


Volume 8 Number 1
Computational Stylistic Analysis of Popular Songs of Japanese Female Singer-songwriters
Abstract
This study analyzes popular songs composed by Japanese female singer-songwriters. Popular songs are a good representation of modern culture and society. Songs by female singer-songwriters account for a large portion of the current Japanese hit charts and particularly play an important role in understanding the Japanese language and communication style. In this study, we applied new methods of computational stylistics to the lyrics of the songs. The results clearly show differences in the characteristics of 10 female singer-songwriters, and we found that the “visualization of the lyrics” is a typical characteristic of current singer-songwriters. Our findings provide an important case study for computational stylistics and can also be useful for understanding Japanese cultural trends.
Introduction
Data and Methods
Data
Statistical Methods
Results and Discussion
Basic Data for Selected Singer-songwriters
| Debut year | Debut age | |
| aiko | 1998 | 23 |
| Komi Hirose | 1992 | 26 |
| Yumi Matsutoya | 1973 | 18 |
| Miyuki Nakajima | 1975 | 23 |
| Maki Oguro | 1992 | 22 |
| Ai Otsuka | 2003 | 21 |
| Ringo Shina | 1998 | 19 |
| Mariya Takeuchi | 1978 | 23 |
| Hikaru Utada | 1998 | 15 |
| YUI | 2005 | 17 |
Basic Characteristics for Selected Songs
| number of tokens | ||||
| number of texts | mean | s.d. | c.v. | |
| aiko | 13 | 217.08 | 49.59 | 22.84 |
| Komi Hirose | 7 | 273.00 | 31.37 | 14.45 |
| Yumi Matsutoya | 13 | 155.31 | 40.51 | 18.66 |
| Miyuki Nakajima | 20 | 211.30 | 35.82 | 16.50 |
| Maki Oguro | 13 | 231.38 | 48.84 | 22.50 |
| Ai Otsuka | 15 | 209.33 | 49.99 | 23.03 |
| Ringo Shina | 9 | 199.78 | 46.19 | 21.28 |
| Mariya Takeuchi | 8 | 199.25 | 48.22 | 22.21 |
| Hikaru Utada | 20 | 235.70 | 51.69 | 23.81 |
| YUI | 10 | 243.10 | 68.61 | 31.61 |
Results on Kernel Principal Component Analysis (Kernel PCA)
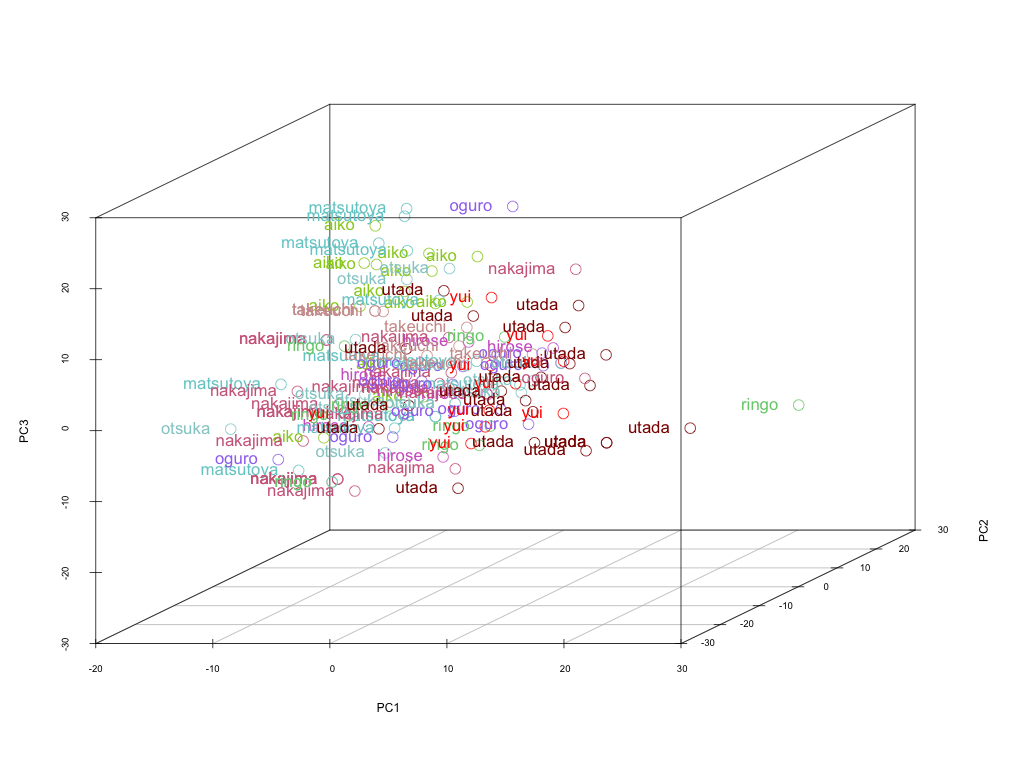

Results on Random Forests
| aiko | Komi Hirose | Yumi Matsutoya | Miyuki Nakajima | Maki Oguro | Ai Otsuka | Ringo Shina | Mariya Takeuchi | Hikaru Utada | YUI | error rates | |
| aiko | 13 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.00 |
| Komi Hirose | 0 | 0 | 0 | 4 | 0 | 0 | 0 | 0 | 3 | 0 | 1.00 |
| Yumi Matsutoya | 0 | 0 | 2 | 10 | 0 | 0 | 0 | 0 | 1 | 0 | 0.85 |
| Miyuki Nakajima | 0 | 0 | 0 | 19 | 0 | 0 | 0 | 0 | 1 | 0 | 0.05 |
| Maki Oguro | 0 | 0 | 1 | 1 | 1 | 2 | 0 | 0 | 8 | 0 | 0.92 |
| Ai Otsuka | 1 | 0 | 0 | 2 | 0 | 10 | 0 | 0 | 2 | 0 | 0.33 |
| Ringo Shina | 1 | 0 | 1 | 1 | 0 | 0 | 2 | 0 | 4 | 0 | 0.78 |
| Mariya Takeuchi | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 2 | 3 | 1 | 0.75 |
| Hikaru Utada | 0 | 0 | 0 | 3 | 0 | 0 | 0 | 0 | 17 | 0 | 0.15 |
| YUI | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5 | 5 | 0.50 |
| rank | morphemes | VIacu |
| 1 | atashi | 0.0125 |
| 2 | shi | 0.0078 |
| 3 | 1 | 0.0067 |
| 4 | watashi | 0.0059 |
| 5 | you | 0.0053 |
| 6 | da | 0.0052 |
| 7 | wo | 0.0050 |
| 8 | shiawase | 0.0047 |
| 9 | ta | 0.0045 |
| 10 | kimi | 0.0045 |
| 11 | nante | 0.0039 |
| 12 | ii | 0.0039 |
| 13 | e | 0.0038 |
| 14 | yo | 0.0036 |
| 15 | ai | 0.0032 |
| 16 | n | 0.0032 |
| 17 | tai | 0.0032 |
| 18 | nai | 0.0032 |
| 19 | kara | 0.0031 |
| 20 | koto | 0.0031 |
| old | new | error rates | |
| old | 11 | 30 | 0.73 |
| new | 0 | 87 | 0 |
| rank | morphemes | VIacu |
| 1 | wo | 0.00824 |
| 2 | watashi | 0.00819 |
| 3 | da | 0.00545 |
| 4 | ai | 0.00501 |
| 5 | hitori | 0.00478 |
| 6 | ha | 0.00420 |
| 7 | nagare | 0.00375 |
| 8 | shi | 0.00306 |
| 9 | tai | 0.00302 |
| 10 | atashi | 0.00290 |
| 11 | ? | 0.00287 |
| 12 | koto | 0.00232 |
| 13 | tachi | 0.00188 |
| 14 | hitotsu | 0.00187 |
| 15 | machikado | 0.00185 |
| 16 | hitomi | 0.00174 |
| 17 | n | 0.00162 |
| 18 | no | 0.00154 |
| 19 | chigai | 0.00138 |
| 20 | yuku | 0.00136 |
| aiko | Komi Hirose | Yumi Matsutoya | Miyuki Nakajima | Maki Oguro | ||||||
| rank | morphemes | VIacu | morphemes | VIacu | morphemes | VIacu | morphemes | VIacu | morphemes | VIacu |
| 1 | atashi | 0.0558 | Love | 0.0124 | wo | 0.0193 | shi | 0.0261 | shi | 0.0058 |
| 2 | you | 0.0379 | hito | 0.0111 | ai | 0.0092 | da | 0.0202 | kara | 0.0043 |
| 3 | koto (kanji) | 0.0227 | eien | 0.0073 | atashi | 0.0076 | e | 0.0178 | atashi | 0.0040 |
| 4 | hodo | 0.0077 | watashi | 0.0072 | da | 0.0073 | yo | 0.0151 | you | 0.0039 |
| 5 | watashi | 0.0065 | kimi | 0.0049 | ja | 0.0072 | atashi | 0.0133 | kako | 0.0034 |
| 6 | hikari | 0.0063 | ni | 0.0043 | nante | 0.0059 | tai | 0.0127 | ni | 0.0027 |
| 7 | me | 0.0061 | wo | 0.0036 | mi | 0.0055 | tachi | 0.0116 | suru | 0.0024 |
| 8 | hoho | 0.0055 | wa | 0.0035 | watashi | 0.0052 | ni | 0.0098 | wo | 0.0023 |
| 9 | mo | 0.0051 | cha | 0.0035 | kimi | 0.0050 | wo | 0.0080 | 1 | 0.0020 |
| 10 | omoi | 0.0049 | purezento | 0.0034 | nai | 0.0044 | watashi | 0.0078 | kimi | 0.0018 |
| 11 | hure | 0.0042 | kitto | 0.0030 | ba | 0.0038 | ta | 0.0076 | u | 0.0017 |
| 12 | shi | 0.0039 | shi | 0.0030 | ii | 0.0035 | ii | 0.0072 | mi | 0.0016 |
| 13 | ta | 0.0038 | atashi | 0.0028 | omoi | 0.0033 | wa | 0.0068 | datte | 0.0015 |
| 14 | kuchibiru | 0.0037 | kure | 0.0027 | toki | 0.0032 | kara | 0.0063 | n | 0.0014 |
| 15 | ai | 0.0032 | ta | 0.0026 | koto (hiragana) | 0.0032 | hito | 0.0061 | mata | 0.0013 |
| 16 | ... | 0.0028 | nante | 0.0024 | suru | 0.0031 | ? | 0.0060 | ga | 0.0013 |
| 17 | anata | 0.0027 | chaa | 0.0023 | toki | 0.0029 | mo | 0.0057 | sukoshi | 0.0013 |
| 18 | ii | 0.0025 | ga | 0.0022 | e | 0.0028 | n | 0.0054 | ai | 0.0012 |
| 19 | datte | 0.0024 | shiawase | 0.0021 | yo | 0.0028 | nai | 0.0051 | yuku | 0.0012 |
| 20 | you | 0.0024 | ai | 0.0020 | shi | 0.0026 | anata | 0.0050 | shiawase | 0.0011 |
| Ai Otsuka | Ringo Shina | Mariya Takeuchi | Hikaru Utada | aiko | ||||||
| rank | morphemes | VIacu | morphemes | VIacu | morphemes | VIacu | morphemes | VIacu | morphemes | VIacu |
| 1 | 1 | 0.0439 | atashi | 0.0113 | watashi | 0.0143 | kimi | 0.0141 | nante | 0.0213 |
| 2 | shiawase | 0.0280 | i | 0.0106 | machi | 0.0123 | I | 0.0097 | desyo | 0.0165 |
| 3 | atashi | 0.0144 | da | 0.0103 | shi | 0.0117 | you | 0.0091 | n | 0.0109 |
| 4 | 2 | 0.0105 | ta | 0.0103 | koi | 0.0104 | ii | 0.0091 | ? | 0.0075 |
| 5 | watashi | 0.0099 | hito | 0.0086 | futari | 0.0097 | atashi | 0.0079 | no | 0.0074 |
| 6 | mo | 0.0073 | watashi | 0.0078 | omoi | 0.0078 | ' | 0.0069 | ta | 0.0072 |
| 7 | koto (katakana) | 0.0067 | sono | 0.0069 | da | 0.0074 | baby | 0.0062 | tte | 0.0065 |
| 8 | nai | 0.0066 | ii | 0.0062 | ta | 0.0072 | doko | 0.0058 | watashi | 0.0053 |
| 9 | wo | 0.0063 | desyo | 0.0052 | ii | 0.0068 | n | 0.0053 | nai | 0.0050 |
| 10 | da | 0.0063 | nante | 0.0051 | wo | 0.0065 | shi | 0.0047 | waka | 0.0044 |
| 11 | suru | 0.0063 | you | 0.0051 | atashi | 0.0063 | anata | 0.0041 | hito | 0.0040 |
| 12 | shi | 0.0062 | seimei | 0.0048 | deatt | 0.0061 | te | 0.0041 | deki | 0.0039 |
| 13 | kimi | 0.0059 | re | 0.0045 | kanji | 0.0058 | nai | 0.0036 | da | 0.0037 |
| 14 | naa | 0.0055 | wo | 0.0043 | ' | 0.0053 | kokoro | 0.0033 | atashi | 0.0037 |
| 15 | nante | 0.0054 | kimi | 0.0043 | wa | 0.0053 | ai | 0.0033 | wo | 0.0036 |
| 16 | to | 0.0052 | tai | 0.0040 | hontou | 0.0052 | can | 0.0030 | mo | 0.0030 |
| 17 | tai | 0.0052 | kokoro | 0.0040 | tai | 0.0049 | shiawase | 0.0028 | yoru | 0.0029 |
| 18 | ai | 0.0050 | nado | 0.0038 | nai | 0.0046 | toki | 0.0026 | ja | 0.0028 |
| 19 | mi | 0.0047 | te | 0.0037 | eran | 0.0044 | sukoshi | 0.0026 | tai | 0.0027 |
| 20 | na | 0.0044 | yo | 0.0036 | denwa | 0.0043 | datte | 0.0025 | anata | 0.0024 |
Discussion of Individual Singer-Songwriters
aiko
Kohmi Hirose
Yumi Matsutoya
Miyuki Nakajima
Maki Ohguro
Ai Otsuka
Sheena Ringo
Mariya Takeuchi
Hikaru Utada
YUI
Further Discussion
Conclusion
Notes
Works Cited

Comments: dhqinfo@digitalhumanities.org
Published by: The Alliance of Digital Humanities Organizations and The Association for Computers and the Humanities
Affiliated with: Digital Scholarship in the Humanities
DHQ has been made possible in part by the National Endowment for the Humanities.
Copyright © 2005 -

Unless otherwise noted, the DHQ web site and all DHQ published content are published under a Creative Commons Attribution-NoDerivatives 4.0 International License. Individual articles may carry a more permissive license, as described in the footer for the individual article, and in the article’s metadata.
