Changing the Center of Gravity: Transforming Classical Studies Through Cyberinfrastructure
2009
Volume 3 Number 1
Abstract
The authors open by imagining one possible use of digital geographic techniques in
the context of humanities research in 2017. They then outline the background to this
vision, from early engagements in web-based mapping for the Classics to recent,
fast-paced developments in web-based, collaborative geography. The article concludes
with a description of their own Pleiades Project (http://pleiades.stoa.org), which gives
scholars, students and enthusiasts worldwide the opportunity to use, create and share
historical geographic information about the Greek and Roman World in digital
form.
The View From 2017
As I settle into my chair, a second cup of morning coffee in my hand, an expansive
view of the eastern Mediterranean fades in to cover the blank wall in front of me.
It's one of my favorite perspectives: from a viewpoint a thousand kilometers above
the Red Sea, you can look north and west across an expanse that encompasses Jordan,
Egypt and Libya in the foreground and Tunisia, Calabria and the Crimea along the
distorting arc of the horizon. A simple voice command clears some of my default
overlays: current precipitation and cloud cover, overnight news hotspots, and a
handful of icons that represent colleagues whose profiles indicate they're currently
at work. Now I see a new overlay of colored symbols associated with my current work:
various research projects, two articles I'm peer-reviewing and various other bits of
analysis, coding, writing and reading. These fade slowly to gray, but for two. Both
of them are sprawling, irregular splatters and clumps of dots, lines and polygonal
shapes.
The view pivots and zooms to frame these two symbol groups. The pink batch indicates
the footprint of one of the review pieces, a survey article comparing Greek, Roman
and Arabic land and sea itineraries. The other group, in pale blue, corresponds to my
own never-ending “Roman boundary disputes” project. In both cases, I've
previously tailored the display to map findspots of all texts and documents cited or
included, as well as all places named in notes or the cited modern texts and ancient
sources. These two sets of symbols remain highlighted because potentially relevant
information has recently appeared.
I suspect the “hits” for the boundary disputes are just articles in the latest
(nearly last) digitized Supplementband of the Pauly-Wissowa
Real-encyclopädie to be delivered to subscribing libraries...nothing
new from the old print version. I'll double-check that later. The more interesting
results are illustrated when I switch focus to the itineraries article I'm reviewing.
A new collection of colored symbols appear on the landscape, their intensity
automatically varied to indicate likely similarity to the selected article. One
particular subset jumps out at me: a series of bright red dots paralleling the
southern bank of the Danube. They are connected by line segments and join up with a
network of other points and lines that fan out northward into the space once occupied
by the Roman province of Dacia. A new and extensive Roman-era itinerary has been
discovered in Romania and published.
I can't resist making some quick explorations. It's easy enough to select the new
publication and ask for an extract of the itinerary's geography, as well as the place
names in their original orthographies. I follow up with a request for the results of
two correlation queries against all of the itineraries cited in the review article:
how similar are their geographies and how similar are their place names? My
programmatic research assistant reports back quickly: there's a strong correlation
between the sequential locations in a portion of the new document and an overlapping
portion of our only surviving copy of a Roman world map, the so-called “Peutinger
Map”, but the forms of several place names differ in some particulars.
[1] Another
intriguing result shows that the distances between nodal points in the new itinerary
are statistically consistent with those recorded in the Claudian-era inscribed
itinerary from Patara in Turkey, the so-called
Miliarium
Lyciae.
[2] I bundle up these results and the new
article, and add them to the review project. I can attach a short note to the author
about it later.
But now it's time to teach. Another voice command stores the research stuff and
clears the projected display, which reforms in two parts: another virtual globe
draped with the day's lecture materials, and a largely empty grid destined to be
slowly populated over the next half-hour by the various icons, avatars and video
images of my students. I double-check that I'm set to do-not-disturb and lean back to
review my lecture notes. Today, Caesar will cross the Rubicon.
The View, Explained (and what we have left out)
We've taken an equally imagined, but less frenetic, view of the scholarly future a
decade from now as that recently sketched for freelance business consultants by [
Sterling 2007]. Nonetheless, we share with Sterling a number of common
assumptions about the ways in which location will alter our next-decade information
experiences, both at work and in private life. We envision a 2017 in which the
geo-computing revolution, now underway, has intersected with other computational and
societal trends to effect major changes in the way humanist scholars work, publish
and teach. The rapid developments occurring at the intersection of geographic
computing and web-based information technology cannot be identified with any single
label, nor are they effectively described by any single body of academic literature.
A variety of terms are in use for one or another aspect of this domain, including
“web mapping”, “neogeography”, “social cartography”, “the
geoweb”, “webGIS” and “volunteered geographic information”. Those
unfamiliar with this fast-moving field – one in which speculation and innovation are
widespread – will gain some appreciation of its breadth and heterogeneity if they
start their reading with [
Turner 2006], [
Goodchild 2007],
[
Boll 2008] and [
Hudson-Smith 2008].
[3]
For humanists, general research tasks will remain largely unchanged: the discovery,
organization and analysis of primary and secondary materials with the goal of
communicating and disseminating results and information for the use and education of
others.
[4] But we expect to see a more broadly
collaborative regime in which a far greater percentage of work time is spent in
analysis and professional communication, all underpinned by a pervasive, always-on
network. Much of the tedious and solitary work of text mining, bibliographic research
and information management will be handled by computational agents, but we will
become more responsible for the quality and effectiveness of that work by virtue of
how we publish our research results. Ubiquitous, less-obtrusive software will respond
to our specific queries, and to the interests implied in our past searches, stored
documents, cited literature and recently used datasets. The information offered us in
return will be drawn from a global pastiche of digital repositories and publication
mechanisms, surfacing virtually all new academic publication, as well as digital
proxies for much of the printed, graphic and audio works now for sale, in circulation
or on exhibit in one or more first-world, brick-and-mortar bookstores, libraries or
museums.
It would be impossible in an article-length treatment to produce a comprehensive
history of geography and the classics, digital or otherwise. The non-digital,
cartographic achievements of the field to 1990 were surveyed in detail by [
Talbert 1992]. Many of the projects discussed then have continued,
diversified or gone digital, but there has not been to our knowledge a more recent
survey. Developments on the complementary methodological axis of “Historical
GIS” have been addressed recently in [
Gregory 2002], [
Knowles 2002] and [
Knowles 2008].
[5] No
conference series, journal or research center has yet been able to establish the
necessary international reporting linkages to provide a regular review of classical
geographical research (digital or otherwise), an increasingly urgent need in a
rapidly growing subfield.
Readers will detect this gap (and the compounding effects of limited space and time)
in three regrettable categories of omission. Firstly, we have been unable to address
many important comparanda for other periods, cultures and disciplines, for example
the China Historical GIS (
http://www.fas.harvard.edu/~chgis/), the AfricaMap Project (
http://isites.harvard.edu/icb/icb.do?keyword=k28501), both spearheaded
by Harvard's Center for Geographic Analysis. Secondly, our examples here are heavily
weighted toward the English-speaking world; we have not been able to address such
seminal efforts as the
Türkiye Arkeolojik
Yerleşmeleri (TAY) Projesi (Archaeological Settlements of Turkey
Project:
http://tayproject.org/). Finally,
we cannot possibly grapple in this article with the burgeoning practice of GIS and
remote sensing for large-scale site archaeology and regional survey, though we can
point to examples of projects seeking to facilitate aggregation, preservation and
discovery of related data, including FastiOnline (
http://www.fastionline.org/), the
Mediterranean Archaeological GIS (
http://cgma.depauw.edu/MAGIS/) and OpenContext (
http://opencontext.org/).
On the other hand, the initial impact on historical work of the publication in 2000
of the
Barrington Atlas of the Greek and Roman World (R.
Talbert, ed., Princeton) has been assessed by a number of reviews in major journals,
and significant works have since appeared that take it as the reference basis for
classical geographic features (e.g., [
Hansen 2004]). Planning for a
digital, user-friendly version of the Atlas continues as an area of active discussion
between the Ancient World Mapping Center at the University of North Carolina in
Chapel Hill (
http://www.unc.edu/awmc) and
other parties. Meanwhile, the analog and digital materials that underpinned
publication of the Atlas are the present focus of the authors' Pleiades project (see
further, below).
The Primacy of Location: A Recent Example Drawn from Google
The ability to identify and locate relevant items of interest is of prime importance
to users of scholarly information systems, and geography is a core axis of interest.
As Buckland and Lancaster put it in their 2004 D-Lib Magazine article:
The most fundamental advantage of the
emerging networked knowledge environment is that it provides a much-improved
technological basis for sharing resources of all sorts from all sources. This
situation increases the importance of effective access to information. Place,
along with time, topic, and creator, is one of the fundamental components in
how we define things and search for them.
[Buckland 2004]
Indeed, to realize the vision we have outlined above, spatial information must
become as easily searched — within, between and outside individual digital libraries
— as HTML web pages are today. The Googlebot began crawling and indexing web-posted
documents encoded in the Keyhole Markup Language (KML;
http://en.wikipedia.org/wiki/Keyhole_Markup_Language), as well as web
feeds containing GeoRSS markup (
http://en.wikipedia.org/wiki/Georss) in late 2006 [
Ohazama 2007]; [
Schutzberg 2007]. Microsoft added similar
support to its Local Search and Virtual Earth services in October 2007 (GeoWeb
Exploration 2007). It is already safe to say that this is now a routine function for
viable web search services. Henceforth, KML and GeoRSS resources on the Web will be
found and indexed if they are surfaced via stable, discoverable URLs.
Obviously, much of the information that the web search providers seek to index is not
in one of these geospatial formats. To determine the geographic relevance of
web-facing content in HTML, MSWord and PDF files and the like, a process called
geoparsing must be employed cf. [
Hill 2006, 220]. Geoparsing
entails first a series of steps, often called collectively “named entity
recognition”, in which proper nouns in unstructured or semi-structured texts
are disambiguated from other words and then associated with known or notional
entities of interest (e.g., places, persons, concepts). The potential of course
exists for false identifications, ambiguous matches (i.e., one name for many discrete
entities) and complete failures (e.g., due to the obscurity of a name or a referenced
entity). Assuming some level of success in disambiguation and identification of
geographic entities in a text, the next step is to associate coordinates with each
named entity. Unless the textual source is itself a geographic gazetteer containing
map coordinates that can be parsed accurately, the coordinates must be supplied from
an external reference dataset that ideally holds the exact name variants occurring in
the text as well as the geospatial coordinates; we must recognize that it will often
be the case, especially with regard to primary sources and academic literature on
historical topics, that such a reference dataset does not exist. Nonetheless, once
coordinates are assigned to as many entities as possible, and the results are stored
in an index with a link to the original document, mapping, geosearch and other
geographic computations can be performed.
[6]
Despite clear challenges and the real possibility of incomplete results for many
texts (we shall consider an example below), we believe that geoparsing-based services
will mature and diversify rapidly. By 2017, we expect that all web-facing textual
resources will be parsed (rightly or wrongly) for geographic content. Audio and video
works, where these can be machine-transcribed, will receive similar treatment,
whether they are accompanied by extensive metadata or not. Some texts, especially
those produced by academics and specialist communities will have coordinates encoded
into the digital texts in a way that facilitates automatic extraction, making their
geographic indexing relatively simple (e.g., KML, GeoRSS or the like). The majority
of texts, however, will still have only geographic names and geographic description,
most with neither special tagging nor authority control. The search engines will
automatically identify these components and add associated entries to their
geographic indexes by matching them with coordinate data in reference datasets. We
believe that these datasets will include information drawn from KML and
GeoRSS-enabled documents on the web, as well as previously geo-parsed texts
(especially those whose genre, topic and regional nature are easily identified using
automated techniques). Topic- and genre-aware geoparsing may well prove essential to
accurate disambiguation of non-unique place names.
The first fruits of geographic search are already apparent in information sets being
surfaced to the web. Consider, for example, Google Books. A copy of J.S. Watson's
1854 translation of Xenophon's
Anabasis was digitized at
Harvard in June 2006. Bundled into the original print work by the publisher was
W.F. Ainsworth's geographical commentary (pp. 263-338). Google's
“About this book” page demonstrates the range of connections the search
company's software is so far able to make between the book and other
resources.
[7] Basic bibliographic metadata is surfaced, along
with direct links to a downloadable PDF file and the Google book reader application
(and thence to the optically-recognized text itself). A variety of links to other
services are also provided (e.g., Amazon and OCLC WorldCat). Of chief interest in the
present discussion are the geographic components introduced under the heading
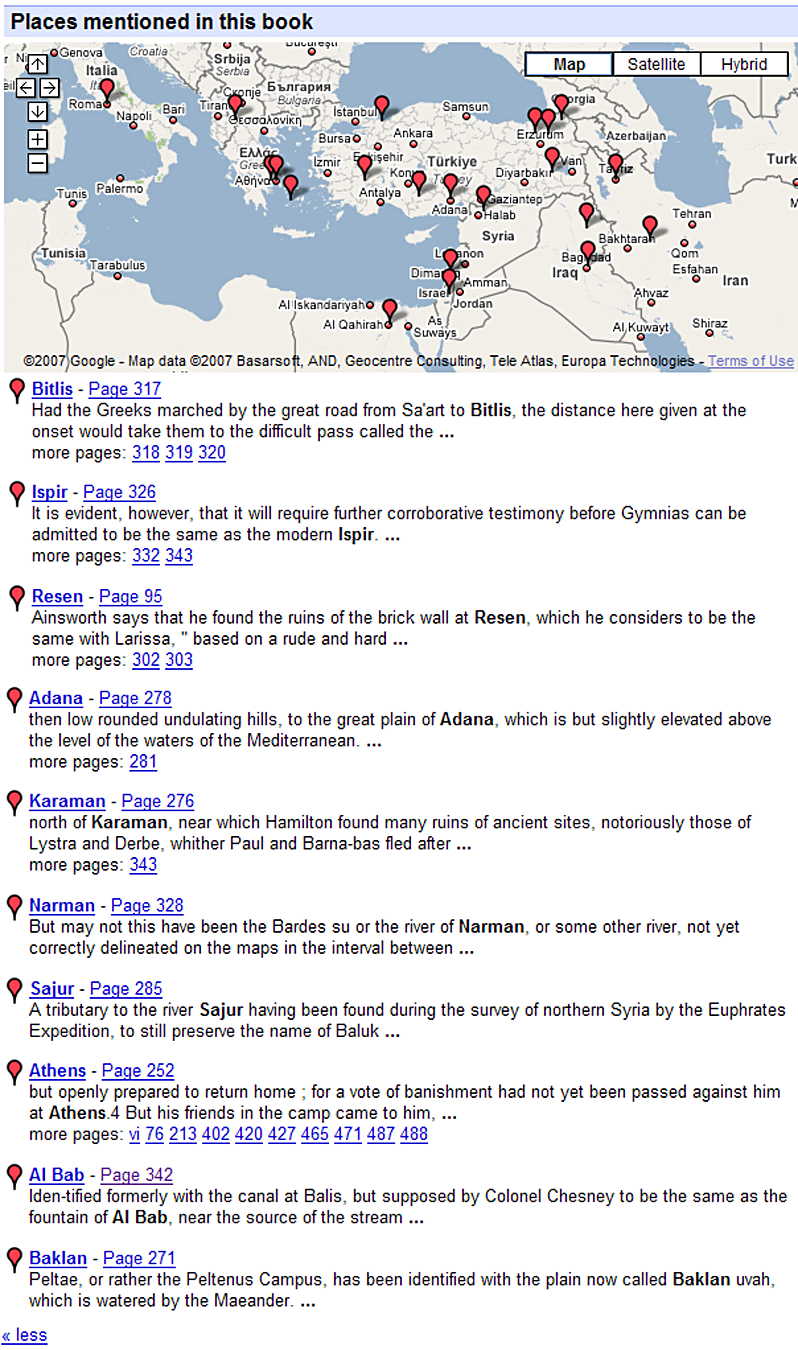
“Places mentioned in this book.” These consist at present of a map and an
index of select places, as illustrated in
Figure 1.
It would appear that most of the “places” currently highlighted in the Google
Books presentation (evidently a maximum of 10) have been parsed from Ainsworth's
commentary or the unattributed “Geographical Index”, which we assume to be
Watson's (pp. 339 - 348). As is the case with many Google search results, we are
given no information about how the indexing or correlation with geographic
coordinates (i.e., the geo-parsing) was accomplished. Some of the results are mapped
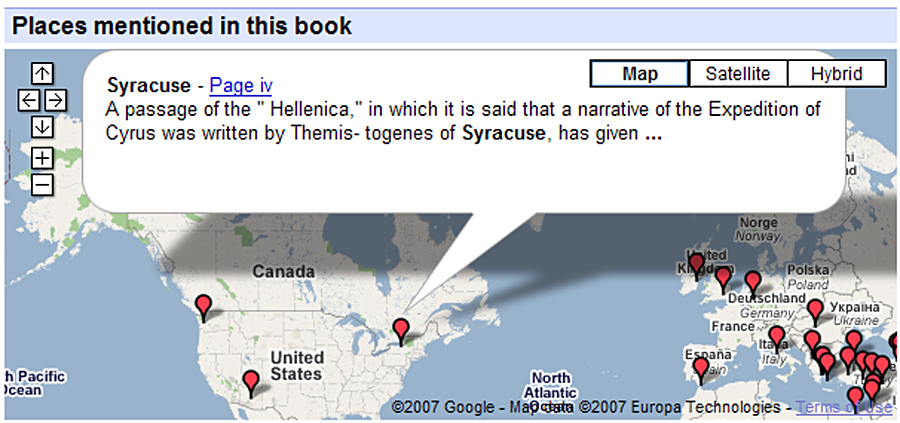
correctly, but others have clearly gone awry. Consider, for example, the placement of
Olympia, Syracuse and Tempe (see
Figure 2).
The placement of these ancient features in North America illustrates one of
the most obvious failure modes of geo-parsing algorithms. If the algorithm succeeds
in finding a match at all, it may find more than one match or a single, but incorrect
match. Given the information publicly available, we cannot know for certain which of
these two circumstances produced the results in question here. It seems probable,
however, that at least the Olympia and Syracuse errors result from selecting the
wrong result of several, as both of these well-known sites appear in many of the
standard gazetteers and geographic handbooks.
There are published methods for resolving such ambiguities on the basis of proximity
to other locations more reliably geo-parsed from the work, but these presuppose
knowledge of a coherent geographic footprint for the work under consideration as well
as a relatively comprehensive and highly relevant reference dataset that can provide
at least a single match for most geographic names ([
Smith 2001] and
[
Smith 2002a]). Google has not revealed, to our knowledge, whether
such self-calibrating algorithms are at work, but we can be certain that they do not
have access to a comprehensive, highly relevant reference dataset for the ancient
Greek world. Many datasets — including the
Getty Thesaurus of
Geographic Names, the
Alexandria Digital Library
Gazetteer and the open-content
GeoNames
database
[8] — contain significant numbers of historical Greek and Roman names; however,
the authors' experience confirms that many ancient sites and regions are unaccounted
for or incorrectly identified in these gazetteers, and many name variants and
original-script orthographies are omitted. A complete and reliable dataset simply
does not yet exist in a useful form.
It seems reasonable to assume that Google and its competitors will continue to seek
or construct more comprehensive reference datasets to support geo-parsing
improvements. Indeed, Google's embrace of VGI can be seen as a deliberate strategy
for this purpose. The Google Earth Community Bulletin Board (
http://bbs.keyhole.com) provides a venue for
the sharing of thematic sets of labeled geographic coordinates. The expansion of the
Googlebot's competencies to include KML and GeoRSS expand the harvest potential to
the entire web. This circumstance highlights a class of research and publication work
of critical importance for humanists and geographers over the next decade: the
creation of open, structured, web-facing geo-historical reference works that can be
used for a variety of purposes, including the training of geo-parsing tools and the
population of geographic indexes (see [
Elliott 2006]).
The automated features outlined above were added to Google Books in January 2007. The
stated motivation was cast in terms of helping users “plan your next trip, research an area
for academic purposes or visualize the haunts of your favorite fictional
characters”
[
Petrou 2007]. In August 2007, Google made a further announcement of new features, which
refined that motivation to echo the company's vision statement [
Badger 2007], emphasis ours; compare the Google Company Overview, first
sentence:
Earlier this year, we announced
a first step toward geomapping the world's literary information by
starting to integrate information from Google Book Search into Google Maps. Today,
[we] announce the next step: a new layer in Google Earth that allows you to
explore locations through the lens of the world's books...a dynamic and
interesting way to explore the world's literature...a whole new way to visualize
the written history of your hometown as well as your favorite books.
[9] If the “Places in this
book” component of Google Books is intended to help users explore the geography
of the book, the Google Books layer in Google Earth offers users the opportunity to
discover books by way of the geography. If, by chance, we should find ourselves
browsing northeastern Turkey in Google Earth, the Google Books layer offers us a book
icon in the vicinity of the town of İspir. This icon represents Watson's 1854
translation of the Anabasis. Links on the popup description kite will take us back to
specific pages of the scanned Harvard copy we discussed above. Another link provides
us with a way to “Search for all books referencing Ispir.” On 30 September 2007,
we were offered information about 706 books. By refining the search to include the
keyword “ancient,” we narrowed the result set to 167 books. We judged these
results to be highly relevant to our interests. We then selected a further suggested
refinement from a list of links at the bottom of the page: “Geography, Ancient.”
The resulting 7 matches are unsurprisingly spotty and largely out-of-date, given the
current state of Google's book digitization project, copyright restrictions and the
degree of publisher text-sharing partnerships. Taking this into account, we again
judged the results highly relevant. The results included [
Kiepert 1878], [
Kiepert 1881] and [
Kiepert 1910], [
Bunburry 1883], [
Fabricius 1888] and [
Syme 1995].
Prelude to Geographic Search: Web-based Mapping
We should not be surprised that web-wide geo-search is with us already in embryo. It
follows naturally, as a user requirement, once you have assembled a large index of
web content and developed the ability to parse that content and discriminate elements
of geographic significance.
Quick and accurate geographic visualization had long been one of the holy grails of
the web. The now-defunct Xerox PARC Map Viewer [
Putz 1994] demonstrated
to early users the potential of dynamic, web-based mapping, even if it was a
stand-alone application. A variety of services have come and gone since, some
concentrating on screen display, others attempting to provide dynamic maps suitable
for print. Some sites have provided scans of paper maps (like the David Rumsey
Historical Map Collection:
http://www.davidrumsey.com/); others have served out digital remotely
sensed imagery or readily printed static maps in PDF and other formats (the AWMC Maps
for Students collection, for example:
http://www.unc.edu/awmc/mapsforstudents.html). Flash and Shockwave have
also been popular ways of providing animation and interactivity on the web (for
example, some maps in [
Mohr 2006]). Until recently, however, the
dominant paradigms for dynamic on-line maps comprised iterative, server-side map
image generation, sometimes mediated by a client-side Java applet, in response to
discrete mouse clicks. To one degree or another most such map tools emulate the look
and feel of desktop GIS programs, perpetuating the thematic layering inherited from
analog film-based cartographic composition. This paradigm continues in active use
(consider the map interface for [
Foss 2007], for example).
Recent innovations in on-line cartographic visualization are revolutionary. We have
only just grown accustomed to digital globes (like NASA WorldWind and Google Earth)
and continuous-panning, “slippy” browser-side maps. Google, Yahoo, Microsoft
Live Search and MapQuest have all gone this route, and there is now an excellent,
open-source toolkit for building this sort of client-side maps: OpenLayers (
http://openlayers.org). Many of these
applications are doing more than giving us compelling new visual environments. Many
of them are also breaking down traditional divisions between browse and search,
thematic layers, web content, spatial processing and geographic datasets, not least
through the mechanisms known generically as “mashups” (web applications that
dynamically combine data and services from multiple, other web applications to
provide a customized service or data product). These tools remain an area of intense,
active development, so we should expect more pleasant surprises. Moreover, as the
costs of projectors, large-format LCD displays and graphics cards fall, and as
digital television standards encourage the replacement of older televisions, display
sizes and resolutions will at last improve. Efficient techniques for the simple
mosaicing of multiple display units and for the ad-hoc interfacing of mobile devices
and on-demand displays provided by third parties expand the horizon still further. It
will not be long before a broader canvas opens for cartographic display.
[10]
There is not space in this article to treat other forms of geographic visualization,
especially 3D modeling, in detail. It must suffice for us to say that this too is an
area of vigorous change. From the earliest QuickTime VR panoramas (classicists will
remember Bruce Hartzler's
Metis, still
hosted today by the Stoa:
http://www.stoa.org/metis/) to such contemporary services as Google
StreetView (
http://en.wikipedia.org/wiki/Google_Street_View), 3D modeling and its
integration with geographic and cartographic visualization tools proceeds apace.
Web-mapping the Geographic Content of Texts: Example of the Perseus Atlas
Geo-mapping of texts has been with the field of classics since the late 1990s, a
development that paralleled interdisciplinary innovations in digital library research
and development. Although its technology has now been eclipsed by rapid and recent
developments in web-based cartographic visualization, the Perseus Atlas stands as a
pivotal early exemplar of the power of this approach.
[11]
The first version of the Perseus Atlas was rolled out in June 1998, shortly after Rob
Chavez joined the Perseus team with the atlas as his primary task.
[12] Its coverage was
limited to the “Greek world,” and it was designed solely to provide geographic
context (illustrative maps) for discrete content items in the Perseus collection,
e.g., individual texts (or portions of texts) or object records. Perseus was already
in control of a significant amount of geographical information drawn from its texts
through geo-parsing.
[13] This was further augmented from metadata associated with its coin and
pottery databases. In the main, this dataset consisted of place names. A rudimentary
digital gazetteer had been developed through computational matching of this names
list with gazetteer records in various publicly-available US Government geographical
datasets (especially the resource now known as the GEONet Names Server of the
National Geospatial Intelligence Agency), which provided coordinates. After some
initial experimentation, the Perseus team selected an early version of MapServer to
provide dynamic mapping, and by way of Perl and CGI, this was integrated with the
existing Perseus tooling. Geographic data was stored in a plain PostgreSQL database,
the PostGIS spatial data extension for PostgreSQL having not yet been developed.
Vector linework and polygons from the Digital Chart of the World were added to
provide geographic context.
The Perseus Atlas saw two upgrades subsequent to its 1998 debut.
[14] The 2000
upgrade rolled out a rewritten and expanded Atlas that boasted several new features:
global geographic coverage, a relief base layer, and tighter integration between the
Atlas and the Perseus Lookup Tool. This last feature — a collaboration between Chavez
and David Smith — transformed the Atlas from a cartographic illustration mechanism to
an alternative interface for the entire collection, capable of both object-specific
and cross-object cartographic visualization and query. A fork of the Atlas, designed
to support the Historic London Collection, also appeared during this period.
[15] It offered essentially the same features, but
employed a separate geographic datum, higher-resolution imagery and rudimentary
temporal filtering capabilities by way of user-selectable, dated map layers. The 2002
upgrade improved the place name lookup and navigation tools in both Atlas branches,
added an option for saving map views and augmented the London Atlas with links to
QuickTime VR panoramas for select streets.
The Geo-Library, the Web and Geographic Search
It is clear from even a cursory review of contemporaneous developments that the
Perseus team was in the vanguard of an important revolution in web-based cartographic
visualization. When Perseus first fielded its atlas in 1998, The Alexandria Digital
Library (ADL) Project team had been working for four years to realize Larry Carver's
1983 vision of geographic search in a digital maps catalog [
Hill 2006, 49]. At about the same time the Perseus team was conceptualizing its atlas
as an interface to their entire, heterogeneous collection, the ADL vision was
expanding to encompass geographic browsing and search in an entire digital library
containing materials of all kinds, not just maps [
Goodchild 2004]. A
year after the Perseus Atlas appeared, the ADL vision of the “geo-library” was
endorsed by the National Research Council Mapping Science Committee (National
Research Council Mapping Science Committee 1999; see further [
Hill 2006, 11–17]). The 2000 upgrade to the Perseus Atlas represented the first
realization of this vision for the humanities outside ADL, and one of the first
anywhere.
It is clear that, despite significant challenges, geo-library functionality like
that pioneered by ADL and Perseus is rapidly maturing into one of the standard modes
for browsing and searching all manner of digital information on the web.
[16] Simple spatial
queries (within bounding boxes, by proximity to points, and by proximity to other
features) are becoming commonplace.
[17] We expect that such
“geo-aware” searches will occur more frequently outside special map-oriented
interfaces and services, with the target coordinates being provided automatically and
transparently by search software and other computational proxies.
These developments are being fueled by now-familiar business models.
[18] The proximity of a retail outlet or entertainment venue to a
customer (or the customer's preferred transportation method) is of interest to both
the consumer and the vendor. Likewise, the location of a potential customer — or the
locations of places she frequents, or that hold some sentimental or work-related
interest for her — all have monetizable value. Location-aware ads and free-to-user
planning, shopping and information-finding tools will be paid for by the businesses
that stand to gain from the trade that results. Competition between search providers
will open up more free search tools, some visible to users only by virtue of their
results; however, it seems likely that industrial-strength GIS access to the
underlying spatial indexes and georeferenced user profiles will remain a paid
subscription service.
Spatial search will help manage more seamlessly the inevitable heterogeneity of the
2017 web. Formats, delivery mechanisms, cost models and access challenges will surely
continue to proliferate. We assume that some resources will be little advanced from
the average 2007 vintage web page or blog post, whereas other works will exhibit the
full range of meaningful structures and linkages now being worked out under the
rubrics “semantic web” and “linked data”.
[19] Some works will be posted to basic
websites. Copies of other works will reside in institutional repositories, federated
archive networks, publishers' portal sites or massive grid environments. Whether
stand-alone or integrated in a collection, some resources will have appeared (or will
be augmented subsequently) with a range of metadata and rich, relevant links to other
resources and repositories. Others will constitute little more than plain text.
We expect current distinctions between geographic content and other digital works
will continue to erode over the next decade. As the geographic content in most
documents and datasets is identified, surfaced and exploited, “born geographic”
works will be fashioned in increasingly flexible and interoperable ways. To some
extent, specific industries and institutional consortia will surely continue to use
specialized protocols, service-oriented architectures and specialist formats to
provide lossless interchange and rich contextualization of critical data. Smaller
players, and big players wishing to share data with them, will increasingly use
RESTful models, simple URLs and widely understood open formats for basic information
publishing and exchange, even when these methods are lossy.
[20] In some cases, these documents will serve as proxies for the unadulterated
content, encoded in whatever format is necessary to express its creators' intent,
even if it is totally idiosyncratic. The value of universal, geo-aware search and
manipulation will trump concerns about surfacing “incomplete” data. Even now, a
KML file with appropriate descriptive content and hyperlinks can function as a table
of contents, geographic index or abstract for a document collection coded in TEI or a
custom web application running in Plone. We expect that extensible web feeds (like
the recently codified Atom Syndication Format, RFC 4287:
http://www.atompub.org/rfc4287.html) will form a simple, web-wide
infrastructure for notification and metadata exchange, alongside the more complex and
difficult-to-implement special protocols that are already linking federated digital
repositories and grid systems.
Big Science, Repositories, Neo-geography and Volunteered Geographic
Information
Many commercial innovations for online search, retrieval and visualization will be of
benefit to humanist scholars and their students. Such benefits will depend, to a
significant degree, on the willingness and ability of humanists, their employers and
their publishers to adapt their practices to fit the new regime.
To date, humanists have taken one of two approaches in preparing and disseminating
geo-historical information on the web. Large projects with significant funding have
tended to follow the lead of the larger geo-science and commercial GIS communities in
placing emphasis on the elaboration of extensive metadata describing their datasets,
thereby creating a basis for their discovery and inclusion in digital repositories.
In some countries (notably the U.K.) emphasis by national funding bodies has
encouraged such behavior. At the other end of the spectrum, hand-crafted datasets and
web pages are posted to the web with minimal metadata or distributed informally
within particular research communities. The neo-geographical revolution, and in
particular the explosive interest in Google Earth, has recently provided a much
richer and easier mechanism for the dissemination of some types of work in this
latter class (e.g., [
Scaife 2006]).
In the United States, e-science approaches have long been dominated by ideas
expressed in an executive order issued by President Clinton in 1994 and amended by
President Bush in 2003 [
Executive Order 12906] and [
Executive Order 13286]. These orders chartered a National Spatial Data
Infrastructure, encompassing a federally directed set of initiatives aimed at the
creation of a distributed National Geospatial Data Clearinghouse (
http://clearinghouse1.fgdc.gov/);
standards for documentation, collection and exchange; and policies and procedures for
data dissemination, especially by government agencies. More recently, the Library of
Congress constructed, through the National Digital Information Infrastructure and
Preservation Program, a National Geospatial Digital Archive (
http://www.ngda.org/), but this entity so far
has been of little use to classicists, as it has focused collection development on
“content
relating to the east and west coasts of the United States” (
http://www.ngda.org/research.php#CD).
[21]
The “national repository” approach has similarly found a coherent advocate for
academic geospatial data in the UK by way of EDINA, the national academic data center
at the University of Edinburgh (
http://edina.ac.uk/); however, the recent governmental decision to de-fund
the UK Arts and Humanities Data Service has introduced a significant level of
uncertainty and chaos into sustainability planning for digital humanities projects
there (details at
http://ahds.ac.uk/). More
broadly, the Global Spatial Data Infrastructure Association seeks to bring together
representatives of government, industry and academia to encourage and promote work in
this area (
http://gsdi.org), but to date it seems
to have focused exclusively on spatial data as it relates to governance, commerce and
humanitarian activities.
The top-down, national repository model (and its cousin, the institutional
repository) contrasts sharply with the neo-geographical methods now rapidly
proliferating on the web. To a certain degree, the differences reflect alternative
modes of production. The repository model was born in a period when spatial datasets
were created and used almost exclusively by teams of experts wielding specialized
software. Concerns about efficiency, duplication of effort and preservation were key
in provoking state interest, and consequently these issues informed repository
specifications. VGI, however, has only recently been enabled on the large scale by
innovations in web applications.
[22] Many such efforts
– from early innovators like the Degree Confluence Project (1996;
http://www.confluence.org/), to more
recent undertakings like Wikimapia (2006;
http://wikimapia.org/) – reflect the interests of communities whose
membership is mostly or almost entirely composed of non-specialists. They tend to be
more broadly collaborative, iterative and open than traditional geospatial data
creation efforts, but both commercial and institutional entities are also
increasingly engaged in collaborative development or open dissemination of geographic
information. VGI datasets are published via a wide range of web applications; recent
standardization of formats and accommodation by commercial search engines has opened
the field to “webby” distribution. For example, KML and GeoRSS-tagged web feeds
can now be posted and managed just like other basic web content.
[23]
The Electronic Cultural Atlas Initiative
In 1997, The Electronic Cultural Atlas Initiative was chartered in Berkeley to ease
and promote cross-project sharing of spatio-temporal data in the humanities [
Buckland 2004];
http://www.ecai.org. Among its initiatives was a metadata clearinghouse for
registered projects (
http://ecaimaps.berkeley.edu/clearinghouse/). Scholars wishing to
register their projects arrange for the published data to be posted to the web, and
create “ECAI metadata” (a Dublin Core derivative), which is then added to the
clearinghouse. Geographic and temporal components of the search are facilitated by a
map-and-timeline interface realized with server-side TimeMap software (see
http://www.timemap.net). This tool may be
seen, on one level, as a reflection of the dominant web search mode of the day, the
directory. But it also anticipated the future of VGI, appreciating that many
humanities projects with spatial components would not be able to fit their content
into the formats supported by the big repositories. Instead, it assumed that these
projects would arrange for web hosting themselves, and take voluntary steps to share
it with others. ECAI's Clearinghouse was also innovative in providing for the
discovery of indexed projects through a combination of search and browse methods that
exploited both spatial and temporal information in intuitive ways. ECAI remains a
vibrant international community, organizing regular conferences and maintaining
linkages across a wide range of projects and disciplines (see
http://ecai.org/Activities/conferences.asp).
The Stoa Waypoint Database and the Register of Ancient Geographic Entities
The first attempt at full-fledged VGI in Classics was the Stoa Waypoint Database, a
joint initiative of Robert Chavez, then with the Perseus Project, and the late Ross
Scaife, on behalf of the Stoa Consortium for Electronic Publication in the Humanities
(
http://www.stoa.org). In its public
unveiling, [
Scaife 1999] cast the resource as “an archive [and] freely accessible source of geographic
data...for archaeologists...students...digital map makers, or anyone else engaged
in study and research”. At initial publication, the dataset comprised
slightly over 2,000 point features (settlements, sites and river mouths), drawn from
work Chavez and Maria Daniels had done for the Perseus Atlas and personal research
projects. The points included both GPS coordinates and coordinates drawn from various
public domain (mostly US government) gazetteers and data sources. Chavez and Scaife
also invited contributions of new data, especially encouraging the donation of GPS
waypoints and tracks gathered in the field. A set of Guidelines for Recording
Handheld GPS Waypoints were promulgated to support this work [
Chavez 1999]. The original application for download of the database was
retired from the Stoa server some time ago; however, the data set has recently been
reposted by the Ancient World Mapping Center in KML format (
http://www.unc.edu/awmc/pleiades/data/stoagnd/). Despite limited
success in soliciting outside contributions, the idea of the Stoa Waypoint Database
had a formative influence on the early conceptualization of the authors' Pleiades
project.
The Stoa's interest in GPS waypoints reflected a worldwide trend: in April 1995, the
NAVSTAR Global Positioning System constellation had reached full operational
capability, marking one of the pivotal moments in the geospatial revolution we are
now experiencing. Originally conceived as a military aid to navigation, GPS quickly
became indispensable to both civilian navigation and map-making, as well as the
widest imaginable range of recreational and scientific uses. In May 2000, an
executive order eliminated the intentional degradation of publicly accessible GPS
signals, known as selective availability [
Office 2000]. This decision
effectively placed unprecedentedly accurate geo-referencing and navigating
capabilities in the hands of the average citizen (~15m horizontal accuracy).
Work on the Stoa Waypoints Database was clearly informed by the Perseus Atlas
Project, and also by another concurrent project at the Stoa: the Suda Online (SOL;
http://www.stoa.org/sol/). This
all-volunteer, collaborative effort undertook the English translation of a major
Byzantine encyclopedia of significance for Classicists and Byzantinists alike. The
Suda provides information about many places and peoples. An obvious enhancement to
the supporting web application would have been a mapping system like the Perseus
Atlas. In exploring the possibility, Scaife and Chavez realized that the variant
place names in the Suda and in the Perseus Atlas were a significant impediment to
implementation. The solution they envisioned in collaboration with Neel Smith was
dubbed the Register of Geographic Entities (RAGE). They imagined an inventory of
conceptual spatial units and a set of associated web services that would store
project-specific identifiers for geographic features, together with associated names.
This index would provide for cross-project lookup of names, and dynamic mapping. Some
development work was done subsequently at the University of Kentucky [
Mohammed 2002], and the most current version may be had in the Registry
XML format currently under development by Smith and colleagues at the Center for
Hellenic Studies via the CHS Registry Browser (cf., [
Smith 2005]). At
present, it contains just over 3,500 entries drawn almost entirely from Ptolemy's
works and thus has so far not seen wide use as a general dataset for the classical
world.
[24] The concern
that informed the RAGE initiative remains valid: geographic interoperation between
existing classics-related digital publications will require the collation of
disparate, project-level gazetteers. It is our hope that, as Pleiades content is
published, its open licensing and comprehensive coverage will catalyze a geo-webby
solution.
The Pleiades Project
Our own project, Pleiades (
http://pleiades.stoa.org), is heavily influenced by both by the scholarly
practices of our predecessors and by on-going developments in web-enabled geography.
We are producing a standard reference dataset for Classical geography, together with
associated services for interoperability. Combining VGI approaches with
academic-style editorial review, Pleiades will enable (from September 2008) anyone —
from university professors to casual students of antiquity — to suggest updates to
geographic names, descriptive essays, bibliographic references and geographic
coordinates. Once vetted for accuracy and pertinence, these suggestions will become a
permanent, author-attributed part of future publications and data services. The
project was initiated by the Ancient World Mapping Center at the University of North
Carolina, with development and design collaboration and resources provided by the
Stoa. In February 2008, the Institute for the Study of the Ancient World joined the
project as a partner and it is there that development efforts for the project are now
directed.
Pleiades may be seen from several angles. From the point of view of the Classical
Atlas Project and its heir, the Ancient World Mapping Center, Pleiades is an
innovative tool for the perpetual update and diversification of the dataset
originally assembled to underpin the Barrington Atlas, which is being digitized and
adapted for inclusion. From an editorial point of view, Pleiades is much like an
academic journal, but with some important innovations. Instead of a thematic
organization and primary subdivision into individually authored articles, Pleiades
pushes discrete authoring and editing down to the fine level of structured reports on
individual places and names, their relationships with each other and the scholarly
rationale behind their content. In a real sense then Pleiades is also like an
encyclopedic reference work, but with the built-in assumption of on-going revision
and iterative publishing of versions (an increasingly common model for digital
academic references). From the point of view of “neo-geo” applications, Pleiades
is a source of services and data to support a variety of needs: dynamic mapping,
proximity query and authority for names and places.
Pleiades incorporates a data model that diverges from the structure of conventional
GIS datasets. Complexity in the historical record, combined with varying uncertainty
in our ability to interpret it, necessitate a flexible approach sensitive to inherent
ambiguity and the likelihood of changing and divergent interpretations (cf. [
Peuquet 2002, 262–281]). In particular, we have rejected both
coordinates and toponyms as the primary organizing theme for geo-historical data.
Instead, we have settled upon the concept of “place” understood as a bundle of
associations between attested names and measured (or estimated) locations (including
areas). We call these bundles “features”. Individual features can be positioned
in time, and the confidence of the scholar or analyst can be registered with respect
to any feature using a limited vocabulary.
We intend for Pleiades content to be reused and remixed by others. For this reason,
we release the content in multiple formats under the terms of a Creative Commons
Attribution Share-Alike license (
http://creativecommons.org/licenses/by-sa/3.0/). The Pleiades website
presents HTML versions of our content that provide users with the full complement of
information recorded for each place, feature, name and location. In our web services,
we employ proxies for our content (KML and GeoRSS-enhanced Atom feeds) so that users
can visualize and exploit it in a variety of automated ways. In this way, we provide
a computationally actionable bridge between a nuanced, scholarly publication and the
geographic discovery and exploitation tools now emerging on the web. But for us,
these formats are lossy: they cannot represent our data model in a structured way
that preserves all nuance and detail and permits ready parsing and exploitation by
software agents. Indeed, we have been unable to identify a standard XML-based data
format that simply and losslessly supports the full expression of the Pleiades data
model.
[25]
In 2009, we plan to address users' need for a lossless export format by implementing
code to produce file sets composed of ESRI Shapefiles and attribute tables in
comma-separated value (CSV) format. The addition of a Shapefile+CSV export capability
will facilitate a download-oriented dissemination method, as well as position us to
deposit time-stamped versions of our data into the institutional repository at NYU
and other archival contexts as appropriate. Indeed, this is the most common format
requested from us after KML. Although the Shapefile format is proprietary, it is used
around the world in a variety of commercial and open-source GIS systems and can be
readily decoded by third-party and open-source software. It is, in our judgment, the
most readily useful format for individual desktop GIS users and small projects, and
because of its ubiquity has a high likelihood of translation into new formats in the
context of long-term preservation repositories.
Historical time remains a problematic aspect of the web that cannot be divorced from
geography. The use of virtual map layers to represent time periods remains a common
metaphor. Timelines and animated maps are also not uncommon, but all these techniques
must either remain tied to specific web applications or rely on cross-project data in
standard formats that only handle the Gregorian calendar and do not provide
mechanisms for the representation of uncertainty. Bruce Robertson's Historical Event
Markup Language (HEML;
http://heml.mta.ca)
remains the most obvious candidate for providing the extra flexibility humanists need
in this area, both for modeling and for expression in markup. It is our hope that it
too will find modes of realization in the realm of web feeds and semantic
interchange.
In its final report, the American Council of Learned Societies Commission on
Cyberinfrastructure for the Humanities and Social Sciences highlighted the importance
of accessibility, openness, interoperability and public/private collaboration as some
of the prerequisites for a culture of vigorous digital scholarship [
Unsworth 2006, 28]. We believe that Pleiades exemplifies these
characteristics, both on its own terms and as an emulator of prior efforts that
helped identify and define them. We recommend our two-fold agenda to other digital
projects in the Classics whose content includes or informs the geographic:
- Publish works that help (in terms of content, structure, delivery and
licensing) other humanists work and teach
- Publish works that potentially improve the performance and accuracy of the
(geo)web
Conclusion
We view the history of computing, classics and geography as a rich and profitable
dialogue between many disciplines and practitioners. It is tragic indeed that we lost
much too soon our friend and mentor Ross Scaife, who emerges as a pivotal figure in
our narrative of this history. It was he who invited Elliott to the University of
Kentucky in 2001 to give the first public presentation about the proposed Pleiades
Project at the Center for Computational Studies, and it was he who provided the
development server that supported the first two years of Pleiades software
development. We are confident that, were Ross with us today as he was at the workshop
that occasioned the original version of this paper, he would still be motivating us
with challenging examples and stimulating ideas, connecting us with new collaborators
and encouraging us to push harder for the changes we wish to see in our
discipline.
Despite the sense of loss that inevitably runs through the papers in this volume, and
despite the challenges we face in a chaotic and interdisciplinary milieu, we also
view the history of geographic computing and the classics as a hopeful omen for the
future. We have a spectacular rising wave to ride: a wave of technological and
societal change that may well help us conduct research and teach with more rigor and
completeness than before while breaking down artificial boundaries between scholars
in the academy and members of an increasingly educated and engaged public whose
professional skills, public hobbies and personal interests coincide with ours at the
fascinating intersection of humanity, space and time.
Works Cited
Boast 2007 Boast, R., et al., “Return to Babel: Emergent Diversity, Digital Resources, and Local
Knowledge,”
The Information Society 23 (2007), 395-403.
Boll 2008 Boll, S. et al (eds.), LOCWEB '08: Proceedings of the First International Workshop on
Location and the Web, New York: ACM, 2008.
Bunburry 1883 Bunbury, E. A History of Ancient Geography Among the Greeks and Romans from the
Earliest Ages till the Fall of the Roman Empire, 2d. ed, 2 vols., London:
John Murray, 1883.
Crane 2006a Crane, Gregory R. and
Jones, Alison, “The Challenge of Virginia Banks: An Evaluation of
Named Entity Analysis in a 19th-Century Newspaper Collection,” pp. 31-40 in
Proceedings of the 6th ACM/IEEE-CS joint conference on
Digital libraries, Chapel Hill: 2006: a copy is available at
http://dl.tufts.edu/view_pdf.jsp?pid=tufts:PB.001.001.00007.
Czerwinski 2006 Czerwinski,
M. “Large Display Research Overview,” CHI '06 extended
abstracts on Human factors in computing systems, New York, 2006: 69-74.
Dunn 2008 Dunn, S. and Blanke, T. “Next Steps for E-Science, the Textual Humanities and VREs: A Report
on Text and Grid: Research Questions for the Humanities, Sciences and Industry, UK
e-Science All Hands Meeting 2007,”
D-Lib Magazine 14 (2008),
http://www.dlib.org/dlib/january08/dunn/01dunn.html.
Elliott 2008a Elliott, T. “Constructing a Digital Publication for the Peutinger Map” in
R. Talbert and R. Unger (eds.), Cartography in Antiquity and the
Middle Ages: Fresh Perspectives, New Methods, Leiden: 2008: 99-110.
Fabricius 1888 Fabricius, W.
Theophanes von Mytilene und Quintus Dellius als Quellen des
Geographie des Strabon, Strassburg: Heitz und Mündel, 1888.
Gillies 2008 Sean Gillies, “Entries: Category [REST]: Representational State Transfer”,
Sean Gillies Blog,
http://sgillies.net/blog.
Hansen 2004 Hansen, M. and Nielsen,
T. An Inventory of Archaic and Classical Poleis, Oxford:
2004.
Hill 2006 Hill, L. Georeferencing: The Geographic Associations of Information, Cambridge,
Mass. 2006.
Kiepert 1878 Kiepert, H. Lehrbuch der Alten Geographie, Berlin: D. Reimer,
1878.
Kiepert 1881 Kiepert, H. and
Macmillan, G.A. (trans.), A Manual of Ancient Geography,
London: Macmillan and Co, 1881.
Kiepert 1910 Kiepert, H. Atlas Antiquus, Berlin: D. Reimer, 1902.
Knowles 2002 Knowles, A. (ed).
Past Time, Past Place: GIS for History, Redlands, CA,
2002.
Knowles 2008 Knowles, A. and
Hillier, A. (eds.). Placing History: How Maps, Spatial Data and
GIS are Changing Historical Scholarship, Redlands, CA, 2008.
Kozareva 2006 Kozareva, Z. “Bootstrapping Named Entity Recognition with Automatically Generated
Gazetteer Lists.” In 11th Conference of the European
Chapter of the Association for Computational Linguistics, Proceedings. The
Association for Computer Linguistics, 2006: 15-21.
Lucarelli 2007 Lucarelli, G.;
Vasilakos, X. and Androutsopoulos, I. “Named Entity Recognition
in Greek Texts with an Ensemble of SVMs and Active Learning.”
International Journal on Artificial Intelligence Tools,
16 (2007): 1015-1045.
Mostern 2008 Mostern, R. “Historical Gazetteers: An Experiential Perspective, with Examples
from Chinese History,”
Historical Methods: A Journal of Quantitative and
Interdisciplinary History, 41 (2008), 39-46.
Nadeau 2006 Nadeau, D.; Turney, P. D.
and Matwin, S. “Unsupervised Named-Entity Recognition: Generating
Gazetteers and Resolving Ambiguity.” In Lamontagne, L. and Marchand, M.
(ed.). Canadian Conference on AI 2006, Proceedings. Lecture
Notes in Computer Science 4013, Springer 2008: 266-277.
Peuquet 2002 Peuquet, Donna.
Representations of Space and Time. New York: Guilford
Press, 2002.
Pritchard 2008 Pritchard, D.
“Working Papers, Open Access, and Cyber-infrastructure in
Classical Studies.”
Literary and Linguistic Computing 23 (2008):
149-162.
Shaalan 2008 Shaalan, K. F. and
Raza, H. “Arabic Named Entity Recognition from Diverse Text
Types.” In Nordström, B. and Ranta, A. (ed.).
Advances
in Natural Language Processing, 6th International Conference, GoTAL 2008,
Gothenburg, Sweden, August 25-27, 2008, Proceedings. Lecture Notes in Computer
Science 5221. Springer 2008: 440-451.
http://dblp.uni-trier.de/db/conf/tal/gotal2008.html#ShaalanR08.
Shadbolt 2006 Shadbolt, N. et
al. “The Semantic Web Revisited,”
IEEE Intelligent Systems 21.3 (2006): 96-101.
Smith 2001 Smith, D. and Crane, G.
“Disambiguating Geographic Names in a Historical Digital
Library.” In P. Constantopoulos and I.T. Solvberg (eds.), Research and Advanced Technology for Digital Libraries, Proceedings
of the 5th European Conference, ECDL 2001, Darmstadt, Germany, Berlin,
2001: 127-136.
Smith 2002a Smith, D. “Detecting Events with Date and Place Information in Unstructured
Text,”. In G. Marchionini and W. Hersh (eds.), Proceedings of the Second ACM/IEEE Joint Conference on Digital Libraries
(JCDL 2002), Portland, OR. New York: 191-196.
Smith 2002b Smith, D. “Detecting and Browsing Events in Unstructured Text,” pp.
73-80 in SIGIR '02: Proceedings of the 25th annual international ACM SIGIR conference
on Research and development in information retrieval, New York: 2002.
Stødle 2007 Stødle, D. et al. “The 22 Megapixel Laptop” in
EDT '07:
Proceedings of the 2007 workshop on Emerging displays technologies, New
York, 2007: article no. 8,
http://doi.acm.org/10.1145/1278240.1278248.
Syme 1995 Syme, R. Anatolica: Studies in Strabo. Oxford University Press, 1995.
Talbert 1992 Talbert, R. “Mapping the Classical World: Major Atlases and Map Series
1872-1990,”
Journal of Roman Archaeology 5 (1992): 5-38.
Unsworth 2000 Unsworth, J.
“Scholarly Primitives: What Methods Do Humanities Researchers
Have in Common, and How Might Our Tools Reflect This?”. Symposium on
Humanities Computing: Formal Methods, Experimental Practice, sponsored by King's
College, London, May 13, 2000 (no date):
http://www.iath.virginia.edu/~jmu2m/Kings.5-00/primitives.html.
Unsworth 2006 Unsworth, J.,
Welshons, M. (eds.).
Our Cultural Commonwealth: The Report of
the American Council of Learned Societies Commission on Cyberinfrastructure for
the Humanities and Social Sciences, 2007:
http://www.acls.org/cyberinfrastructure/.
babeu 2008 Babeu, A., Bamman, D.,
Crane, G., Kummer, R. and Weaver, G. “Named Entity Identification and
Cyberinfrastructure.” In 11th European Conference, ECDL 2007,
Budapest, Hungary, September 16-21, 2007. Proceedings. Lecture Notes in Computer
Science 4675, Springer 2007: 259-270.
Şahin 2007 Şahin, S. and M. Adak
(eds.), Stadiasmus Patarensis Itinera Romana Provinciae
Lyciae, Istanbul: 2007.