Works Cited
Agosti et al. 1993 Agosti, Giacomo, Maria Elisabetta
Manca, Matteo Panzeri, and Marisa Dalai Emiliani (eds.). (1993). Giovanni Morelli e la cultura dei conoscitori: atti del convegno internazionale,
Bergamo, 4-7 giugno 1987. Bergamo: P. Lubrina.
Anderson 2020 Anderson, Jaynie. (2020). The Life of Giovanni Morelli in Risorgimento Italy (Milan:
Officina Libraria).
Bambach 2019 Bambach, Carmen (2019). Leonardo da Vinci Rediscovered (New Haven and London: Yale
University Press).
Barni 2016 Barni, Daniele. (2016). Lo sguardo della critica: i conoscitori d'arte in Italia tra XIX e XX
secolo (Turin: Cartman).
Beazley 1922 Beazley, John Davidson (1922). “Citharoedus,”
The Journal of Hellenic Studies 42, 70-98.
Beazley 1942 Beazley, John Davidson (1942). Attic Red-Figure Vase-Painters, 3 volumes (Oxford, Clarendon
Press).
Beazley 1956 Beazley, John Davidson (1956). Attic Black-Figure Vase-Painters (Oxford, Clarendon Press).
Beazley 1971 Beazley, John Davidson (1971). Paralipomena: Additions to Attic Black-Figure Vase-Painters and to
Attic Red-figure Vase-painters (Oxford: Oxford University Press).
Berg and Seeber 2016 Berg, Maggie and Barbara K. Seeber.
(2016).The Slow Professor: Challenging the Culture of Speed
in the Academy (Toronto, University of Toronto Press).
Berg-Fulton et al. 2018 Berg-Fulton, Tracey,
Alison Langmead, Thomas Lombardi, David Newbury, and Christopher Nygren. (2018).
“A Role-Based Model for Successful Collaboration in Digital
Art History.”
International Journal for Digital Art History, 3,
152-80. DOI:
https://doi.org/10.11588/dah.2018.3.34297.
Box 1979 Box, George. (1979). “Robustness in the Strategy of Scientific Model Building: Technical Report
#1954.” Madison, Wisconsin: Mathematics Research Center, University of
Wisconsin-Madison.
https://apps.dtic.mil/dtic/tr/fulltext/u2/a070213.pdf, accessed June 29,
2020.
Caglioti et. al. 2018 Caglioti, Francesco, Andrea De
Marchi, and Alessandro Nova (eds.). (2018). I Conoscitori
Tedeschi Tra Otto E Novecento, edited by, (Milan: Officina
Libraria)
Cantwell Smith 2019 Cantwell Smith, Brian.
(2019). The Promise of Artificial Intelligence: Reckoning and
Judgment. Cambridge and London: MIT Press.
Carrier 2003 Carrier, David. (2003). “In Praise of Connoisseurship.”
The Journal of Aesthetics and Art Criticism, 61,
159-69.
Chun 2011 Chun, Wendy Hui Kyong. (2011). Programmed Visions: Software and Memory (Cambridge: MIT
Press).
Davis 2011 Davis, Whitney. (2011). A General Theory of Visual Culture (Princeton: Princeton University
Press).
Driscoll 2019 Driscoll, Eric. (2019). “Beazley’s Connoisseurship: Aesthetics, Natural History, and Artistic
Development,” in
Dossier. Corps antiques: morceaux
choisis, edited by Florence Gherchanoc and Stéphanie Wyler (Paris:
Éditions de l’École des hautes études en sciences sociales): 101-120,
http://books.openedition.org/editionsehess/13689, accessed July 1, 2020.
Elgammal et al. 2018 Elgammal, Ahmed, Yan Kang, and
Milko Den Leeuw. (April 2018). “Picasso, Matisse, or a Fake?
Automated Analysis of Drawings at the Stroke Level for Attribution and
Authentication.”
Proceedings of the Thirty-Second AAAI Conference on Artificial
Intelligence (AAAI-18), 42-50.
https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/view/17356/15669,
accessed June 29, 2020.
Ellis and Johnson Jr. 2019 Ellis, Margaret Holben and
C. Richard Johnson Jr. (2019). “Computational Connoisseurship:
Enhanced Examination Using Automated Image Analysis.”
Visual Resources, 35, 125-140. DOI:
https://doi.org/10.1080/01973762.2019.1556886.
Floridi 2018 Floridi, Luciano. (2018). “Artificial Intelligence, Deepfakes and a Future of Ectypes.”
Philosophy & Technology, 31, 317-321.
Freedberg 1989 Freedberg, Sydney J. (1989). “Some Thoughts on Berenson, Connoisseurship, and the History of
Art.”
I Tatti Studies in the Italian Renaissance, 3, 11-26.
Freedberg 2006 Freedberg, David. (2006). “Why Connoisseurship Matters,” in Munuscula amicorum Contributions on Rubens and his Colleagues in Honour of Hans
Vlieghe, edited by K. Van der Stighelen (Turnhout: Brepols), 29-43.
Ginzburg 1980 Ginzburg, Carlo. (Spring 1980). “Morelli, Freud and Sherlock Holmes: Clues and Scientific
Method,” translated by Anna Davin. History
Workshop, 9, 5-36.
Golden 2004 Golden, Andrea. (2004). “Creating and Re-Creating: The Practice of Replication in the
Workshop of Giovanni Bellini,” in Giovanni Bellini and
the Art of Devotion, edited by Kasl, Ronda. (Indianapolis: Indianapolis
Museum of Art), 91-127.
Grabar 1988 Grabar, Oleg. (1988). “Between Connoisseurship and Technology: A Review.”
Muqarnas, 5, 1-8.
Greenberg 1939 Greenberg, Clement. (Fall 1939).
“Avant-Garde and Kitsch.”
Partisan Review, 6, 34-49.
Hinojosa 2009 Hinojosa, Lynne Walhout. (2009).
“The Connoisseur and the Spiritual History of Art: Morelli and
Berenson,” in idem, The
Renaissance, English Cultural Nationalism, and Modernism, 1860–1920 (New
York: Palgrave Macmillan), 89-111.
Holmdahl and Buckee 2020 Holmdahl, Inga and Caroline
Buckee. (May 15, 2020). “Wrong but Useful — What Covid-19
Epidemiologic Models Can and Cannot Tell Us.”
The New England Journal of Medicine. DOI:
https://www.nejm.org/doi/full/10.1056/NEJMp2016822.
Jaskot 2019 Jaskot, Paul. (2019). “Digital Art History as the Social History of Art: Towards the Disciplinary
Relevance of Digital Methods.”
Visual Resources, 35, 21-33.
Kemp 2019 Kemp, Martin. (2019). Leonardo by Leonardo (New York: Callaway).
Langmead and Newbury 2020 Langmead, Alison and David
Newbury. (2020). “Pointers and Proxies: Thoughts on the
Computational Modeling of the Phenomenal World.” In The Routledge Companion to Digital Humanities and Art History, edited by
Kathryn Brown. London: Routledge, 358-373.
Lewis 2019 Lewis, Ben (2019). The
Last Leonardo: The Secret Lives of the World’s Most Expensive Painting.
London: Ballantine.
Luzón Marco 2000 Luzón Marco, José. (2000). “The Construction of Novelty in Computer Science Papers.”
Revista Alicantina de Estudios Ingleses, 13, 123-140.
https://core.ac.uk/download/pdf/16358965.pdf, accessed June 29,
2020.
Melius 2011 Melius, Jeremy. (2011). “Connoisseurship, Painting, and Personhood,”
Art History, 34, 288-309
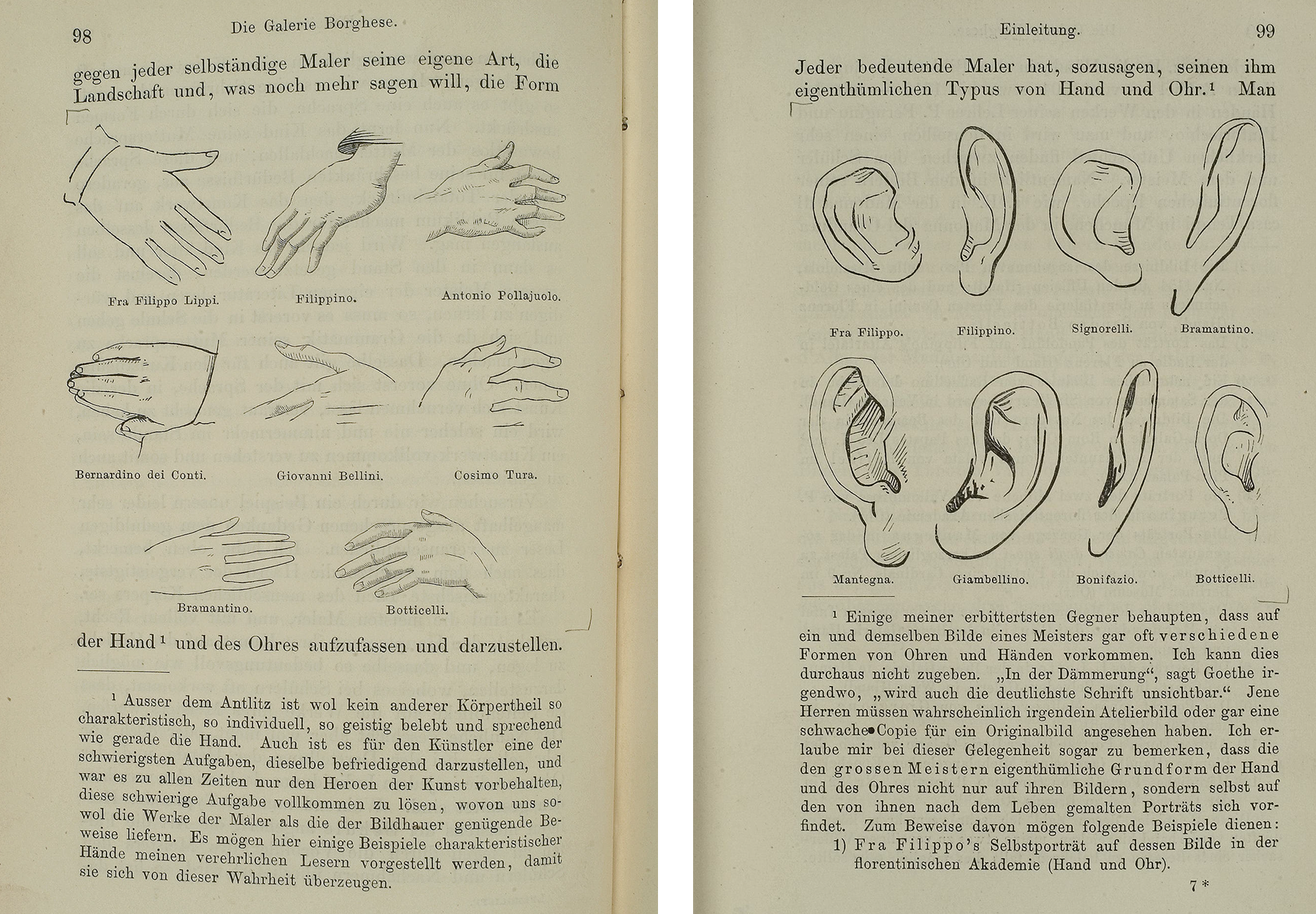
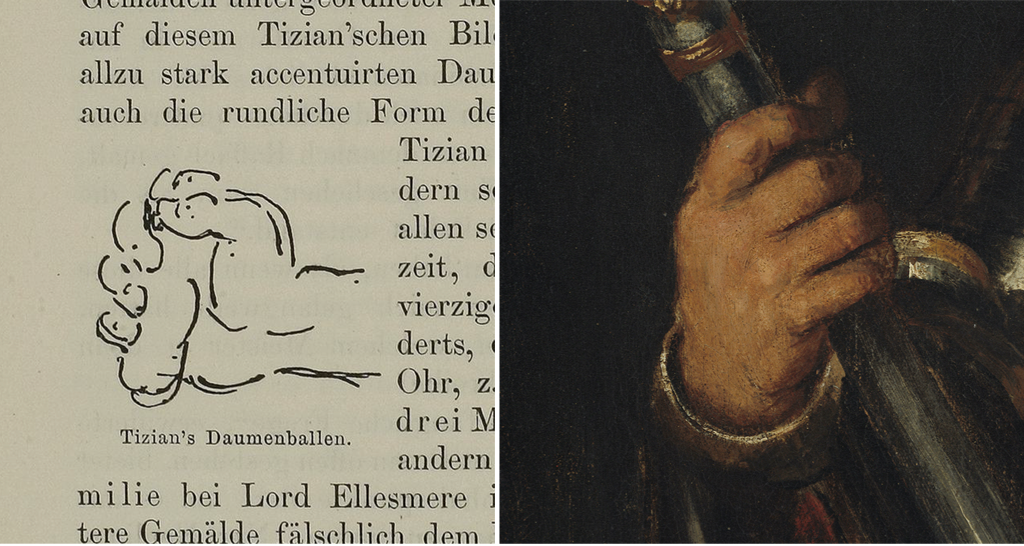
Morelli 1890 Morelli, Giovanni. (1890). Kunstkritische Studien über italienische Malerei; die Galerien
Borghese und Doria Panfili in Rom. (Leipzig F.A. Brockhaus).
Morelli 1893 Morelli, Giovanni. (1893). Italian Painters: Critical Studies of Their Works. By Giovanni
Morelli (Ivan Lermolieff). The Borghese and Doria-Pamphili Galleries in
Rome, translated by Constance Jocelyn Ffoulkes (London: John Murray).
Neer 2005 Neer, Richard. (2005). “Connoisseurship and the Stakes of Style,”
Critical Inquiry, 32, 1-26.
Neilson 2019 Neilson, Christina. (2019). Practice & Theory in the Italian Renaissance Workshop:
Verrocchio and the Epistemology of Making Art (Cambridge: Cambridge
University Press).
Opperman 1990 Opperman, Hal. (1990). “The Thinking Eye, the Mind That Sees: The Art Historian as
Connoisseur.”
Artibus Et Historiae, 11, 9-13.
O’Malley 2007 Michelle O’Malley. (2007). “Quality, Demand, and the Pressures of Reputation: Rethinking
Perugino.”
Art Bulletin 89, 674-693.
Register et al. 2019 Register, Shilpa, Michelle
Brown, and Marjorie Lee White. (2019). “Using Healthcare
Simulation in Space Planning to Improve Efficiency and Effectiveness within the
Healthcare System,”
Health Systems, 8, no. 3 (2019): 184-189,
https://doi.org/10.1080/20476965.2019.1569482.
Rodriguez 2018 Rodriguez, Paul. (March 8, 2018).
“ECSS Workplan: The ‘Morelli Machine:’ A Proposal Testing
a Critical, Algorithmic Approach to Art History,” n.p.
Rodriguez 2019 Rodriguez, Paul. (December 18,
2019). Internal Team Report.
Rodriguez 2020a Rodriguez, Paul. (January 12,
2020). Internal Team Report.
Rodriguez 2020b Rodriguez, Paul. (January 17,
2020). Email Correspondence with the Team.
Rodriguez 2020c Rodriguez, Paul. (March 9, 2020).
Email Correspondence with the Team.
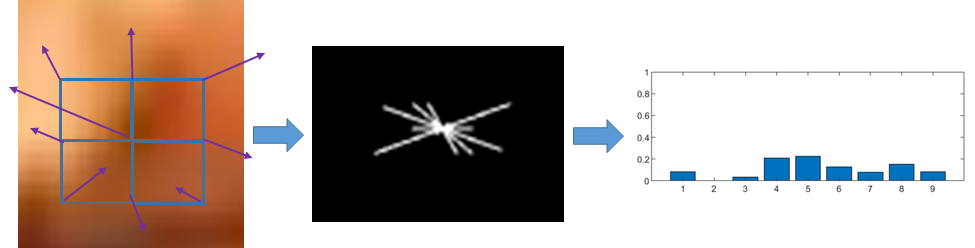
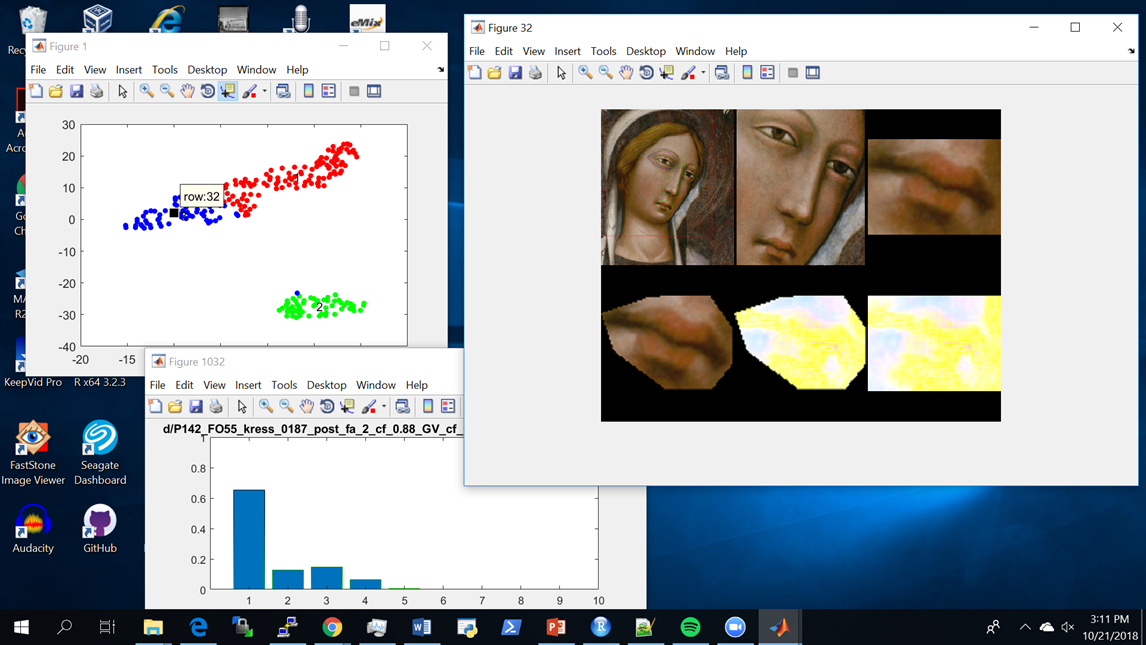
Rodriguez et al. 2020 Rodriguez, Paul, Alan
Craig, Alison Langmead, and Christopher J. Nygren. (2020). “Extracting and Analyzing Deep Learning Features for Discriminating Historical
Art.” In Proceedings of the Practice & Experience
in Advanced Research Computing Conference [PEARC] 2020 (Portland, OR) [in
publication].
Ryan 2009 Ryan, Adrian John. (January 2009). “Computer Aided Techniques for the Attribution of Attic Black-Figure
Vase-Paintings Using the Princeton Painter as a Model.” PhD dissertation,
University of Kwazulu-Natal, South Africa.
Scallen 2004 Scallen, Catherine B. (2004). Rembrandt, Reputation, and the Practice of Connoisseurship
(Amsterdam: Amsterdam University Press).
Shin 2019 Shin, Shin-Shing. (2019). “Empirical Study on the Effectiveness and Efficiency of Model-Driven Architecture
Techniques.”
Software & Systems Modeling, 18, 3083-3096. DOI:
https://doi.org/10.1007/s10270-018-00711-y.
Smith 2005 Smith, Tyler Jo. (2005). “The Beazley Archive: Inside and Out,”
Art Documentation: Journal of the Art Libraries Society of North
America, 24, 22-25.
Summers 1989 Summers, David. (1989). “‘Form,’ Nineteenth-Century Metaphysics, and the Problem of Art
Historical Description,”
Critical Inquiry, 15, 372-406.
Syson 2011 Syson, Luke, ed. (2011). Leonardo da Vinci: Painter at the Court of Milan (London:
National Gallery of Art).
Tishman 2017 Tishman, Shari. (2017). Slow Looking: The Art and Practice of Learning Through
Observation. Milton: Routledge.
Vaughan 1987 Vaughan, William. (1987). “The Automated Connoisseur: Image Analysis and Art History,”
in History and Computing, edited by Peter Denley and
Deian Hopkin (Manchester: Manchester University Press), 215-221.
Vaughan 1992 Vaughan, William. (1992). “Automated Picture Referencing: A Further Look at
‘Morelli,’”
Computers and the History of Art 2, no. 2, 7-18.
Williams 2017 Williams, Robert. (2017). Raphael and the Redefinition of Art in Renaissance Italy.
Cambridge: Cambridge University Press, 2017.
Wollheim 1973 Wollheim, Richard. (1973). “Giovanni Morelli and the Origins of Scientific
Connoisseurship.” In On Art and the Mind: Essays and
Lectures, by Richard Wollheim. London: Allen Lane, 177-201.
Wollheim 1979 Wollheim, Richard. (1979). “Pictorial Style: Two Views,” in The
Concept of Style, edited by Berel Lang (Philadelphia: University of
Pennsylvania Press), 129-145.
Wollheim 1995 Wollheim, Richard. (1995). “Style in Painting,” in The Question of
Style in Philosophy and the Arts, edited by Caroline Van Eck, James
McAllister and Renée van de Vall (Cambridge: Cambridge University Press, 1995),
37-49.
Zerner 2014 Henri Zerner. (2014). “What Gave Connoisseurship Its Bad Name? (1987),” reprinted in Historical Perspectives in the Conversation of Works of Art on
Paper, edited by Margaret Hoben Ellis (Los Angeles: The Getty Conservation
Institute), 59-61.
Zlabinger 2019 Zlabinger, Markus. (2019). “Improving the Annotation Efficiency and Effectiveness in the Text
Domain.” In
Advances in Information Retrieval, ECIR
2019, edited by L. Azzopardi, et al. Cham: Springer, 343-347. DOI:
https://doi.org/10.1007/978-3-030-15719-7_46.
van der Maaten 2013 van der Maaten, Laurens.
(June 24, 2013). “Visualizing Data Using t-SNE.”
Google Tech Talks, YouTube.
https://youtu.be/RJVL80Gg3lA, accessed
June 29, 2020.