


Volume 15 Number 1
Advances in Digital Music Iconography: Benchmarking the detection of musical instruments in unrestricted, non-photorealistic images from the artistic domain
Abstract
In this paper, we present MINERVA, the first benchmark dataset for the detection of musical instruments in non-photorealistic, unrestricted image collections from the realm of the visual arts. This effort is situated against the scholarly background of music iconography, an interdisciplinary field at the intersection of musicology and art history. We benchmark a number of state-of-the-art systems for image classification and object detection. Our results demonstrate the feasibility of the task but also highlight the significant challenges which this artistic material poses to computer vision. We evaluate the system to an out-of-sample collection and offer an interpretive discussion of the false positives detected. The error analysis yields a number of unexpected insights into the contextual cues that trigger the detector. The iconography surrounding children and musical instruments, for instance, shares some core properties, such as an intimacy in body language.
Introduction: the era of the pixel
Motivation
Music iconography
Computer vision
Photo-realism
Data scarcity
Irrelevant training categories
Robustness of the models
MINERVA: dataset description
Data Sources
- RIDIM: We harvested a collection of high-quality images from the RIDIM database, in those cases where the database entries provided an unambiguous hyperlink to a publicly accessible image. These records were already assigned MIMO codes by a community of domain experts, which provided important support to our in-house annotators (especially during the first experimental rounds of annotations).
- RMFAB/RMAH: We expanded on the core RIDIM data by including (midrange resolution) images from the digital collections of two federal museums in Brussels: the RMFAB (Royal Museums of Fine Arts of Belgium, Brussels) and the RMAH (Royal Museums of Art and History, Brussels). These images were selected on the basis of previous annotations that suggested they included depictions of musical instruments, although no more specific labels (e.g. MIMO codes) were available for these records at this stage. Copyrighted artworks could not be included for obvious reasons (copyright lasts for 70 years from the death of the creator under Belgian intellectual law).
- Flickr: To scale up our annotation efforts, finally, we collected a larger dataset of images from the well-known image hosting service 'Flickr' (www.flickr.com). We harvested all images from a community-curated collection of depictions of musical instruments in the visual arts pre-dating 1800.[3] This third campaign yielded much more data than the former two, but these were more noisy and contained a variety of false positives that had to be manually deleted during the annotation phase.
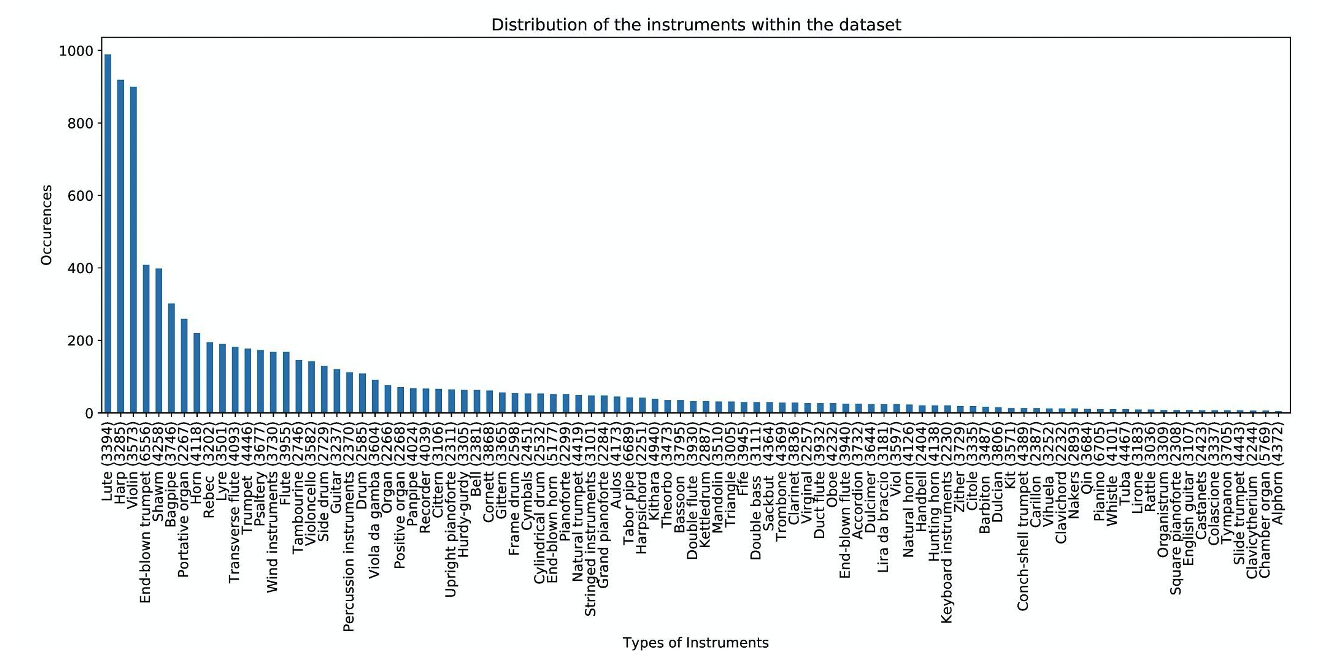
Vocabulary
| Instrument hypernym | Stringed instruments | Wind instruments | Percussion instruments | Keyboard instruments | Electronic instruments |
| Example instruments | Lute, psaltery, fiddle, viola da gamba, cittern | Transverse flute, end-blown trumpet, horn, shawm, bagpipe | Tambourine, cylindrical drum, frame drum, friction drum, bell | Pianoforte, virginal, portative organ, harpsichord, clavichord | Electric guitar, synthesizer, theremin, vocoder, mellotron |
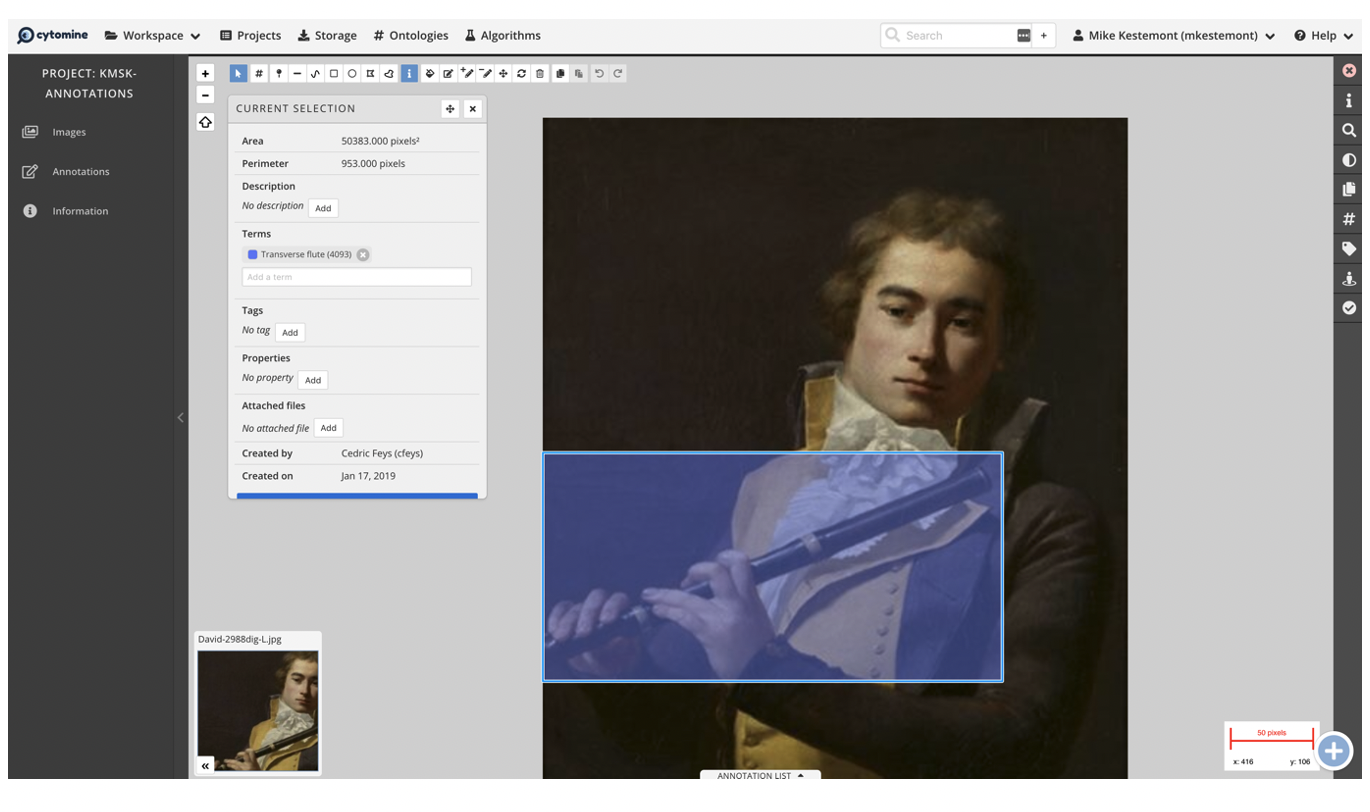
Annotation process
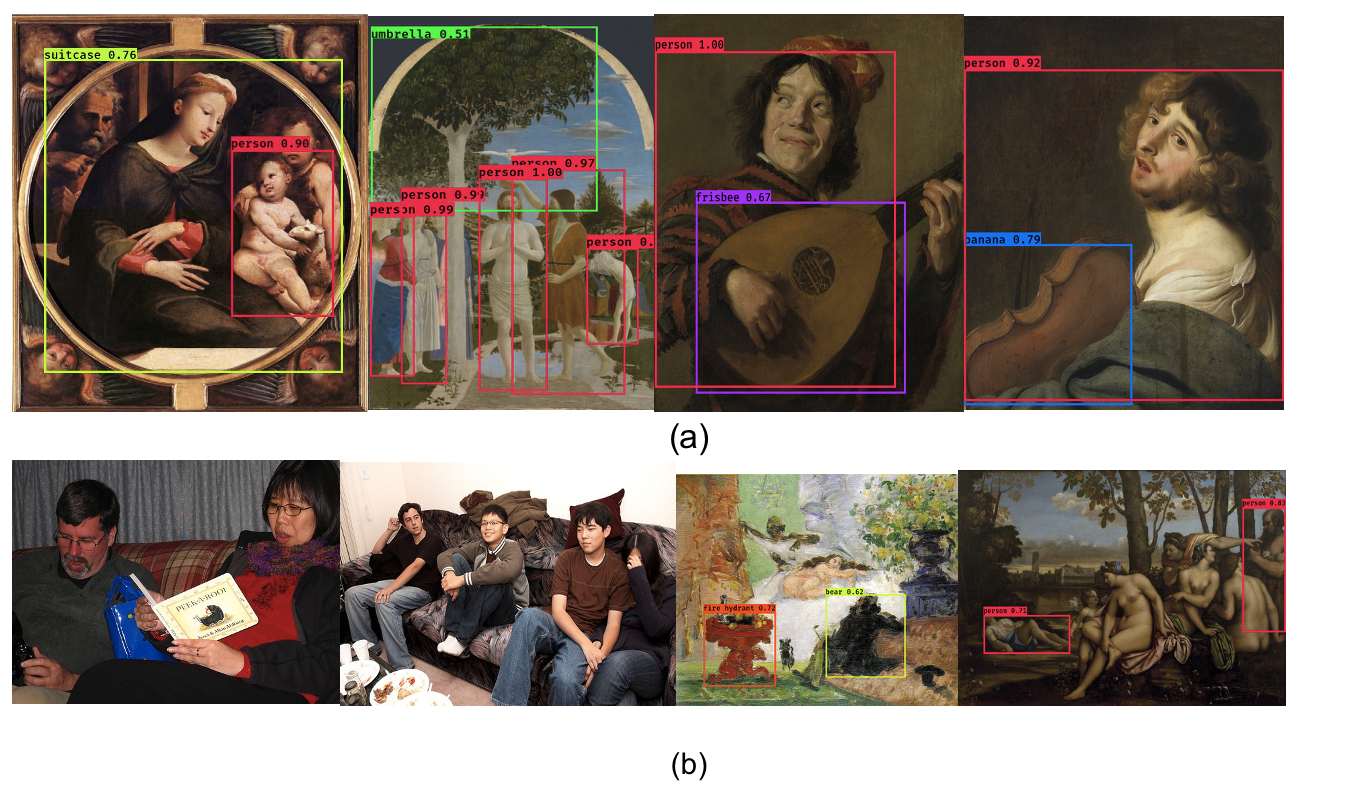
- Representation: A challenging aspect was the variety of artistic depiction modes represented in the dataset, ranging from photo-realistic renderings to heavily stylized depictions from specific art-historical movements (e.g. impressionism, pointillism, fauvism, cubism, ...) (Figure 3a). Additionally, visibility could be low due to a proportionally small instrument depiction or the profusion of details (Figure 3b). In some instances, the state of the depicted object and its medium made the detection of the instrument difficult, e.g. a damaged medieval tympanon (Figure 3b).
- Quality: Other, more pragmatic issues arose from the images themselves. Occasionally, the quality of the images was too low to be able to detect the instruments (e.g. low resolution or compression defects) (Figure 3c). A great deal of the images did not meet international quality standards for heritage reproduction photography (uniform and neutral environment and lighting, frontal point of view), which implies that the instruments were even more difficult to detect.
- Boxes: The use of a rectangular shape for the bounding boxes sometimes has limitations and implied a certain lack of precision, e.g. in the case of a diagonally positioned flute, or in the case of overlapping instruments (Figure 3d). For some instruments which consist of several parts, e.g. a violin and its bow, only the main part (the violin) was annotated.

Characteristics
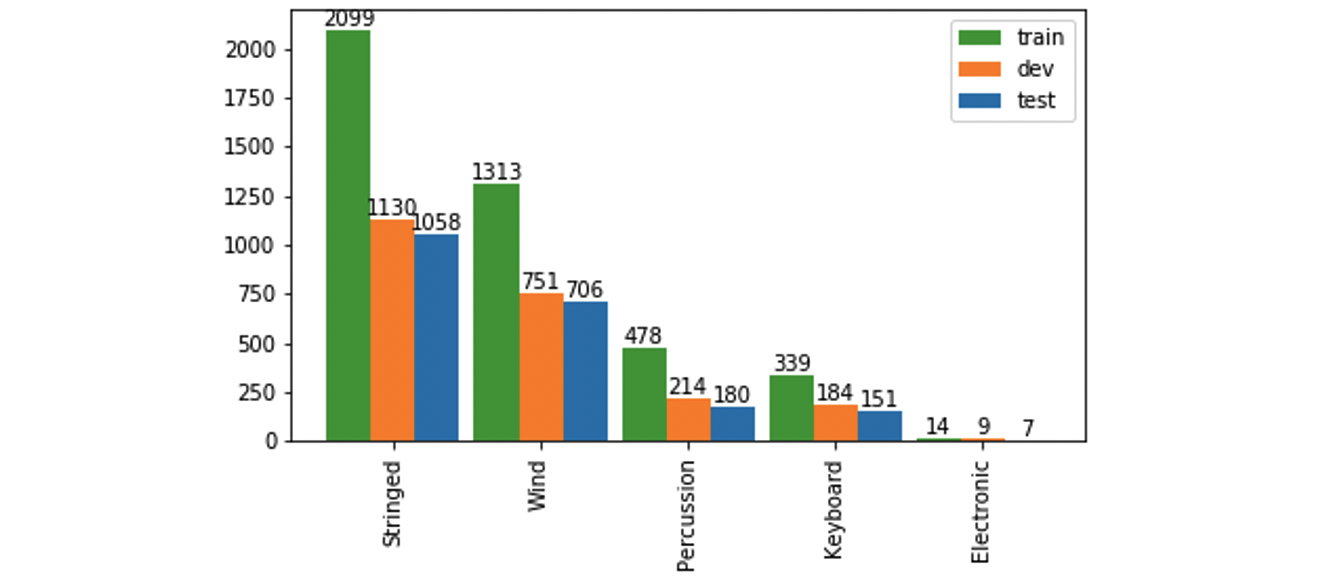
Versions and splits
| Training-set | Dev-set | Test-set | Total | |||||
| Imag | Inst | Imag | Inst | Imag | Inst | Imag | Inst | |
| Single inst | 1857 | 4243 | 1137 | 2288 | 1189 | 2102 | 4183 | 8633 |
| Top-5 inst | 952 | 1589 | 540 | 852 | 724 | 1173 | 2216 | 3614 |
| Top-10 inst | 1227 | 2147 | 680 | 1127 | 898 | 1506 | 2805 | 4780 |
| Top-20 inst | 1471 | 2915 | 860 | 1543 | 1047 | 1838 | 3378 | 6296 |
Benchmark experiments
Classification

| Top-5 inst | Top-10 inst | Top-20 inst | All inst | Hypernyms | ||||||
| CNN | Acc. | F1 | Acc. | F1 | Acc. | F1 | Acc. | F1 | Acc. | F1 |
| R-Net | 68.71 | 64.10 | 52.85 | 41.55 | 30.73 | 8.45 | 26.36 | 2.08 | 72.26 | 52.66 |
| V3 | 73.66 | 70.29 | 55.51 | 44.77 | 36.51 | 19.06 | 27.02 | 6.67 | 75.80 | 57.03 |
| V19 | 48.33 | 35.92 | 37.52 | 15.22 | 33.41 | 9.87 | 20.17 | 1.72 | 66.41 | 40.35 |
| Predicted label / Gold label | Bagpipe | E-b trumpet | Harp | Horn | Lute | Lyre | Por. organ | Rebec | Shawm | Violin |
| Bagpipe | 31 | 0 | 10 | 6 | 8 | 1 | 2 | 0 | 7 | 17 |
| E-b trumpet | 4 | 72 | 19 | 2 | 14 | 1 | 3 | 1 | 38 | 21 |
| Harp | 8 | 2 | 227 | 1 | 10 | 3 | 11 | 0 | 10 | 19 |
| Horn | 7 | 5 | 14 | 9 | 16 | 9 | 1 | 2 | 5 | 14 |
| Lute | 6 | 10 | 17 | 6 | 199 | 6 | 5 | 1 | 5 | 42 |
| Lyre | 3 | 0 | 19 | 1 | 13 | 5 | 2 | 0 | 3 | 11 |
| Por. organ | 3 | 0 | 10 | 1 | 0 | 0 | 57 | 0 | 1 | 4 |
| Rebec | 5 | 2 | 14 | 0 | 9 | 0 | 4 | 7 | 1 | 23 |
| Shawm | 4 | 11 | 25 | 2 | 11 | 2 | 4 | 6 | 40 | 13 |
| Violin | 6 | 12 | 29 | 4 | 35 | 4 | 7 | 11 | 6 | 202 |
Detection
| Instrument ≥ IoU | Precision | Recall | AP |
| Single-instrument ≥ 10 Single-instrument ≥ 50 |
0.63 0.47 |
0.42 0.31 |
0.35 0.22 |
| Stringed-Instruments ≥ 10 Stringed-Instruments ≥ 50 |
0.65 0.53 |
0.36 0.29 |
0.28 0.20 |
| Wind-Instruments ≥ 10 Wind-Instruments ≥ 50 |
0.43 0.32 |
0.07 0.05 |
0.04 0.02 |
| Percussion-Instruments ≥ 10 Percussion-Instruments ≥ 50 |
0.32 0.21 |
0.04 0.03 |
0.02 0.01 |
| Keyboard-Instruments ≥ 10 Keyboard-Instruments ≥ 50 |
0.61 0.45 |
0.11 0.08 |
0.07 0.04 |
| Electronic-Instruments ≥ 10 Electronic-Instruments ≥ 50 |
- - |
- - |
- - |
| Harp ≥ 10 Harp ≥ 50 |
0.68 0.60 |
0.62 0.54 |
0.55 0.46 |
| Lute ≥ 10 Lute ≥ 50 |
0.57 0.47 |
0.43 0.35 |
0.36 0.26 |
| Violin ≥ 10 Violin ≥ 50 |
0.37 0.26 |
0.22 0.16 |
0.12 0.07 |
| Shawm ≥ 10 Shawm ≥ 50 |
0.13 0.08 |
0.04 0.02 |
0.01 0.00 |
| End-blown trumpet ≥ 10 End-blown trumpet ≥ 50 |
0.28 0.24 |
0.04 0.03 |
0.01 0.01 |
| Harp ≥ 10 Harp ≥ 50 |
0.62 0.56 |
0.56 0.51 |
0.46 0.39 |
| Lute ≥ 10 Lute ≥ 50 |
0.55 0.47 |
0.42 0.36 |
0.33 0.25 |
| Violin ≥ 10 Violin ≥ 50 |
0.26 0.20 |
0.19 0.14 |
0.06 0.04 |
| Shawm ≥ 10 Shawm ≥ 50 |
0.17 0.17 |
0.03 0.01 |
0.00 0.00 |
| End-blown trumpet ≥ 10 End-blown trumpet ≥ 50 |
0.67 0.17 |
0.02 0.03 |
0.01 0.00 |
| Bagpipe ≥ 10 Bagpipe ≥ 50 |
0 0 |
0 0 |
0 0 |
| Portative-Organ ≥ 10 Portative-Organ ≥ 50 |
0.24 0.24 |
0.13 0.13 |
0.06 0.06 |
| Horn ≥ 10 Horn ≥ 50 |
0 0 |
0 0 |
0 0 |
| Rebec ≥ 10 Rebec ≥ 50 |
- - |
- - |
- - |
| Lyre ≥ 10 Lyre ≥ 50 |
- - |
- - |
-- - |
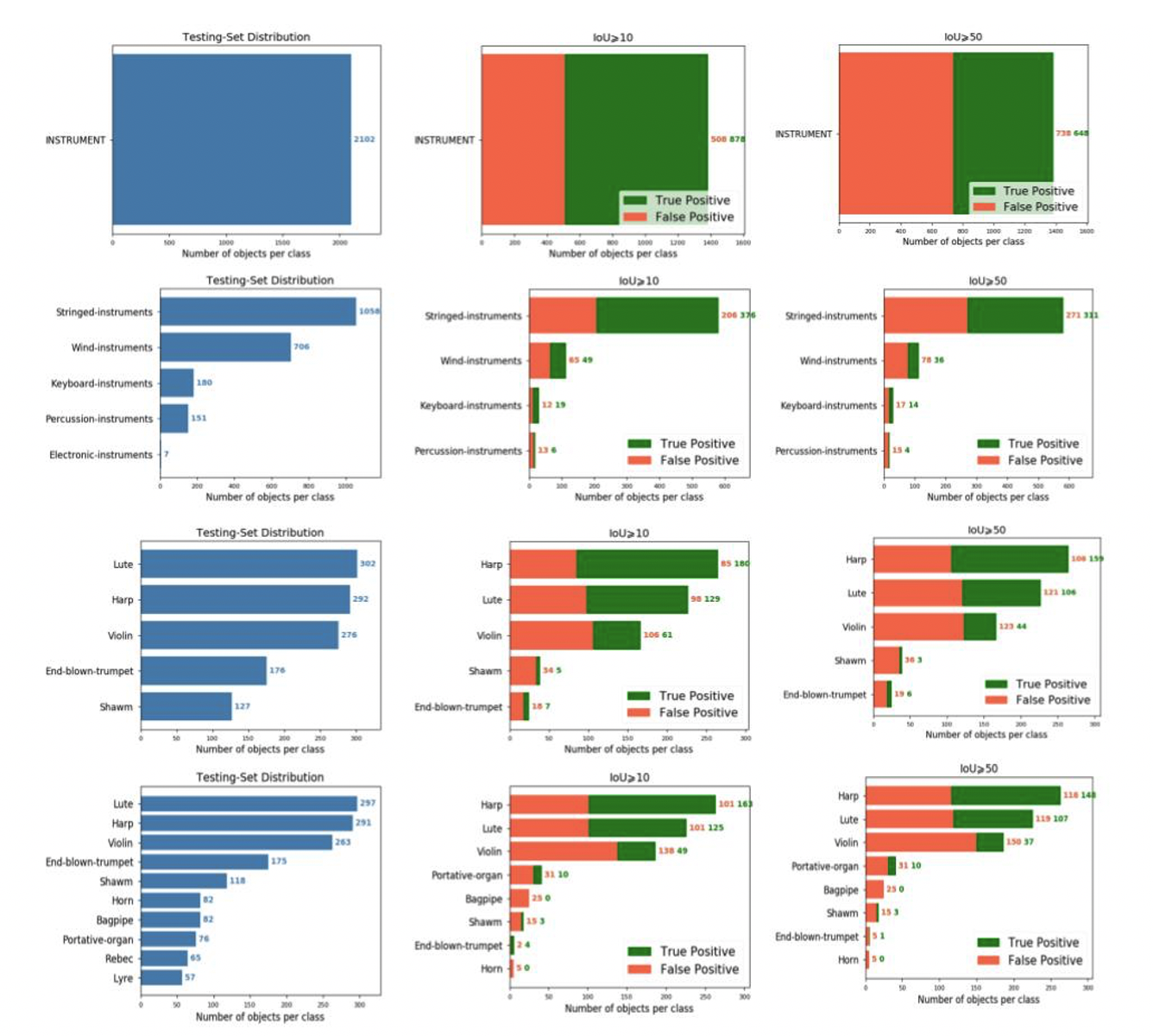

Additional experiments
- RMFAB/RMAH: 428 out-of-sample images from the digital assets of both museum collections that are not included in the annotated material (and which are thus not included the train and validation material of the applied detector), because the available metadata did not explicitly specify that they contained depictions of musical instruments. (This collection cannot be shared due to copyright restrictions.)
- IconArt: a generic collection of 6,528 artistic images, collected from the community-curated platform WikiArt: Visual Art Encyclopedia (https://www.wikiart.org/). The IconArt subcollection was previously redistributed by [Gonthier et al. 2018]: https://wsoda.telecom-paristech.fr/downloads/dataset/.
| Collection | Total images | Detections | True positives |
| RMFAB/RMAH | 428 | 162 | 6 |
| IconArt | 6528 | 118 | 42 |
Discussion
Skewed results
Saliency maps
- (a) Focus on the neck of the stringed instrument, as well as the characteristic presence of tuning pins at the end of the neck;
- (b) Sensitive to the presence of stretched fingers in an unnatural position;
- (c) Typical conic shape of a lyre, with outward pointing ends connected by a bridge;
- (d) Symmetric presence of tone holes in the areophone;
- (e) Elongated, cylindric shape of the main body of the areophone with wider end;
- (f) Mirrored placement of fingers and hands (close to one another).

Error analysis: false positives


Conclusions and future research
Acknowledgements
Notes
Works Cited

Comments: dhqinfo@digitalhumanities.org
Published by: The Alliance of Digital Humanities Organizations and The Association for Computers and the Humanities
Affiliated with: Digital Scholarship in the Humanities
DHQ has been made possible in part by the National Endowment for the Humanities.
Copyright © 2005 -

Unless otherwise noted, the DHQ web site and all DHQ published content are published under a Creative Commons Attribution-NoDerivatives 4.0 International License. Individual articles may carry a more permissive license, as described in the footer for the individual article, and in the article’s metadata.
