Abstract
Internet technologies are gradually reshaping the function of traditional
scholarly publications. There is a growing tendency in some disciplines to
publish a digital paper together with supplements such as images, videos,
3D-models and underlying data. More information requires a better usability in
terms of overview and finding information, which has led to new features in
journals and thus to modifying and extending this genre. These so-called
enhanced publications or rich internet publications have various physical forms:
PDF documents with embedded interactive models, HTML files enriched with
hyperlinks to contextual information and with facilities to highlight
information in the text, or aggregations of documents and other resources linked
together through metadata which make them findable for semantic search
engines.
However, many of the originally print-based journals, particularly in the
humanities and social sciences, are still rather conservative in format and
offer hardly any opportunities for enhanced publishing, which leaves room for
some form of self-publishing, perhaps as addition to a regular journal article.
In this paper we introduce the Xpos’re tools for authoring and displaying an
interactive multimedia scholarly publication, which may be created as a digital
companion to a regular journal paper and published, for example, on the author
or institution’s website in order to share related research products and to
achieve greater visibility. We also report about practical experiences with this
software in a few research projects.
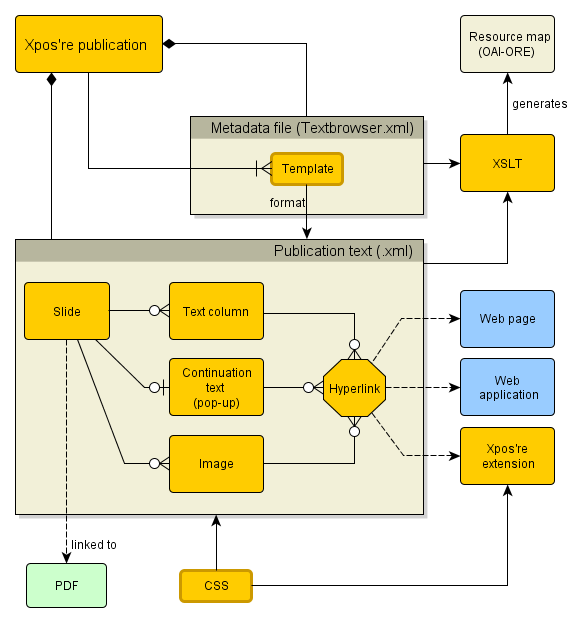
The Xpos’re software (see: http://xposre.nl/software/) comprises a Flash-based document reader
and a set of extensions (plug-ins) that extend the basic functionality of this
text browser. The extensions are used to display specific types of multimedia
that provide additional functionality, such as viewing images, videos and
interactive maps. The input text is XML based, which not only guarantees a
durable and flexible encoding of content, but also allows automatic rendering in
different formats according to the preferences of users and the limitations of
their hardware. In addition, the XML source can be easily transformed to an RDF
resource map to meet the requirements of the semantic web. The document reader
generates output in HTML, in two flavors, namely a slide based version that uses
JavaScript, and a plain HTML text (single page), which is most suitable for
printing and which can be used to create e-books. This plain HTML text can also
be displayed in a format similar to that of scientific journals through the
Xpos’re HTML Reader, which has more features than the automatically generated
slides and which can be highly customized by the user.
1. From PDF to Rich Internet Publication and E-book
Innovation in Scholarly Genres
The journal article is still the basis of scholarly communication in most
disciplines. For a long time, the available space in a printed publication
and the high production costs have put restrictions on adding supplementary
material such as pictures, maps and fragments from historical sources. The
change to web publishing has taken away these material impediments, but in
facing new media we are inclined to recreate the old genre by new means. The
form and layout of online publications are in general still dominated by
genre conventions based on printed journals and books. The capabilities of
the digital channel are often underutilized, which makes that scholarly
communications are currently at a “horseless carriage”
state, that lies somewhere between the world of print and paper and the
world of the web and computers, with the former still exercising
significantly more influence than the latter [
Force 11].
There are signs that point to profound changes coming to the system of
scholarly communication [
Borgman 2007]; [
Wouters 2012]. Research on digital curation deliver new
publishing models, social media plays a rapidly increasing role in the
exchange and discussion of scientific ideas, and some journals have already
deliberately changed track by adopting a new format with enhanced usability.
Moreover, scholarly blogs offer ample opportunity to experiment with new
media such as audio and video. These innovations are unevenly spread over
the scholarly landscape: most changes occur in the hard sciences,
particularly in physics, chemistry and the bio-medical field, while
humanities and social sciences are more reluctant in this respect.
[1]
The downside of this transition has a practical problem: the technology
required for the novel forms of publishing is generally not yet embedded in
a smooth authoring process comparable with that for printed publications.
Adding multimedia to a blog may not be a big problem, but a scholarly
journal adheres to higher standards of long-term sustainable information
access and aesthetic layout, which also places demands on the authoring
process, and, therefore, on the tools and templates which authors have at
their disposal. Non-printable supplements are often stored in a separate
section of the publisher’s website and as such are not perceived as part of
the discourse itself. The Xpos’re software package discussed here addresses
this type of problem for online publications that contain interactive
multimedia closely connected with the text. The pros and cons are best
understood after a short overview of the upcoming digital genres (section
1.2 through 1.4) followed by a preliminary conclusion (section 1.5)
explaining why new tools are needed.
The innovative scholarly genres can be grouped into a few, not strictly
defined categories: (1) enhanced publications, (2) rich internet publication
and (3) ebooks. These new genres still reflect many features of the old ones
from which they are derived, but have in common a certain integration of the
scholarly discourse with interactive access to research material. This
integration varies greatly, from linked research data and spreadsheets to
embedded interactive statistical charts and maps with results of analysis
and computation, image galleries, animated models and videos. The
interactivity added to the linear reading allows for diversion from the main
line of discourse and enables the user to select the information in which
(s)he is particularly interested, to choose different perspectives and to
explore data with new questions.
Enhanced Publications
The less advanced category is the so-called “enhanced
publication.” The term refers to the old genre of printed
papers, which, in digital format, have been enhanced with additional
material such as research data, models, illustrative images, or
post-publication comments and rankings, all rather loosely linked to the
publication through metadata. The data enhancements enable the replication
of research as well as secondary analysis of the underlying data sets.
Relating digital content resources that are distributed over different
collections (e.g. in literature studies and historic research) can greatly
enhance their value provided this is done in an interoperable
machine-readable way, which makes that they can be indexed by semantic
search engines. The
Open Archives Initiative – Object
Reuse and Exchange (OAI-ORE) has provided a standard for this
purpose [
Lagoze 2007]. The Australian LORE (Literature Object
Re-use and Exchange) software is one of the tools supporting this standard.
It consists of a lightweight Firefox extension for creating, labeling and
visualizing typed relationships between individual objects, and relies on a
backend repository [
Gerber 2009]. The ESCAPE editor in
combination with the InContext visualizer (both of Dutch origin) has a
similar functionality and also allows to create and to display a semantic
overlay in the form of an OAI-ORE based resource map, encoded in RDF [
Bentum2009]. There are more projects working into the same
direction using RDF or the OAI-ORE protocol more specifically, such as
Foresite
[2] and eChemistry.
[3]
The advantage of such a package that includes the publication plus loosely
coupled addenda which are accessible through hyperlinks, is that the
creation is relatively easy, because it does not affect the published
document itself; a layer of metadata is sufficient. However, it has a low
degree of integration and, therefore, is not particularly comfortable. The
display of these extras is usually spread over different windows, each
operating in isolation.
Rich Internet Publications
The more integrated publication formats cannot be adequately described as
simply “enhanced publications”. We have argued elsewhere
[
Breure 2011], that the term
rich internet
publication (RIP) is to be preferred for this more advanced form,
which consists of seamless combination of text, data and illustrations.
Usually it has a higher degree of interactivity by the use of slideshows,
image galleries, maps, and query interfaces. Integration concerns a variety
of aspects, such as internal linking between information objects and the
functional combination of user interface components on the presentation
level.
Elsevier’s
Article of the Future is the most
well-known example. In 2009 this publisher initiated this project to improve
the electronic communication of research. In the new layout the article is
divided into three panes, one for navigation, one for the core text and one
for supplementary and contextual information. Interactive tables, graphs and
other discipline specific tools have been brought into the text and make
that readers can drill down to underlying data [
Aalbersberg 2012].
Since December 2009 Portland Press has been using Utopia
Documents
[4] to enhance the content of their
Biochemical
Journal.
[5] A Utopia document is an
enhanced PDF file for which a special reader has to be downloaded. It
connects the static content of scientific articles to up-to-date online
information and allows a great variety of annotations made by the author or
publication editor. Currently, the publisher’s version of this software is
only available to Portland, but it is promised to be in time available more
widely [
Pettifer 2011].
BMC
Medicine, the flagship medical journal of the BioMed Central
series, has chosen a similar technological direction by including 3D models
in the PDF, benefiting from Acrobat options to embed interactive objects in
a PDF document. Because in this case standard technology is used, the
document is mostly accessible through regular PDF readers [
Ziegler 2011] (unfortunately, the iPad does not support these
advanced features).
The creation of RIPs has far-reaching consequences for the authoring and
publishing process. The production system must support the enhancements in
storage and layout and many journals have not (yet) chosen to move into this
direction; the regular PDF is the ubiquitous standard. This means that
authors will have no free choice regarding media rich publishing. The
selection of a journal will be based, rather, on more ponderous reasons like
ranking and readership than on this presentation aspect. A double track
solution is feasible by doing both, publishing the article in a highly
ranked journal to earn credits, and providing a text with supplementary
material through a private or institutional website to serve the community
of peers and to enhance visibility. One may consider this as an alternative
form of co-publishing, in which the efforts rather than the expenses are
shared — but with which technical means, and can it be done within a
reasonable amount of time? An ordinary HTML page is not a good solution,
precisely because of all the extra material. Think of a large set of photos,
an interactive map for display of research data or an interactive
spreadsheet. One needs special components to avoid a messy layout and to
provide a decent reading experience, which will require more technical
skills than we may expect from the average author.
An obvious channel for alternative communication is the research blog. In
general, bloggers do not see their blogs as appropriate outlets for original
research [
Puschmann 2012]; [
Kjellberg 2010],
which is also confirmed by a look at blogs in humanities studies. Scientific
blogging is often motivated by the need of sharing knowledge with a wider
public than the community of experts, to express opinions and start
discussions. Moreover, in terms of layout the blog genre is not geared to
extensive scientific discourse. However, the blogging software can be used
for other purposes as well. The popular WordPress package, which is used on
many blog sites, is also the basis of PressBooks
[6], a commercial website, which
presents itself as the simple way of web book publishing with PDF as extra
output option. WordPress itself has also themes (i.e. layout templates)
suitable for scholarly publishing as well as special components for
multimedia [
Jankowski 2009]; [
Tatum 2011].
Installation of the software does not require much technical knowledge.
Authoring can be done online, however, a drawback is that WordPress adds
additional codes to the HTML, which makes the source text less standard and
therefore more difficult to re-use.
A new platform with interesting architecture is Scalar [
Dietrich 2012]
[7], created by the Alliance for Networking Visual Culture and
is now available. It is a free, open source authoring and publishing
platform that is designed to write text online (or to copy and paste it from
an existing source). Scalar enables users to assemble media from multiple
sources and juxtapose them with their own writing in a variety of ways, with
minimal technical expertise required. Comments and annotations are also
supported. A user can easily switch between different views such as text
emphasis, media emphasis, metadata and various visualizations. Content
consists of pages and media, which can be related to each other in different
ways, which results in non-linear structures. Media can be imported from
online archives like Critical Commons, the Internet Archive, Flickr and
Vimeo. Scalar is a semantic web authoring tool that brings a balance between
standardization and structural flexibility to all kinds of material. Authors
familiar with WordPress will feel comfortable with the online authoring
process; an export option to other formats is not directly available, but
seems to be possible through the API
[8]
E-books
An offline alternative to the RIP is the modern e-book. In contrast to what
its name suggests an e-book does not need to be of the same substantial size
of a printed book because of the lack of overhead printing costs. The first
generation of e-books consisted mainly of texts with a few gray-scale
illustrations, and e-readers based on “electronic paper”
technology (e-ink) like Amazon’s Kindle could hardly display more, but this
is changing. Recently, e-books can be enriched roughly in the same way as
RIPs and e-reader software can be downloaded for all computers.
In fall 2011 Epub 3 was approved as recommendation
[9], which allows the embedding of audio and video together with some
scripting and makes interactivity possible. The great plus is that an Epub 3
document is a ZIP-file with only standard code inside: HTML5, CSS and
Javascript, which guarantees the reusability of the content. There are two
types of layout. Reflowable layout is default, which gives users a high
degree of control of the look and feel of the page; however, for the same
reason, it is more difficult for authors to make sure that multimedia appear
on the right position in the text. The alternative is fixed layout, which
sounds good, but is not yet very successfully implemented by reader
software.
Currently, the Epub 3 standard is not widely supported by publishers and
e-reader manufacturers, which makes that in practice one may come across
some annoying hitches. Apple offers extensive and good-looking support in
the form of its proprietary iBooks format. The text can be interspersed with
interactive images, image galleries, video and audio. Touch Press
[10] has already produced a set of impressive titles on popular
subjects such as the pyramids of Egypt in 3D, the work of Leonardo da Vinci
about human anatomy, and the march of the dinosaurs. Apple created a nice
authoring program, iBooks Author, which runs only on Apple devices, and the
same applies to the iBooks, which require an iPad. Conversion to PDF is
possible, but then all interactivity gets lost. Moreover, Apple requires
that iBooks files are only distributed through its own iBookstore unless the
work is free.
[11] So, the highly proprietary nature of this channel may
be an impediment to scholarly publishing, which is increasingly marked by
openness.
The Verdict: No Royal Highway
Conventional publishing is rather straightforward: there is a well-defined
path starting from a Word file or Lateχ document based on templates to an
HTML page and PDF. Enhanced publications add a linkage layer on top of this
existing system and require users to hop from one piece of content to
another. On the other hand, publishing an article in a digital format with
integrated research data, a set of photos, videos, interactive maps or
animations as with RIPs affects structure and layout of the publication
itself and requires new technology. Making a choice one has to avoid at
least four basic technical pitfalls:
-
Cluttering of the added content and thus creating an
aesthetically unacceptable document. We know that aesthetics do matter,
also because it influences credibility. Experiments have shown that
users can judge a web site's credibility in as little as 3.42 seconds
merely on the basis of its aesthetic appeal [Alsudani 2009]; [Phillips 2009]. This may be mitigated in a scientific
context, but the factor should not be neglected.
-
Information overload, which is closely related to the
previous point. The reader may not attach the same importance to the
extra information as the author did. Aside from the main line of
discourse the user should be given a choice with regard to content, e.g.
to view or to skip a chart, a model, a set of images or a video.
-
Format-device mismatch. Nowadays this easily happens with
the great variety of mobiles and diversity in screen resolutions. In the
good old days we were safe if our content stayed inside an area of
800x600 pixels. However, now we have got wide screens, tablets, iPad
minis, phablets, smartphones and more. Text should not “fall
off” the screen or be displayed with uncomfortably long
line length. The answer is responsive design, a relatively new
technology that allows a document to resize and to restructure depending
on the size of the screen on which it is being viewed, similar to the
reflowable layout of epub.
-
Proprietary solutions, because of a lack of openness (for
example for commercial reasons) or not adhering to standards. Creating a
scholarly publication requires a great deal of effort. If we can do it
once, in a standard format like HTML or XML, we can re-use it in its
entirety or parts of it, and automatically reformat it by means of XSLT.
Authors are lucky when their publisher has well organized the rich
publication route as for example Elsevier did. This implies more than
refreshing the journal system and providing updated templates. Careful
instructions are needed how to submit multimedia material and, in addition,
Elsevier offers a paid illustration service. Overlooking the various
alternatives for self-publishing as discussed in the foregoing sections one
must conclude that each of them has certain snags; there is no royal
highway. Most authors will either need technical assistance or have to
accept compromises; new, user-friendly tools are badly needed to fill the
gap between the low end of WYSIWYG HTML editors and blog publishing on the
one hand, and less flexible and less open full-fledged commercial systems on
the other.
2. Xpos’re as Cross-platform Solution
Background
The Xpos’re project has its roots in handcrafted multimedia web applications
for research purposes, mainly made in Flash.
[12] Just before Flash was banished from the tablet platform a wish
arose to make this kind of application more generic and author-friendly,
which resulted in the Xpos’re suite. The software does not solve all
problems identified above, but avoids at least most of the pitfalls
mentioned. Due to its background in multimedia applications the Xpos’re
suite allows the creation of publications with a well-structured aesthetic
layout. With regard to information overload: the layout concept encourages
(but not enforces) a style of writing that divides the text into small
sections, presenting essentials first followed by more detailed evidence.
The variety of hardware platforms and screen resolutions is addressed
through different output options, both fixed and more reflowable HTML
formats. Input and output is based on standards, XML, HTML and cascading
style sheets, which precludes any lock-in.
The Xpos’re software is free and is distributed under a non-commercial
Creative Commons license and can be downloaded from
http://xposre.nl which contains also a
few examples of real publications (note, that the illustrations in this
paper are based on a simple demo with brief pseudo-text kept short for the
sake of clarity).
Flash Text Browser with Extensions
The main component of the Xpos’re package is a text browser, a Flash program,
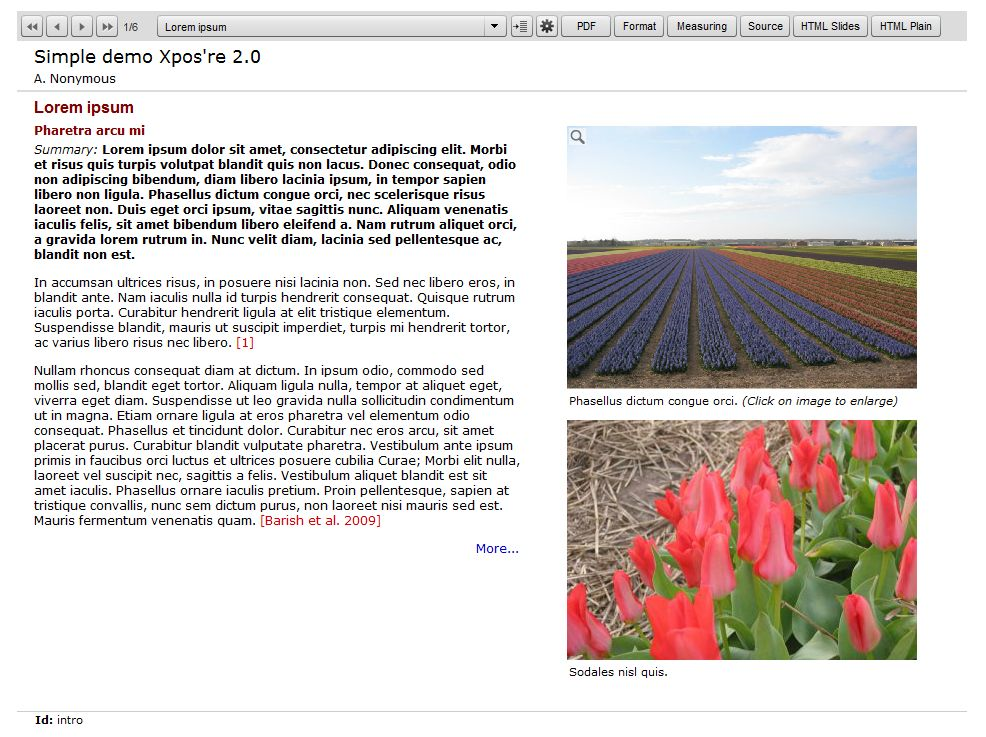
which primarily renders the text as a set of slides (see Figure 1) and which
delegates the display of specific, mostly multimedia content to external
components, the so-called extensions, which are similar to plug-ins of a web
browser. These enhancements (in Flash or HTML-Javascript) may vary from
zoomable images, image galleries, interactive maps, and videos to
interactive data tables and statistical charts. The extensions are different
in size, are launched through special event-hyperlinks and are displayed on
top of the main text. The native Xpos’re Flash extensions can also interact
through this type of links with the main text, for example, changing the
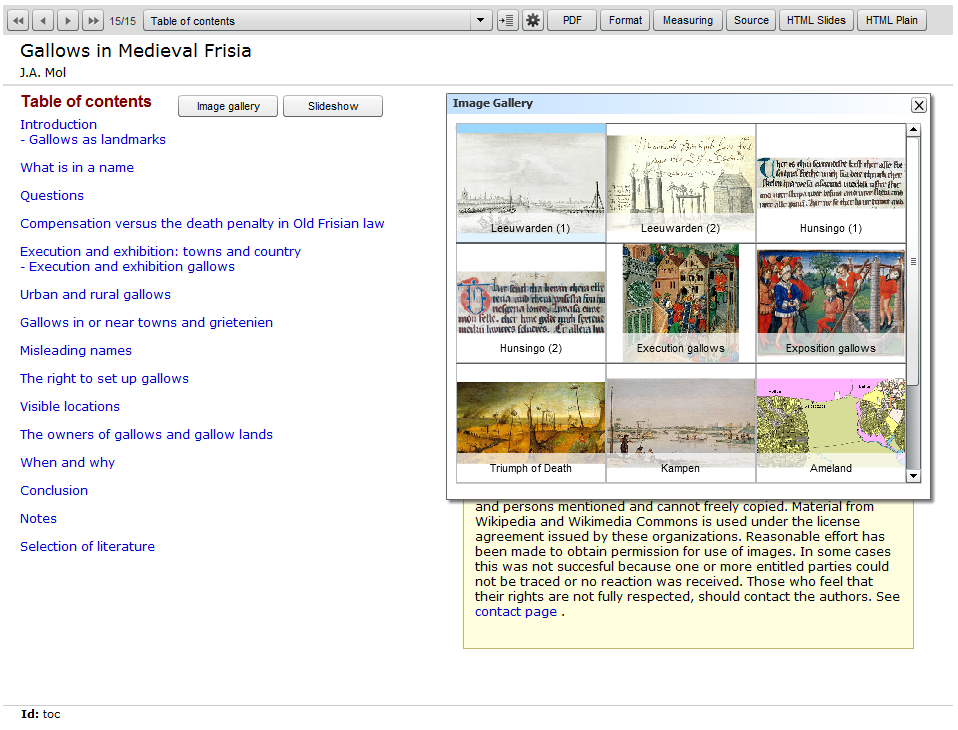
slide displayed. In this way an image gallery can be used as a pictorial
index through goto-event links in the captions of the gallery images; by
clicking on the event-link a user can go to the slide where the image is
discussed (see Figure 2). Xpos’re has been designed to work together with
other web tools. Particularly the statistical market segment has companion
software, which is worth to be used and, depending on the application
interface, can also be used with Xpos’re as a less integrated extension.
In the basic display format the publication is a series of slides, each
having a fixed layout of 950 x 720 pixels, which fits most common screens in
landscape mode. It is not responsive, but there are options for more
flexible HTML output, which we shall discuss later. A slide should
correspond with a piece of text that is internally coherent, such as a
section or subsection of an article. It may contain the full text or a
summary, for example, if the Xpos’re publication is mainly intended to make
supplementary material available. For this purpose each slide can be linked
to the related page in the PDF file with the full text; then the linked page
is displayed by a button click.
A slide can contain one or two text columns and images. Images are displayed
as a list outside the text blocks, unless, like in HTML, defined through an
img tag and thus embedded in the text itself. The number of
images that fit on a slide depends on the size and orientation of the image
list, horizontal or vertical. How physical text layout affects reading from
screen is a thorny debate, which has produced a large number of
unfortunately inconclusive and slightly contradictive studies [
Nimwegen 1999]; [
Dyson 2004]; [
Santosa 2011]. Conclusions have mostly favored short to medium
lines (about 60 characters per line), because longer lengths require greater
lateral eye movements, which makes reading more tiring [
Bernard 2002]. The Xpos’re slide format allows text columns in
this range.
The limited space does not necessarily restrict the amount of information
that can be displayed. If a text is larger than the predefined column, it is
scrollable, but choosing continuation text may be more user-friendly. A
slide can have one continuation text of unlimited length, in the Flash
version displayed in a popup window and in the HTML slide version as a new
screen. This helps to present main things first. Usability research has
shown that users prefer brief information before reading a full text and
appreciate facilities for rapid browsing [
Dillon 1989].
HTML Output and the HTML Reader
Flash was kept because of its robustness and high quality of accurate graphic
rendering, which has proven to be consistent on different platforms over a
long period of time. It should be emphasized that no content is embedded in
the Flash file itself (which is still a common misunderstanding with regard
to Flash applications): at startup all text and images are preloaded from
the web server to guarantee good performance.
However, the user is in no way bound to Flash and can easily switch to HTML
output. The Flash text browser contains a code generator, which
automatically creates a look-alike HTML version of the Flash slides with
similar functionality to serve platforms where Flash is not supported (such
as the iPad). In the same way it can produce a plain HTML version with a
minimum of formatting suitable for printing, conversion to PDF and further
processing such as the creation of e-books through software as
Calibre.
[13]
This flexible HTML document can also be manipulated and displayed by other
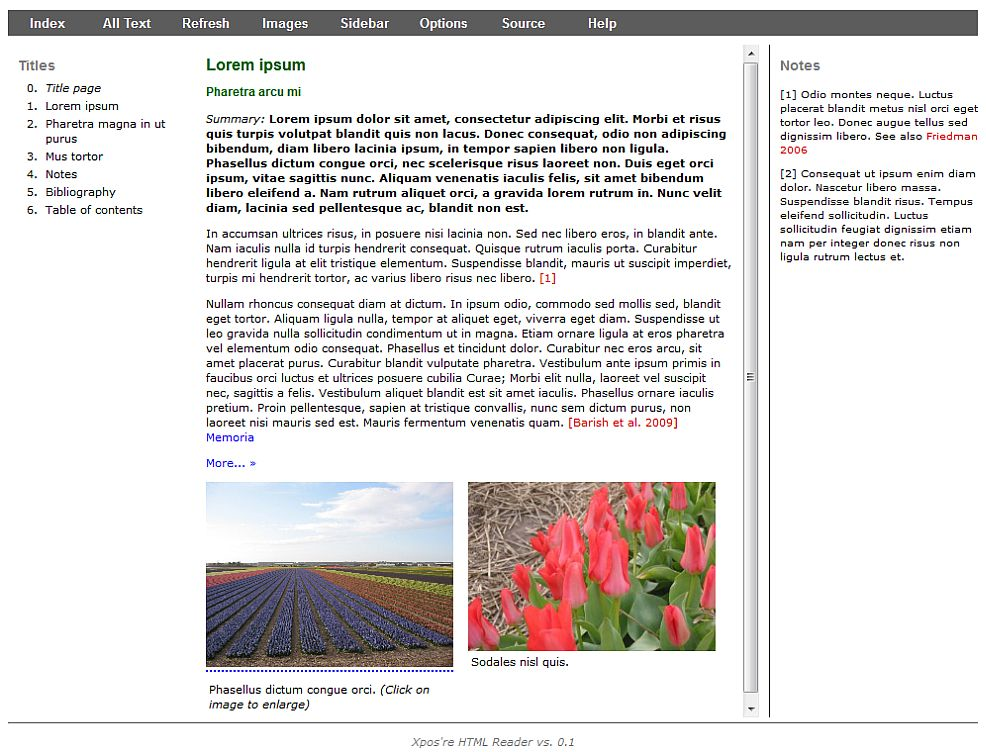
reader software. For example, the Xpos’re suite also comprises a highly
customizable HTML Reader, which displays this text in a three column
reflowable format (table of contents, main text and sidebar), similar to the
layout of most digital scientific journals. It has more features than the
automatically generated HTML slides and is particularly tablet friendly (see
Figure 3). An additional advantage of this reader is that it accepts also
other HTML texts (non-native XML) provided that basic formatting rules have
been followed.
The cross-platform concept also applies to extensions. An important principle
in the Xpos’re architecture is “gentle fallback”, which
guarantees that the content of Flash extensions is still displayed in the
HTML slide version if Flash is not supported on a certain hardware platform.
Although the HTML version can handle Flash extensions, the user may select
the fallback option to let the web browser use the XHTML source directly
(which is sufficiently formatted) instead of the better looking Flash
rendering.
3. Authoring a Publication
An Xpos’re publication consists of two main files: one containing the structured
publication text and one with metadata and instructions for the Xpos’re
software. A cascading style sheet (CSS) defines the layout in terms of colors,
font family and font size. XML has been chosen for the mark-up of the content.
The input must comply with an XML schema, which makes it easy to control and to
validate text entry. In many respects the Xpos’re XML vocabulary is close to
XHTML, particularly on the level of paragraph mark-up, but it contains non-HTML
instructions, among others, for the control of the extensions mentioned.
The most direct form of authoring boils down to alternating between an XML editor
and the Xpos’re text browser, which shows immediately how the document rendered
looks. If the XML document is created on the basis of an existing publication,
text entry will be a matter of copy and paste. Other, more (semi‑) automated
workflows, which start for example from a Word text, are feasible as well. A
Word document saved as a (filtered) HTML text can be further cleaned by
conversion tools
[14] and worked up to XML. This may be a more convenient way if an existing
text contains much mark-up (bold, italic et cetera) that is to be preserved.
This preprocessing stage could be more automated. A dedicated, task-oriented XML
editor with a word processor-like view such as XMLmind
[15] could simplify the authoring and
tweaking for those authors who are less familiar with the nuts and bolts of
XML.
The layout of each slide can fully meet the requirements of the particular
content. The author can choose on which level he defines the position and size
of the text and images. By default layout is controlled through user-defined
templates. The advantage of this template mechanism is that it allows global
changes for the entire text at once; modifying a template affects all the slides
that use it. In addition, fixed layout is not hard coded in the text itself and
may be even completely disregarded as, for example, with the reflowable HTML
output in the HTML reader.
<template id="vleft">
<text1 x="370" y="110" width="500" height="485">Maintext</text1>
<text2 x="370" y="595" width="500" height="100">Used as secondary text or text block</text2>
<visuals x="15" y="115" size="270" orientation="vertical">Vertical image list on the left side
with 'width' equal to 'size'</visual>
</template>
Example 2.
Example of a template. This template defines the layout for a slide with a
vertical list of images on the left, and two text blocks (text1 and text2)
on the right.
If required, the author can also locally specify precise size and position of
layout elements in the slide itself. A local specification precedes over the
template in use, in the same way as local style definitions have priority of a
linked style sheet in an HTML document. In this way images can also be
“pulled out of the list” and placed anywhere on the
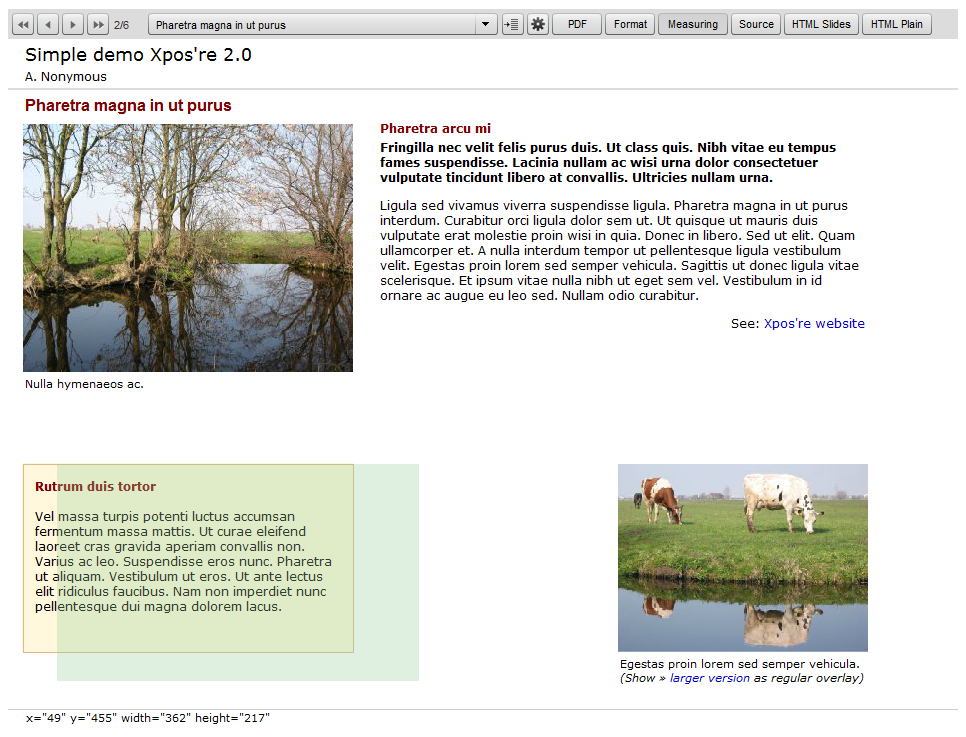
slide. For this purpose the text reader contains a so-called measuring tool (see
Figure 4), a transparent rectangle which can be drawn and resized by mouse and
arrow keys to make positioning and resizing of text and images easy. Each time
when the rectangle changes, its x, y, width and height are displayed at the
bottom of the slide in a format that can be copied and directly pasted into the
XML text. Although simple, this facility proves to be an effective compensation
for the fact that the text editing is not WYSIWYG.
Slide text may contain two kinds of hyperlinks: (1) regular HTML-hyperlinks and
(2) internal event-links, which represent instructions for the text browser.
Documents linked to the publication text through the former type of links are
displayed in a target window (just like in HTML), but Xpos’re can also show them
as an overlay on a transparent background on top of the slide, which creates a
sense of unity in the user interface. The second type of link is used, among
others, for navigation: <a href="event:goto#intro">Lorem
ipsum</a> will display the slide with the id-attribute having
the value “intro”. Another use is calling an extension. For example, the
image viewer can be activated to show a larger, zoomable version of a picture by
adding the tag: <a
href="event:add#ImageViewer.swf#Tulip_field.jpg". Extensions linked through event links appear as pop-ups in the
Flash text browser, and as overlays in the HTML look-alike.
When ready, the text with all depending files is copied to a webserver, which
completes the publishing process. There is no content management system or other
back-end required. When published, this RIP can be aggregated with other content
(e.g. related publications or data sets) into an enhanced publication. Xpos're
also supports the generation of an OAI-ORE resource map (see section 1.2), which
is automatically generated by means of an XSLT file, to be downloaded from the
Xpos're website.
4. Pilots
We did some small scale testing of the software in research projects. The
development of Xpos’re started as part of a larger collaboration project within
the Royal Netherlands Academy of Arts and Sciences and got national attention in
the context of enhanced publications. The combination of both attracted some
volunteers, who wanted either to add an Xpos’re publication to an already
published paper or to use the package for a new, born-digital product. This
resulted in four “showcases” about a diversity of subjects:
gallows in late medieval Frisia, a textual analysis of a Dutch novel, a
prototype for a Berber dictionary, and a rather long text (of the size of a
book) about parks and country houses in the Netherlands (the products and more
details are on Xpos’re website
[16]). In the first two cases the technical work was done by the developer of
Xpos’re; the Berber dictionary was implemented by a student in collaboration
with a computer scientist, and text about parks was converted to Xpos’re source
text by technical personnel of a university library, who had followed a short
XML course and got a workshop of two half days about Xpos’re.
In all four cases the content production process went smoothly. The Berber
dictionary, however, used a special text font, which required recompilation of
the Flash text browser. During the encoding of the book about parks we offered
some support for minor questions about image processing and how to create the
best layout. Using Xpos’re for such a long text raised questions about search
facilities, which are currently lacking in the text browser, because it was
designed with texts of article size in mind. Furthermore, we could observe a
tendency to stick to the basics and that more advanced features, such as the
plugins, were not easily used.
5. Conclusions
Scholarly communication is in a process of transition and has not yet arrived at
a steady state. Both users and publishers realize that the traditional genre of
printed papers, even in digital form, does not suffice any longer and feel the
need to publish supplements to the text. This has resulted in quite different
digital solutions, varying from a multimedia section on a journal web site to
enhanced PDF documents and semantic aggregations of articles plus other
resources, but for most authors the way is not yet paved. Given the current
state of scholarly publication, rich media publishing entails a set of
difficulties and inconveniences that have to be dealt with:
-
Lack of integration: Given the current state of scientific
publishing, multimedia material is often only loosely connected with the
publication itself. This will not be experienced as a problem by all authors
and readers, but it is to be considered as an issue against the background
of the rapidly increasing influence of visual and audio content in our
culture. The recent upswing of multimedia journalism is a good example of
this tendency. We are now easily able to show what for centuries could only
be described, but in practice there are still hurdles, particularly in the
publishing infrastructure itself.
-
Information overload: More and diverse content requires
adequate composition skills in combination with optional selection by the
user. Next to the information push of the publication itself we should leave
room for information pull: let readers select the details they like, just as
we do with an extensive footnote apparatus in printed publications. This
requires a slightly different style of writing and technical support in the
publication format.
-
High quality layout: The variety of media tends to make layout
more complex. Unless supported by a user-friendly authoring system or the
publisher’s design department, this may demand too much from the average
author.
-
Format-device mismatch: A uniform and consistent layout across
different devices, which have a great variety of screen resolutions and
idiosyncratic browser behavior, is an enormous challenge. So far only PDF
publications have been really successful on this point. Flash was a second
winner, but lost the battle on the mobile platform.
-
Proprietary solutions: The situation is certainly not hopeless;
however, some attractive solutions tend to be proprietary by not fully
adhering to standards and / or by vendor lock-in.
-
Lack of skills: Even if the technology in this field becomes
more user-friendly, authors should have more global technical knowledge and
basic skills to create a multimedia publication or to guide and to manage
its production by assistants.
The architectural concept of software has usually a much longer life than the
implementation, which is highly sensitive to changes in technology and market
positions. We all know spreadsheets, but only a few of us will remember Lotus
1-2-3, a highly popular spreadsheet and “killer application”
in the mid-1980s. Although the few pilots we did
[17] showed that that the software works well without hitches, the Xpos’re
tools may be best evaluated on basis of the architectural concept.
A major goal has been a good-looking layout that integrates different types of
content, much better than with the “content package” of the
enhanced publication. Aesthetically, the Flash version is often found most
attractive, also because the high graphic quality allows a pleasant information
density in a relative small screen space. In the fixed layout slides, text and
images can be precisely positioned. Other media types like interactive maps,
spreadsheets and video are so different in size that the same juxtaposition is
not possible as a generic solution. Extensions have been used instead, which are
displayed on top of the text and keep the context visible as much as possible.
The template mechanism encourages the predefinition of a layout model, which can
be both globally changed and locally overridden.
Information overload is discouraged by a combination of several features, which
leads to dividing the content into layers. The first layer is the text on the
slide, the next one the continuation text, and, if required, a third layer in
the form of a PDF page linked to the slide. In the HTML Reader the sidebar can
be used for digressions and short introductions of related subjects and videos
that do not fit in the main text.
The variety of devices and screen resolutions has been addressed to a certain
extent by a fixed layout that fits normal tablets and larger screens, and by the
flexible layout of the HTML Reader. A future version should be more responsive,
but downsizing for lower resolutions has its limits; hotspots as on an
interactive map or timeline require a minimum size and spacing on touch
devices.
The elements of the Xpos’re XML vocabulary are not standard, but the large
overlap with HTML for sentence and paragraph mark-up and the ease of
transformation of XML content make reuse relatively simple. A drawback is the
basic knowledge of HTML, XML and CSS required for authoring. This may be
inhibiting for scholars who want to stay far away from web technology; they will
need some technical assistance. The barrier is not as serious as it may appear.
In one of our pilots a large publication was rather easily encoded in XML by two
persons who had only attended a short basic XML workshop and got a one-day
instruction in Xpos’re software.
The Xpos’re architectural concept can be positioned between RIPs on basis content
management systems as WordPress and modern e-books. Although quite different in
many respects, all three of them are HTML-based and can be used to create
publications with enhanced reading experience. Unlike WordPress Xpos’re is a
completely client-side solution. The optional scripting in Epub 3 makes these
e-books in principle more versatile and powerful (and also more complex!) than
Xpos’re publications with extensions only. With regard to flexibility Xpos’re
stands out by an easily reusable source text and a variety of output options.
Works Cited
Aalbersberg 2012 Aalbersberg, IJ. J.,
Heeman, F., Koers, H. and Zudilova-Seinstra, E. “Elsevier’s
Article of the Future: enhancing the user experience and integrating data
through applications”, Insights, 25:1
(2012): 33–43, doi: 10.1629/2048-7754.25.1.33.
Alsudani 2009 Alsudani, F. and Casey, M. “The effect of aesthetics on web credibility”: Proceedings of the 23rd British HCI Group Annual Conference on
People and Computers: Celebrating People and Technology (BCS-HCI
'09). British Computer Society, Swinton, UK: 512-519 (2009).
Borgman 2007 Borgman, C. L. Scholarship in the Digital Age: Information, Infrastructure, and the
Internet. Cambridge (MA.): MIT Press (2007).
Breure 2011 Breure, L., Voorbij, H. and
Hoogerwerf, M. “Rich Internet Publications: ‘Show What You
Tell’
”,
Journal of Digital
Information, North America, 12:1 (2011). Available at:
http://journals.tdl.org/jodi/article/view/1606/1738. Date accessed:
April 26, 2012.
Dietrich 2012 Dietrich, C. and Sayers, J.
“After the Document Model for Scholarly Communication:
Some Considerations for Authoring with Rich Media”, Digital Studies / Le champs numériqe, 3:2
(2012).
Dillon 1989 Dillon, A., Richardson, J. and
McKnight, C. “The Human factors of journal usage and the
design of electronic text”, Interacting with
Computers 1:2 (1989): 183-189.
Force 11 Bourne, P.E., Clark, T., Dale, R., Waard, A.
de, Herman, I., Hovy, E.H. and Shotton, D. (Eds.)
Force11
White Paper: Improving The Future of Research Communications and
e-Scholarship. Available at:
http://force11.org/sites/default/files/book_attachments/Force11Manifesto20120219.pdf.
Date accessed: January 21, 2014.
Gerber 2009 Gerber, A. and Hunter, J. “A Compound Object Authoring and Publishing Tool for Literary
Scholars Based on the IFLA-FRBR Model”,
The
International Journal of Digital Curation 4:2 (2009): 28-42.
Available at:
http://www.ijdc.net/index.php/ijdc/article/view/116/119. Date
accessed: August 30, 2013.
Hunter 2007 Hunter, J. and Cheung, K. “Provenance Explorer – a graphical interface for constructing
scientific publication packages from provenance trails”,
International Journal on Digital Libraries 7:1-2
(2007): 99-107. Available at:
http://dx.doi.org/10.1007/s00799-007-0018-5. Date accessed: August
30, 2013.
Nimwegen 1999 Nimwegen, C. van, Pouw, M. and
Oostendorp, H. van “The influence of structure and
reading-manipulation on usability of hypertexts”, Interacting with Computers 12 (1999): 7–21.
Pettifer 2011 Pettifer, S., McDermott, P.,
Marsh, J., Thorne, D., Villeger, A. and Attwood, T.K. “Ceci
n’est pas un hamburger: modelling and representing the scholarly
article”,
Learned Publishing, 24
(2011):207–220. Available at:
http://dx.doi.org/10.1087/20110309. Date accessed: January 21, 2014.
Puschmann 2012 Puschmann, C. and Mahrt, M.
“Scholarly Blogging: A New Form of Publishing or Science
Journalism 2.0?” In A. Tokar et al. (Eds.) Science and the Internet, Düsseldorf (2012): 171-181.
Santosa 2011 Santosa, P. I. “User’s Preference of Web Page Length”, International Journal of Research and Reviews in Computer Science (IJRRCS)
2:1 (2011): 180-185.
Wouters 2012 Wouters, P., Beaulieu, A.,
Scharnhorst, A. and Wyatt, S. (Eds.) Virtual Knowledge:
Experimenting in the Humanities and the Social Sciences. MIT Press
(2012).
Ziegler 2011 Ziegler, A. et al. “Effectively incorporating selected multimedia content into
medical publications””,
BMC Medicine
9:17 (2011). Available at:
http://www.biomedcentral.com/1741-7015/9/17. Date accessed: August
30, 2013.