrān b. Ḥiṭṭān | 1 | |
| Qaṭarī b. al-Fujāʾa | 1 | |
| Yazīd b. Mufarrigh al-Ḥimyarī | 1 | |
| Al-Nābigha l-Dhubyānī | 1 | |
| Rabīʿa b. Maqrūm | 1 | |
| Al-Namir b. Tawlab | 1 | |
| Al-Ḥakam b. ʿAbdal | 1 | |
| Abū Dulāma | 2 | |
| Anonymous (Abbasid poet) | 1 | |
| Al-Ḥamdawī | 3 | |
| Abū Nuwās | 1 | |
| Muḥammad b. Yasīr al-Riyāshī | 1 | |
| Abān al-Lāḥiqī | 1 | |
| ʿAbdallāh b. ʿAbd al-Ḥamīd al-Lāḥiqī | 1 | |
| Total count | 58 | 17 |
Appendix 3: Number of Rhetorical Elements in the Training and Test Datasets
| Elements | Appearances in the sets | Training set | Test set |
| Simile تشبيه | 290 | 37 | |
| Repetition1 (تكرار) | 196 | 31 | |
| Repetition2 (اشتقاق) | 247 | 40 | |
| Repetition3 (echo رد الاعجاز على الصدور) | 131 | 17 | |
| Repetition4 – Key Words كلمات مفتاح | 66 | 45 | |
| Flowing (اطراد) | 5 | 3 | |
| Afterthought (رجوع) | 5 | 5 | |
| Catchword Verbal (تشابه الاطراف اللفظي) | 4 | 8 | |
| Distribution Characters1/Alliteration 1 (توزيع 1) | 5 | 5 | |
| Distribution Characters2/ Alliteration2 (توزيع 2) | 174 | 51 | |
| Hemming (تصريع) | 5 | 5 | |
| Unraveling ((توشيع) | 16 | 14 | |
| Counterchange (عكس وتبديل) | 8 | 5 | |
| Repartee (مراجعة) | 6 | 5 | |
| Rhyming – in general – homoeoteleuton (سجع) | 5 | 24 | |
| Verbal Congruence (مناسبة لفظيّة) | 4 | 7 | |
| Paronomasia (جناس) | 32 | 21 | |
| Negative Antithesis (طباق سلب) | 66 | 7 | |
| Positive Anthithesis / Oxymoron (طباق إيجاب) | 245 | 35 | |
|
Satirist's, Encomiast's Feints
(تأكيد الذّم بما يشبه المدح تأكيد المدح بما يشبه الذّم) |
10 | 13 |
Appendix 4: Appearance of Each Rhetorical Element in Each Poem (Rhetorical Elements are numbered 1,2,3,4,5,9.2,12,16,17,18
| Poet | Poem number | Ele.1 | Ele.2 | Ele.3 | Ele.4 | Ele.5 | Ele.9.2 | Ele.12 | Ele.16 | Ele.17 | Ele.18 |
| Al-Buḥturī | 51 | 8 | 5 | 4 | 7 | 0 | 3 | 0 | 0 | 3 | 5 |
| 256 | 11 | 3 | 2 | 0 | 0 | 3 | 0 | 0 | 2 | 3 | |
| 915 | 10 | 4 | 15 | 3 | 0 | 3 | 1 | 1 | 1 | 11 | |
| Ibn al-Rūmī | 9 | 8 | 2 | 9 | 3 | 6 | 3 | 1 | 0 | 1 | 6 |
| 104 | 4 | 4 | 2 | 2 | 0 | 3 | 1 | 2 | 0 | 3 | |
| 343 | 4 | 2 | 2 | 1 | 0 | 3 | 0 | 0 | 1 | 3 | |
| 344 | 3 | 3 | 3 | 1 | 0 | 3 | 0 | 0 | 0 | 4 | |
| 539 | 0 | 2 | 2 | 4 | 0 | 3 | 0 | 0 | 2 | 8 | |
| 691 | 1 | 1 | 2 | 3 | 0 | 3 | 0 | 0 | 1 | 1 | |
| 701 | 3 | 5 | 2 | 7 | 0 | 3 | 2 | 0 | 0 | 2 | |
| Abū Tammām | 2 | 10 | 6 | 6 | 3 | 0 | 3 | 0 | 2 | 1 | 6 |
| 5 | 13 | 12 | 11 | 14 | 0 | 3 | 0 | 0 | 14 | 9 | |
| 21 | 2 | 0 | 2 | 4 | 0 | 3 | 0 | 0 | 0 | 3 | |
| 71 | 13 | 6 | 7 | 4 | 0 | 3 | 1 | 0 | 0 | 12 | |
| 179 | 9 | 5 | 1 | 4 | 0 | 3 | 0 | 0 | 2 | 5 | |
| 393 | 6 | 3 | 6 | 5 | 0 | 3 | 0 | 1 | 4 | 10 | |
| 464 | 1 | 2 | 2 | 0 | 0 | 3 | 0 | 0 | 4 | 8 | |
| 470 | 3 | 6 | 5 | 0 | 0 | 3 | 0 | 0 | 0 | 3 | |
| 484 | 4 | 2 | 6 | 1 | 2 | 3 | 0 | 0 | 3 | 10 | |
| al-Mutanabbī | 59 | 21 | 10 | 7 | 1 | 0 | 3 | 0 | 1 | 1 | 9 |
| 209 | 5 | 9 | 6 | 2 | 0 | 3 | 0 | 0 | 2 | 17 | |
| Dīk al-Jinn al-Ḥimṣī- | 13 | 0 | 3 | 2 | 2 | 0 | 3 | 2 | 0 | 0 | 2 |
| 14 | 0 | 1 | 0 | 0 | 1 | 3 | 0 | 0 | 2 | 1 | |
| 9 | 9 | 6 | 7 | 6 | 0 | 3 | 0 | 0 | 3 | 5 | |
| 62 | 4 | 5 | 3 | 3 | 0 | 3 | 1 | 0 | 0 | 0 | |
| 11 | 5 | 2 | 6 | 3 | 0 | 3 | 0 | 0 | 0 | 7 | |
| 15 | 0 | 3 | 1 | 1 | 0 | 3 | 0 | 0 | 0 | 1 | |
| 2 | 0 | 4 | 7 | 2 | 1 | 3 | 0 | 0 | 1 | 3 | |
| 35 | 0 | 0 | 0 | 0 | 1 | 3 | 0 | 0 | 0 | 0 | |
| 38 | 0 | 8 | 3 | 1 | 1 | 3 | 0 | 0 | 1 | 2 | |
| 33 | 1 | 1 | 1 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | |
| Al-Najāshī al-Ḥārithī | 41 | 4 | 1 | 1 | 1 | 0 | 3 | 0 | 0 | 0 | 1 |
| 62 | 14 | 4 | 7 | 1 | 1 | 3 | 0 | 0 | 1 | 3 | |
| Al-Kumayt ibn Zayd | 6 | 5 | 3 | 4 | 2 | 0 | 3 | 0 | 0 | 0 | 5 |
| 8 | 1 | 2 | 3 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | |
| Ibn Qys al-Ruqayyāt | 40 | 2 | 0 | 2 | 0 | 7 | 3 | 0 | 0 | 0 | 2 |
| 50 | 1 | 4 | 4 | 2 | 0 | 3 | 0 | 0 | 0 | 3 | |
| Al-Ṭirimmāḥ b. Ḥakīm | 22 | 3 | 1 | 3 | 1 | 1 | 3 | 0 | 0 | 0 | 1 |
| 290 | 1 | 1 | 3 | 1 | 3 | 3 | 0 | 1 | 1 | 3 | |
| Jarīr | 3 | 4 | 9 | 3 | 5 | 2 | 3 | 0 | 1 | 4 | 7 |
| 11 | 1 | 3 | 7 | 0 | 4 | 3 | 0 | 0 | 0 | 1 | |
| Al-Farazdaq | 35 | 5 | 0 | 3 | 1 | 4 | 3 | 0 | 0 | 0 | 6 |
| 50 | 0 | 2 | 3 | 0 | 2 | 3 | 0 | 0 | 1 | 5 | |
| 181 | 7 | 4 | 7 | 1 | 9 | 3 | 0 | 0 | 2 | 8 | |
| Abū Dhuʾayb al-Hudhalī | 1 | 12 | 1 | 7 | 2 | 0 | 3 | 0 | 0 | 0 | 0 |
| 2 | 4 | 2 | 5 | 1 | 7 | 3 | 0 | 0 | 1 | 6 | |
| Bashshār b. Burd | 26 | 14 | 6 | 13 | 6 | 0 | 3 | 2 | 0 | 3 | 11 |
| Al-Aʿshā Maymūn | 79 | 13 | 1 | 2 | 1 | 0 | 3 | 0 | 0 | 1 | 3 |
| Imruʾ al-Qays | 8 | 8 | 1 | 4 | 2 | 0 | 3 | 0 | 0 | 0 | 0 |
| Mulayḥ b. al-Ḥakam | 2 | 12 | 3 | 2 | 1 | 7 | 3 | 0 | 0 | 0 | 2 |
| Abū Arāka | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 |
| Ayman b. Khuraym | 17 | 1 | 2 | 3 | 2 | 1 | 3 | 0 | 0 | 0 | 1 |
| Taʾabbaṭa Sharran | 29 | 7 | 8 | 9 | 6 | 0 | 3 | 1 | 2 | 1 | 9 |
| Dhū l-Rumma | 30 | 10 | 0 | 5 | 0 | 0 | 3 | 0 | 0 | 0 | 1 |
| ʿUbaydallāh b. al-Ḥurr | 53 | 1 | 1 | 5 | 2 | 0 | 3 | 0 | 0 | 0 | 1 |
| ʾImrān b. Ḥiṭṭān | 199 | 1 | 1 | 4 | 0 | 6 | 3 | 0 | 0 | 1 | 6 |
| Qaṭarī b. al-Fujāʾa | 121 | 0 | 3 | 3 | 1 | 0 | 3 | 0 | 0 | 0 | 1 |
| Yazīd b. Mufarrigh al-Ḥimyarī | 44 | 1 | 8 | 3 | 5 | 0 | 3 | 0 | 0 | 1 | 0 |
| Tally of poems in training set | 58 | 290 | 196 | 247 | 131 | 66 | 174 | 12 | 11 | 66 | 245 |
| Al-Nābigha l-Dhubyānī- | 36 | 8 | 4 | 11 | 3 | 6 | 3 | 1 | 0 | 3 | 5 |
| Rabīʿa b. Maqrūm | 43 | 3 | 1 | 2 | 0 | 3 | 3 | 0 | 0 | 1 | 0 |
| Al-Aʿshā Maymūn | 78 | 6 | 4 | 5 | 2 | 1 | 3 | 0 | 0 | 0 | 5 |
| Al-Namir b. Tawlab | 34 | 2 | 3 | 3 | 0 | 2 | 3 | 0 | 0 | 1 | 1 |
| Al-Ḥakam b. ʿAbdal | 1 | 2 | 4 | 2 | 1 | 8 | 3 | 1 | 0 | 0 | 0 |
| Abū Dulāma | 1 | 4 | 0 | 1 | 1 | 0 | 3 | 0 | 0 | 0 | 0 |
| Anonymous poet | 9 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 1 |
| Abū Tammām | 338 | 0 | 1 | 3 | 0 | 4 | 3 | 0 | 0 | 1 | 3 |
| Al-Ḥamdawī | 12 | 0 | 1 | 0 | 0 | 4 | 3 | 0 | 0 | 0 | 0 |
| Abū Nuwās | 2 | 3 | 1 | 0 | 1 | 1 | 3 | 0 | 0 | 0 | 2 |
| Muḥammad . Yasīr al-Riyāshī | 2 | 2 | 2 | 0 | 1 | 3 | 0 | 0 | 0 | 1 | |
| Abū Dulāma | 1 | 2 | 4 | 3 | 4 | 10 | 3 | 0 | 0 | 1 | 8 |
| Ibn al-Rūmī | 6 | 2 | 1 | 1 | 1 | 1 | 3 | 0 | 0 | 0 | 2 |
| Al-Ḥamdawī | 6 | 0 | 0 | 1 | 0 | 1 | 3 | 0 | 0 | 0 | 3 |
| Al-Ḥamdawī | 8 | 0 | 0 | 3 | 0 | 2 | 3 | 0 | 0 | 0 | 1 |
| ʿAbdallāh b. ʿAbd al-Ḥamīd al-Lāḥiqī | 4 | 1 | 3 | 1 | 1 | 0 | 3 | 0 | 0 | 0 | 2 |
| Abān al-Lāḥiqī | 1 | 2 | 2 | 2 | 3 | 1 | 3 | 0 | 0 | 0 | 1 |
| Tally of poems in testing set | 10 | 37 | 31 | 40 | 17 | 29 | 51 | 2 | 0 | 7 | 35 |
Acknowledgement
Notes
Works Cited

Comments: dhqinfo@digitalhumanities.org
Published by: The Alliance of Digital Humanities Organizations and The Association for Computers and the Humanities
Affiliated with: Digital Scholarship in the Humanities
DHQ has been made possible in part by the National Endowment for the Humanities.
Copyright © 2005 -

Unless otherwise noted, the DHQ web site and all DHQ published content are published under a Creative Commons Attribution-NoDerivatives 4.0 International License. Individual articles may carry a more permissive license, as described in the footer for the individual article, and in the article’s metadata.
