Changing the Center of Gravity: Transforming Classical Studies Through Cyberinfrastructure
2009
Volume 3 Number 1
Abstract
No humanists have moved more aggressively in the digital world than students of the
Greco-Roman world but the first generation of digital classics has seen relatively
superficial methods to address the problems of print culture. We are now beginning to
see new intellectual practices for which new terms, eWissenschaft and eClassics, and
a new cyberinfrastructure are emerging.
For Cathy, Lincoln, Adrian and Russell
The Athenians grew in power and proved, not in one
respect only but in all, that equality is a good thing. Evidence for this is the
fact that while they were under tyrannical rulers, the Athenians were no better in
war than any of their neighbors, yet once they got rid of their tyrants, they were
by far the best of all. This, then, shows that while they were oppressed, they
were, as men working for a master, cowardly, but when they were freed, each one
was eager to achieve for himself.
(Herodotus 5.78, tr. after Godley)
I am no sculptor, to make statues fixed motionless on
the same pedestal. Go, sweet song, on every merchant-ship and rowboat that leaves
Aegina, and announce that Lampon's powerful son Pytheas [5] won the victory
garland for the pancratium at the Nemean games.
(Pindar Nemean 5.1-5, tr. after Diane Svarlien)
The first passage above follows a military encounter in which the Athenians show, for
the first time, that terrible energy which would (at least according to our Athenian
sources) fascinate and unnerve the rest of fifth-century Greece. Students of
classical Athens have for millennia contemplated the energy that liberation released
— Herodotus’ wonder has echoed ever since and served as one motivation for human
fascination with Athens and its achievements.
[1]
The early years of the twenty-first century have seen a heroic age for intellectual
life. Ideas have poured across the world and new minds have joined the
professionalized academics and authors in grappling with the heritage of humanity.
Often rough and unpolished, unconcerned with the niceties of convention, a new
generation of digital entities has exploded across human society, creating wikis,
blogs and millions of electronic resources. Plato’s Socrates scorned writing itself
on the grounds that the written word was as powerless to answer our questions as a
mute painting (Plat.
Phaedrus 275d). Now each question
becomes a challenge as active readers probe relentlessly the sprawling information
space beneath their fingers. Wikipedia has demonstrated a new form of intellectual
production that challenges the assumptions that many of us internalized in graduate
school about how knowledge can be described and ideas shared.
[2] The scale of
projects such as Wikipedia deserves serious reflection: the English Wikipedia has, as
of summer 2008, more than 2.4 million entries.
[3] By one estimate, Wikipedia has absorbed 100 million hours
of labor — put another way, Wikipedia has, if measured by the labor invested, become
a billion dollar project [
Shirky 2008].
Changes go beyond traditional academic channels. The 9/11 attacks in 2001 were the
last major event owned by the centralized 20th century media. With the Tsunami and
the 7/7 London bombings, we had shifted “from the
broadcasters owning the story, to the people involved in the events owning their
own stories and spreading it to those who they know and care about, using their
own communication channels.”
[4]
Conventional streams of refereed publications (such as this collection) are necessary
but insufficient — this introduction has already cited Wikipedia, a blog and the
video for a presentation at a conference. We cannot make the decisions that we need
to live in the world around us without constantly evaluating information that has no
conventional academic pedigree. Every anxious editorial fretting about undomesticated
ideas prowling through an internet jungle underscores the urgent need for that
critical thinking that we in the liberal arts claim to instill. The internet may
prove to be the best thing for humanities education since the rulers of early modern
Europe found that classical training provided them with the administrators with whom
to build strong nation states.
No field of study is poised to benefit more than those of us who study the ancient
Greco-Roman world and especially the texts in Greek and Latin to which philologists
for more than two thousand years have dedicated their lives. Our predecessors worked
in Alexandria, Damascus and Baghdad as well as Berlin, Oxford and Venice. Many lived
in states whose names we may never have heard. Most spoke languages like Syriac or
the dialects of medieval Europe, which have themselves passed into history. They
preserved the battered remains of the past in isolated monasteries and the libraries
of aristocrats. They raised capital and set type, then sent Greek and Latin texts
coursing through Europe and then the world. They convinced the powerful that the
study of Greek and Latin would provide the supple and disciplined minds needed to
fashion, maintain and expand the nation states of Europe and their empires across the
world. And in the twentieth-century, as other disciplines emerged as filters to
identify the promising and send them on their way to worldly privilege, classicists
carried their field forward, opened up their curricula to those who had not learned
Greek and Latin and, from the margins of the intellectual world, continued their
researches on the texts that they loved
The papers in this collection reflect a new generation of classicists —
entrepreneurial in their disruptive actions, impatient of convention, hunting for new
methods to understand and to disseminate those ancient texts to which they, like
dozens of generations before them, have dedicated their lives. It is hard to predict
what the future holds for the intellectual practices and products of twentieth
century print-based classical studies. In the opening of his fifth Nemean Ode Pindar
reveled in the speed and reach of the written word: his songs could be copied and
race across the known world in the largest ship and the smallest boat, while the
grandest statues remain fixed and mute upon their pedestals. The texts of antiquity,
freed from the tyrannical limitations of expensive print publication, preserved in
multiple servers across the globe, flash instantaneously anywhere that the internet
can reach — hundreds of millions of desktops and mobile devices. Homer, Plato,
Virgil, Cicero — they all reach more of humanity than ever was conceivable in the
millennia since they set down their styli for the last time and passed into dust. And
it is not just physical access — we already can, with simple links between source
text and its commentaries, translations, morphological analyses and dictionary
entries, provide a better reading environment than was ever conceivable in print
culture. We know from the readers of our web sites that texts in Greek and Latin, of
many types, now fire the minds to which twenty years ago they had no access. And if
this reading environment now supports those proficient in English, we can already
design libraries that will, within a reasonable period of time, support readers in
the less commonly spoken languages of the European Union such as Croatian and
Hungarian and widely spoken languages such as Arabic and Chinese.
Terms and continuities
Wissenschaft and Philology
As to the speeches which were made either before
or during the war, it was hard for me, and for others who reported them to me,
to recollect the exact words. I have therefore put into the mouth of each
speaker the sentiments proper to the occasion, expressed as I thought he would
be likely to express them, while at the same time I endeavoured, as nearly as I
could, to give the general purport of what was actually said. [2] Of the events
of the war I have not ventured to speak from any chance information, nor
according to any notion of my own; I have described nothing but what I either
saw myself, or learned from others of whom I made the most careful and
particular enquiry. [3] The task was a laborious one, because eye-witnesses of
the same occurrences gave different accounts of them, as they remembered or
were interested in the actions of one side or the other. [4] And very likely
the strictly historical character of my narrative may be disappointing to the
ear. But if he who desires to have before his eyes a true picture of the events
which have happened, and of the like events which may be expected to happen
hereafter in the order of human things, shall pronounce what I have written to
be useful, then I shall be satisfied. My history is an everlasting possession,
not a prize composition which is heard and forgotten.
(Thuc. 1.22, tr. Jowett)
The distinction between science and the humanities reflects particular traditions
of the English speaking world. In German, for example, Wissenschaft
includes all systematic intellectual work — we need to specify
Naturwissenschaft or Geisteswissenschaft if we want
to distinguish between the natural sciences and the humanities. The term
Altertumswissenschaft describes the systematic analysis of the
past, including both the textual and the material record.
We thus use the term Wissenschaft to describe the output of the systematic study
of antiquity as it appears in material forms such as articles and monographs,
plans and maps, images and diagrams, editions and reference works. Whether or not
we believe that we can reconstruct aspects of the ancient world as they actually
were, we develop our ideas on the basis of primary and secondary sources stored in
material form.
For the purposes of this introduction, philology describes the production of
shared primary and secondary sources about linguistic sources, while classical
philology focuses upon classical Greek and Latin, as these languages have been
produced from antiquity through the present. The famous passage from Thucydides,
quoted above, is relevant for several reasons. First, Thucydides was one of the
first to apply systematic methods to represent in textual form, as accurately as
he could, the events of the past — his history of the Peloponnesian War has been a
model for Wissenschaft. Second, Thucydides used writing as a medium to disseminate
his ideas, but he drew upon every source available, including eyewitness
interviews, archaeological remains, and the textual record. Third, Thucydides’
words seek to represent an entire world — we cannot fully study Thucydides without
engaging as well with the material record. Nor is this material record simply a
source with which to illustrate the topics that Thucydides has included. We need
to develop the fullest possible understanding of the material record in order to
develop our own understanding of how Thucydides represents his subject.
The terms eWissenschaft and ePhilology, like their counterparts eScience and
eResearch, point towards those elements that distinguish the practices of
intellectual life in this emergent digital environment from print-based
practices.
[5] Terms such as eWissenschaft and
ePhilology do not define those differences but assert that those differences are
qualitative. We cannot simply extrapolate from past practice to anticipate the
future.
Classics and the Humanities
| Socrates: | I heard, then, that at Naucratis, in Egypt, was one of the ancient gods
of that country, the one whose sacred bird is called the ibis, and the
name of the god himself was Theuth. He it was who [274d] invented numbers
and arithmetic and geometry and astronomy, also draughts and dice, and,
most important of all, letters. Now the king of all Egypt at that time
was the god Thamus, who lived in the great city of the upper region,
which the Greeks call the Egyptian Thebes, and they call the god himself
Ammon. To him came Theuth to show his inventions, saying that they ought
to be imparted to the other Egyptians. But Thamus asked what use there
was in each, and as Theuth enumerated their uses, expressed praise or
blame, according as he approved [274e] or disapproved. The story goes
that Thamus said many things to Theuth in praise or blame of the various
arts, which it would take too long to repeat; but when they came to the
letters, “This invention, O king,” said Theuth, “will make the
Egyptians wiser and will improve their memories; for it is an elixir
of memory and wisdom that I have discovered.” But Thamus replied,
“Most ingenious Theuth, one man has the ability to beget arts, but
the ability to judge of their usefulness or harmfulness to their users
belongs to another; [275a] and now you, who are the father of letters,
have been led by your affection to ascribe to them a power the
opposite of that which they really possess. For this invention will
produce forgetfulness in the minds of those who learn to use it,
because they will not practice their memory. Their trust in writing,
produced by external characters which are no part of themselves, will
discourage the use of their own memory within them. You have invented
an elixir not of memory, but of reminding; and you offer your pupils
the appearance of wisdom, not true wisdom, for they will read many
things without instruction and will therefore seem [275b] to know many
things, when they are for the most part ignorant and hard to get along
with, since they are not wise, but only appear wise.”
|
Those of us who grew up hearing that we should read more and that television had
damaged our minds may smile when we hear Plato’s Socrates two and a half millennia
ago criticizing the written word for damaging our minds. In the early twenty-first
century, complaints have emerged about the look-up culture of Google and
ubiquitous connectivity.
[6]
Nevertheless, the basic point remains valid, even if the media change. We must
augment our biological memories by using material records, whether these are
hand-written, printed or digital but external information can only augment
internalized knowledge. We can only experience humor, for example, if we
understand the joke as it happens. We can work our way through a Greek text,
looking up every word in a dictionary and using modern translations to orient
ourselves, but we will not understand the text in the same way as we would if we
could understand the language fluently. And, even if we understand the Greek words
and grammar, we will hear more from those words the more we have thought about
Plato, the philosophical concepts that form the subject of his dialogues, and the
culture in which he lived.
Thucydides set out to express in material, written form a record of the past that
would last forever. Plato questions the value of any written record except insofar
as that record finds full expression in human minds. We already live in a world
where the books have begun to talk with each other.
[7] When
data mining systems detect fraudulent activity on our credit cards, they do a
better job of finding significant patterns than could human analysts alone — if
there were human analysts to sift through trillions of transactions. Financial
institutions do not care how they identify fraud because fraud detection is a
means to an end.
Text mining can detect words and phrases that are unusual in Plato.
[8] We can even
imagine syntactic analyzers that can not only parse every surviving Greek and
Latin word but that might at some point be better able to justify its decisions by
pointing to other similar patterns in that vast corpus than has ever been possible
for any human reader. But such information would only realize its full value if it
becomes knowledge in a living human mind and allows a reader to see something that
would not otherwise have been visible.
[9]
For the purposes of this discussion, we use the terms classics and the humanities
to describe that focus upon internalized knowledge and intellectual practices
designed to help us perceive new connections and increasingly sophisticated
patterns not only in the texts that we read but in the images that we see and the
sounds that we hear. Human beings are the measure of all things in the humanities.
Philology truly matters insofar as it serves classics and its goal of bringing
classical Greek and Latin to life in the minds of human beings.
Infrastructure
Tell me now, you Muses that have dwellings on
Olympus — [485] for you are goddesses and are at hand and know all things,
whereas we hear but a rumor and know nothing — who were the captains of the
Danaans and their lords. But the common folk I could not tell nor name, no, not
though ten tongues were mine and ten mouths [490] and a voice unwearying, and
though the heart within me were of bronze, did not the Muses of Olympus,
daughters of Zeus that bears the aegis, call to my mind all who came beneath
Ilios. Now will I tell the captains of the ships and the ships.
(Homer, Il. 2.484-493, tr. after A. T. Murray)
Infrastructure provides the material instruments whereby we can produce new ideas
about the ancient world and enable other human beings to internalize those ideas.
Infrastructure includes intellectual categories (e.g., literary genres, linguistic
phenomena, and even the canonical book/chapter/verse/line citation schemes whereby
we cite chunks of text), material artifacts such as books, maps, and photographs,
buildings such as libraries and book stores, organizations such as universities
and journals, business models such as subscriptions, memberships, and fee simple
purchases, and social practices such as publication and peer review. Our
infrastructure constrains the questions that we ask and our sense of the possible.
Thus, the Homeric narrator rules out the idea of representing the names of every
hero who participated in the Trojan War. The twenty-first century fan of American
baseball can, by contrast, locate not only the name but the basic statistics
recorded for every person who ever threw a pitch or swung the bat in a major
league game. By the classical period, we begin to find lists of citizens,
office-holders, temple dedications, tribute paid and similar categories.
Thucydides drew upon textual, archaeological and verbal sources and he could leave
behind a written text to which he had attached his own name, but there were no
libraries in the modern sense. He could not cite transcripts of public speeches in
a congressional record or even a
New York Times
article. He could not footnote official documents in a classical Greek equivalent
to the
Official Records of the Union and Confederate
Armies
[
United 1880].
[10] There were no recordings of those who
survived to describe civil war in Corcyra or the Sicilian Expedition. He could not
publish pictures or even expect that diagrams would be faithfully reproduced over
time. A stream of words was the only medium by which he could represent his chosen
subjects.
Infrastructure is so fundamental that it may become invisible to us but the
resulting blindness makes us confuse the limits that we face with our larger
goals. In periods where our infrastructure advances incrementally, we may take it
for granted. Infrastructure does not simply affect the countless costs/benefit
decisions we make every day — it defines the universe of what cost/benefit
decisions we can imagine.
[11] All the
tribute of the Athenian empire could not have paid for one color photograph of
Pericles. Rarely, if ever, can we predict the full implications of relatively
modest technological change. Gutenberg did not think that, in using movable type
to print a Latin bible, he was creating a technology to make translations of the
bible ubiquitous, enable new forms of Christian worship and facilitate
revolutionary change.
But even if we cannot foresee the future with perfect clarity, we must constantly
reexamine the goals that we choose to pursue today in the light of what is already
possible. Before shifting to the digital infrastructure already taking shape and
its implications for current practices in classical philology, we should review
what has and has not changed for classical philology as the core information
infrastructure of human life as a whole has shifted, decisively and irrevocably,
from atoms to electrons.
Classics in 2008
I shall begin with our ancestors: it is both just and
proper that they should have the honor of the first mention on an occasion like
the present. They dwelt in the country without break in the succession from
generation to generation, and handed it down free to the present time by their
valor. [2] And if our more remote ancestors deserve praise, much more do our own
fathers, who added to their inheritance the empire which we now possess, and
spared no pains to be able to leave their acquisitions to us of the present
generation. [3] Lastly, there are few parts of our dominions that have not been
augmented by those of us here, who are still more or less in the vigor of life;
while the mother country has been furnished by us with everything that can enable
her to depend on her own resources whether for war or for peace.
(Pericles’ Funeral Oration: Thuc.
2.36.1-3)
Classicists can identify with the Athenian audience of Pericles’
Funeral Oration — at least, the oration that Thucydides presents to us.
We do not, like the Athenians, like to say that our ancestors were sprung from the
dirt and our ancestors have not inhabited the same small rocky peninsula since they
were sprang from the earth — classicists have come from countries and periods far
beyond the experience of any classical Greek. Our field has an ancient history but we
have begun to expand, like the Athenians of fifth century Athens, into a much larger
space than we ever could occupy before. The digital world has become our sea, but our
empire offers freedom, and the natural borders that will contain our field are
nowhere to be seen. Much as we may have achieved, we are still as a field in the
incunabular phase of development, more focused upon the problems of the past than the
opportunities of the present.
[12]
Classicists were among the first humanists to exploit digital technologies and enjoy
a reputation as being arguably the most digitally advanced field. Certainly,
classicists were, as a field, early adopters. If one includes the study of any Greek
and Latin texts under Latin, Father Busa’s famous concordance of Thomas Aquinas,
produced with the help of IBM in the late 1940s, would constitute the start of
digital classics (see [
Busa 1974] and [
Busa 1980]).
If we restrict ourselves to the Greek and Latin authors commonly taught in classics
departments of the 20th century, then we must move twenty years forward to the late
1960s. Full professors of classics today have been born after David Packard, who
working in the basement of the Harvard Science Center digitized the text of Livy.
There are classics majors who received their undergraduate degrees in the spring of
2008 who were born after the Perseus Digital Library began serious work in the late
spring of 1987. Not only are virtually all publications — whether distributed in
print or not — produced digitally, but digitized textual corpora, digital versions of
printed secondary sources, electronic reviews, bibliographic databases, and web sites
are all standard elements of our work.
[13] Two leading departments of classical philology have even discovered the
value of the preprint servers on which some of the most demanding areas of research
have depended for more than fifteen years.
[14]
The early use of digital tools in classics may, paradoxically, work against the
creative exploration of the digital world now taking shape. Classicists grew
accustomed to treating their digital tools as adjuncts to an established print world.
Publication — the core practice by which classicists establish their careers and
their reputations — remains fundamentally conservative. While we may congratulate
ourselves on the innovative content of what we write and while we will always need
publications that articulate particular arguments at a particular point in time in a
particular voice, the format of our publications is essentially the same as that
which Gibbon used in the 18th century.
[15]
While the documents were digital in form, almost none of their content was machine
actionable: strings such as “Thuc. 1.38.2” had not been analyzed and converted
into machine actionable links to the text of Thucydides, book 1, chapter 38, section
2; a reference to Thucydides did not have associated with it any information whereby
an automated system could reliably determine whether this Thucydides was the
historian or one of the various other figures by this name; quotations of Greek and
Latin authors were not dynamically linked to multiple online editions, nor did they
carry with them links to any linguistic apparatus (textual notes, dictionaries,
grammars, commentaries, translations) not offered by the author of the articles.
While these articles may be online, the main bibliographic resource for classical
studies,
L’Année Philologique, still relies upon manual summaries to index and disseminate these articles in
its digitally disseminated bibliography. Nor can the reader, of course, see what
later articles cite earlier publications.
We can add each of the features listed above to existing documents automatically with
reasonable accuracy — simple text search provides functionality that is increasingly
comparable to the manually produced indices on which we had to rely in print
culture.
[16] Google has already popularized the ability to
identify and disambiguate place names and to find quotations embedded in unstructured
text — automatically generated maps became a standard feature of Google Books in 2007
and frequently quoted passages soon followed.
[17] Particular domains may need to adapt general services to their needs:
classicists need Optical Character Recognition (OCR) systems that can not only
provide useful results for classical Greek but can also recognize Latin and do not
helpfully convert
t-u-m (a Latin word for “then”) into English
t-u-r-n.
[18] Scholarly disciplines need page layout
analysis systems that can recognize and parse not only general document formats such
as notes at the bottom of the page, and the individual entries of indices,
encyclopedias, and lexica, but also specialized document formats such as the
commentary and textual notes.
[19] Scholarly disciplines such as classics need specialized named entity
searches: we need to determine not only whether “Th. 1.38” is a citation to a
primary source but also, if so, whether it designates Thucydides, book 1, chapter 38,
Theocritus,
Idyll 1, line 38 or some other text.
The production of these services is the most important task for classics and for any
scholarly discipline which does not focus solely upon the contemporary
English-language, mass market American culture which the Web of 2008 primarily
serves. While we may need to support less and less software, we will then only shift
our efforts to the production and refinement of the knowledge sources which support
general services: we need machine actionable reference works that can help general
services run by giants such as Google to distinguish one Antonius or one Alexandria
from another.
[20]
Classicists of the 20th century built their work upon a foundation that took shape in
the 19th century. In the last decades of the twentieth century, ambitious classicists
began to shift their efforts away from infrastructural tools such as editions and
commentaries. Instead they turned towards articles and expository monographs on
topics often derived from their colleagues in the Modern Language Association. The
Pax Stereotypica of the 20th century has, however, collapsed. We live in a digital
age in which we need to rethink our most fundamental resources -- we are reinventing
the forms and functions of our editions, lexica, encyclopedias, commentaries,
grammars, bibliographies and every other textual category that evolved in a print
ecosystem. And as we feel our way forward, we need to rebuild our entire
infrastructure. In a primarily print world, we can turn to digital tools for
documents that contribute at the margins — e.g., digital scholia for a major
classical author. In the digital world, we want the scholia but we also need editions
of our canonical authors. The Editiones Principes
Electronicae for every major author are still waiting to be produced. A
new generation of editors spreads across a new and uninhabited world in which they
can acquire for themselves the digital kleos aphthiton (“undying
fame”) that the pioneers of Hellenistic Alexandria and early modern Europe
earned for themselves.
The greatest barrier that we now face is cultural rather than technological. We have
all the tools that we need to rebuild our field, but the professional activities of
the field, which evolved in the print world, have only begun to adapt to the needs of
the digital world in which we live — hardly surprising, given the speed of change in
the past two decades and the conservatism of the academy.
Perhaps the most important point of continuity — and the greatest reason why
publication in classics has adapted so little to the digital world — appears before
we even begin reading publications. An informal survey reveals that forty of
forty-one classics publications available online from Johns Hopkins University Press
(97.5%) are products of a single author — the only exception was an archaeological
publication in
Hesperia, the journal of the American
School at Athens.
[21] While expanding this survey would provide greater statistical certainty, the
conclusion would be the same: classicists in 2008 devote most of their energies to
individual expressions of particular arguments.
An even more problematic issue is that the editions, commentaries, grammars, lexica,
and other elements of scholarly infrastructure have not adapted in any significant
way to the digital world.
[22] In the five centuries since the first printed
editions of classical texts began to appear, print culture assembled an immense
amount of intellectual capital with which to support thinking about Greek and Latin
texts. This knowledge must, however, be converted into a machine actionable
form.
[23] Converting this intellectual capital from
human readable print to machine actionable knowledge is both fundamental and complex:
we need to convert statements such as “
facio, facere, feci, factum
” into something that a morphological analyzer can use to recognize a form
fecisset as the pluperfect form of the verb
facio; we need to mine from
a set of encyclopedia articles the data that will allow us to search primary and
secondary sources alike for one among dozens of historical figures named
Antigonus; we need grammars and lexica that provide not only a
handful of examples but that can also locate the phenomena that they describe in any
corpus of Greek or Latin; we need editions that can tell us precisely, how and how
often they differ from another and which previous editions and/or manuscript
witnesses they follow most closely.
More than fifteen years ago the Text Encoding Initiative (
TEI) was circulating methods with
which to create machine actionable editions that can support advanced services and,
more importantly, can be updated and maintained over time [
Sperberg 1994].
[24] The process was an
open one that invited participation from scholars in Europe and North America. Any
editor developing a capital resource such as a text, designed to serve an
intellectual community for decades to come, had an opportunity to learn how to design
a digital edition that could be printed in the short term and then maintained — and
even updated — over time.
[25] In the fifteen
years that have passed since the TEI documented how to produce digital editions, a
new generation of scholars has passed from secondary school to the faculty, but all
of the new editions of classical authors still appear as static print documents, the
rights sold to commercial publishers.
[26] If the electronic files were freely available,
they would be of limited use because their authors did not follow the guidelines that
the TEI published. Classicists have relied for the most part on the
Thesaurus Linguae Graecae (TLG) to provide searchable versions of the reconstructed texts that have
appeared — without the introductions, textual notes, indices or other scholarly
apparatus available in any digital form.
Converting digital editions to print is a particularly messy task. Editors often do
not repeat in the textual note the precise passage to which the textual note applies
— they assume that their human readers will be able to make these connections
themselves. In a recent study, Federico Boschetti applied a range of techniques with
which to associate the notes in a textual apparatus with the appropriate place in the
text. He found that these techniques could correctly associate only about 80% of the
textual notes with the text to which they referred [
Boschetti 2007].
This does not even address the task of analyzing the content of the textual notes so
that we can then pose queries such as “where does MS P differ from V by using the
same grammatical form but P and V use different dictionary words,”
“visualize the evolution of the text of Aeschylus, allowing me to see how each
edition differs from those which precede it, which editions are most closely
related to one another and which editions have been most influential,” or
“which variants have the biggest apparent impact on the text based on a range of
criteria.”
The articles in this collection reflect the most recent stage in the evolution of
digital classics and point to the future, but to appreciate that future, we need to
review major developments on which that future builds. These articles point forwards
to an emergent Cyberinfrastructure, but this Cyberinfrastructure builds upon three
earlier stages of digital classics: incunabular projects, which retain the
assumptions of print culture, knowledge bases produced by small, centralized
projects, and digital communities, which allow many contributors to collaborate with
minimal technical expertise
Digital Incunabula: the Thesaurus Linguae Graecae
(1972)
Digital incunabula are forms that replicate the established forms of print. Thus,
the TLG was, in the early 1970s, designed as a gigantic, infinitely flexible
concordance. Its texts capture the basic page layout and canonical citations of
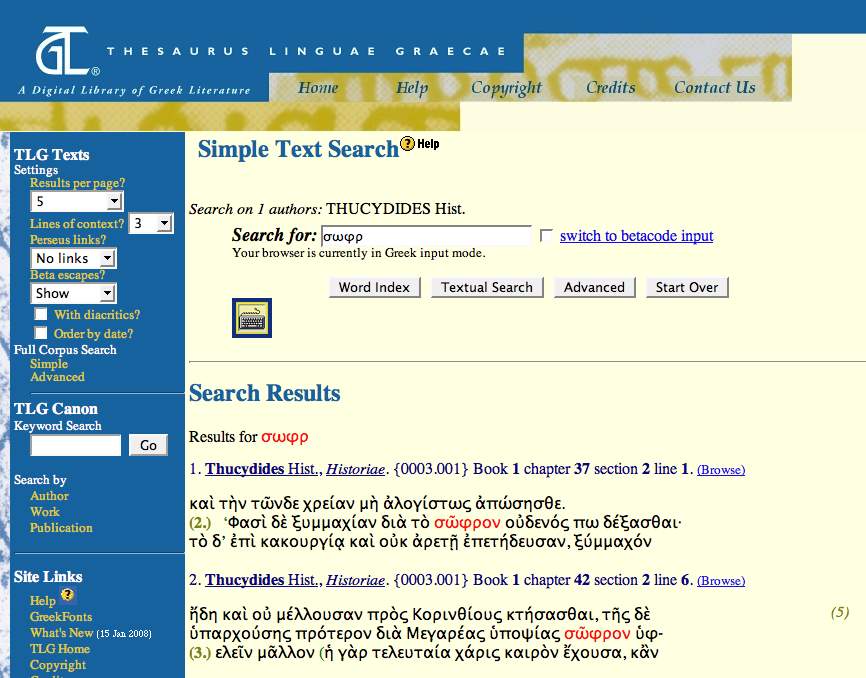
the original editions, and a sample search of it is illustrated in
Figure 1. The
Bryn Mawr Classical Review has
been successful because it used forms such as email and then the Web to produce
traditional reviews that any classicist could produce and read. The digitized
publications in
JSTOR,
Project Muse, and
Google Books provide new methods by
which to search and disseminate knowledge, but the ultimate objects of exchange
are facsimiles of exchange. These projects tend to require either very large or
very small capital investments. They focus on producing, as quickly as possible,
the same intellectual objects to which their communities are already accustomed.
In this stage of work, catalogues may grow far more elaborate — the TLG and JSTOR
allow us to search all the words in primary and secondary sources, while Google
dynamically generates maps of places and lists of frequently quoted passages
automatically extracted from its image books. All of these projects provide, in
effect, a new generation of catalogues where the books remain unchanged. The
system designers do not want to get bogged down in the specifics of any particular
domain, while the domain experts do not want to get bogged down in the technology.
Incunabular systems have been under development for a long time — there are
tenured professors of classics who were born after the TLG began work in 1972.
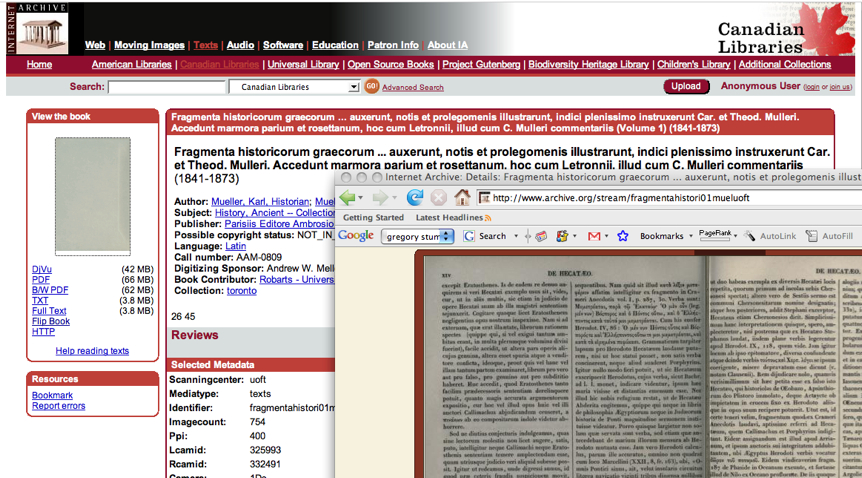
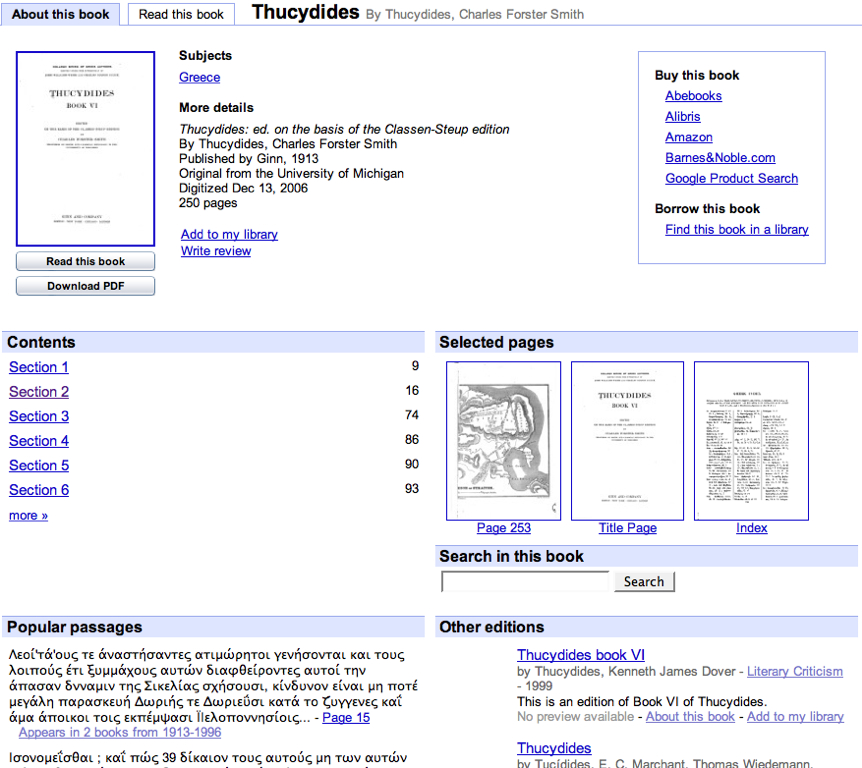
Figure 2 illustrates the generation of
incunabular systems that emerged in the 1990s with a sample text from the
Open Content Alliance (OCA),
whereas
Figure 3 illustrates a
sample from Google
Books. Where the TLG provides a fully transcribed version of source
texts, the OCA, Google Books and other projects provide only scanned page images
and such text as OCR software can generate. These projects provide noisier — and,
in the case of Greek, no — searchable text, but they index all of the text on the
page, and their accuracy will increase as OCR software becomes more
sophisticated.
[28] Also, projects such as the
OCA provide open-content licenses and encourage third parties to download and
repurpose the scanned page images. Thus, the Mellon-funded
Cybereditions Project is creating within the OCA an open source
library of Greek and Latin critical editions, on which advanced services can be
built. The scanned editions, though simple in form, provide a foundation on which
more sophisticated digital objects can be built: no license will later pull these
image books out of circulation and no license restricts the ways in which they can
circulate.
In the incunabular stage, if you retrieve a book in a language that you cannot
read or on a topic that you cannot understand, then it is your responsibility to
find a translation and any other background information you may need to make sense
of what is before you. In the incunabular stage, the center of computation is
external to the document, emphasizes general algorithms and depends upon little,
if any, domain specific machine actionable knowledge. In incunabular projects, the
physical distance between readers and publications dissolves.
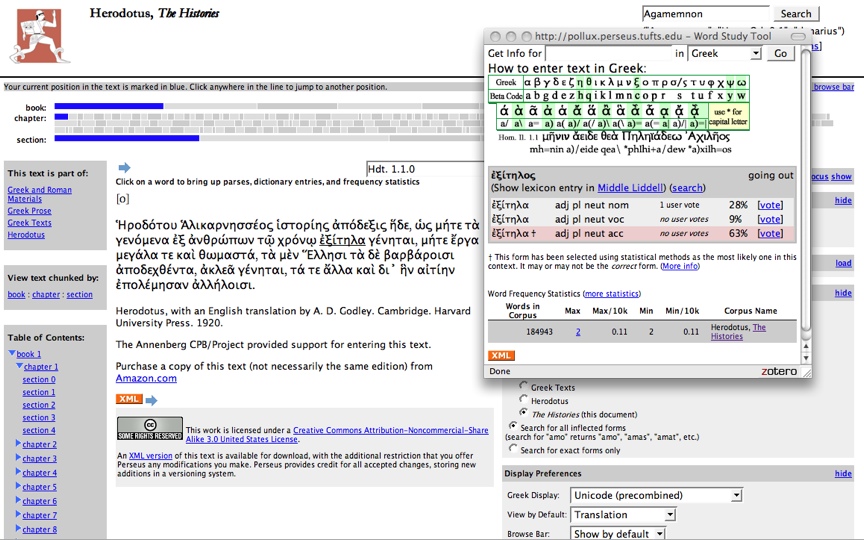
Machine-actionable knowledge bases: the Perseus Digital Library (1987)
These kinds of projects, unlike incunabular projects, set out to create knowledge
about a particular domain that machines can manipulate and that begin to move
beyond the forms of print. In classics, the Perseus Project provides an example of
such systems. Perseus set out, in the middle 1980s, to build an environment where
knowledge about the ancient world, including both the material and textual record,
could be dynamically recombined to support new forms of inquiry.
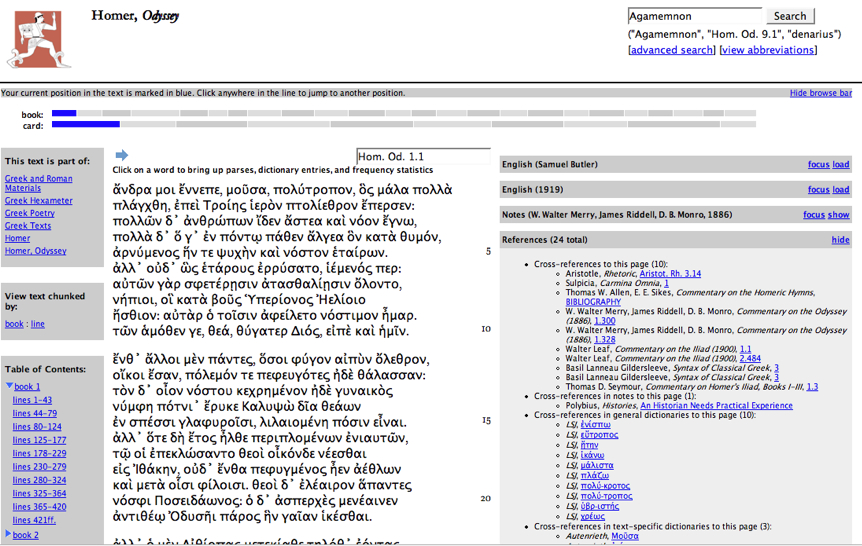
Figure 4 illustrates a sample text as it appears in
the Perseus Digital Library.The focus of Perseus was to create resources that were
in print either impractical in print (e.g., producing dozens or hundreds of high
resolution color images of for thousands of Greek vases) or impossible (e.g.,
interactive tours of archaeological sites and searching/browsing services based on
automated morphological analysis of Greek and Latin).
[29]
Semantic text markup is a characteristic feature of such projects: rather than
simply recording that a word is, for example, in italics, these systems try to
interpret the content and thus to record whether the italics indicate rhetorical
emphasis, the title of a literary work, a word quoted from a foreign language, or
some other category.
[30] As these
systems grow more intelligent, they convert an increasing portion of the content
inside the books into well-structured information that machines can process. These
systems depend upon individuals who understand the evolving relationship between
the possibilities of technology and the needs of the discipline.
[31]
Reference materials, in particular, are structured to support automatic systems
(e.g., the morphological analyzer learns Greek and Latin morphology from a machine
actionable grammar) and to be decomposed into small chunks and then recombined to
provide dynamic commentaries. If you retrieve a book in a language that you cannot
read or on a topic that you cannot understand, the system can find translations
where these already exist, machine translation and translation support systems,
reference works, and general background information suited to the general
background and immediate purposes of the reader. In knowledge bases, the
boundaries between books begin to dissolve.
Digital Communities: Stoa Publishing Consortium (1997)
Knowledge bases such as Perseus were (and, to a large extent still are), produced
by small teams of experts who bridge the gap between the technology and individual
disciplines to make documents and the ideas within them intellectually as well as
physically more accessible. Digital communities enable more people to participate
in more ways and in on-going, dynamic forms. New forms of publication such as
wikis, blogs, and various websites open up new instruments with which individuals
and groups can contribute in an on-going, dynamic fashion.
[32]
The
Stoa Publishing Consortium, founded in
1997 with a grant from the Fund for the Improvement of Postsecondary Education,
has done more than any single effort to foster the rise of digital communities in
classics. Stoa.org provided support in a variety of ways to most of the major
projects and classicists who emerged over the following decade. One such project,
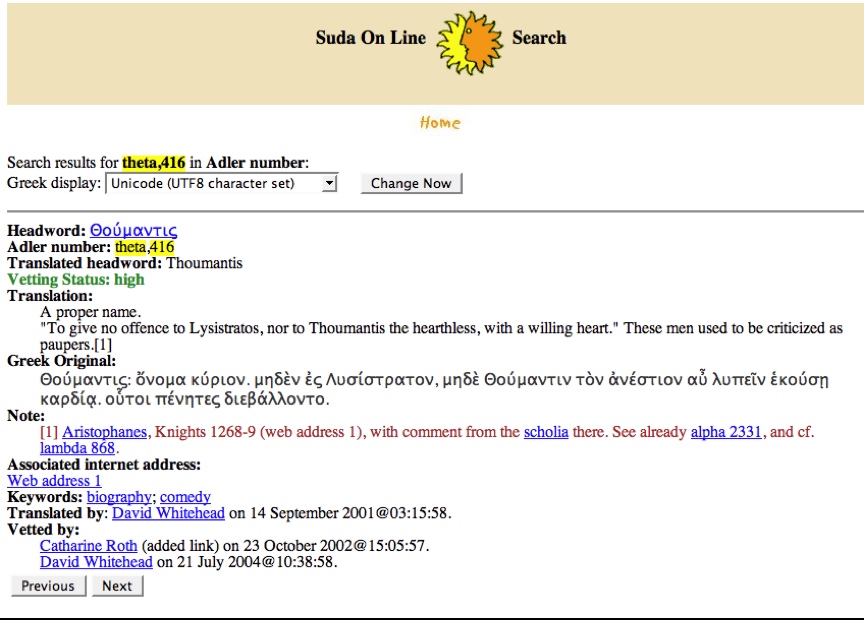
the Suda On Line, is illustrated in
Figure 5. The
papers in this collection provide an imposing, and still partial, account of the
impact which the Stoa has had.
If you examine a digital object in a digital community, you can not only find the
background information that you need to interpret that object, but you can also
make your own contributions by creating annotations directly, producing a blog
linked to the object, or in some other fashion. In digital communities, the
distinctions between author and reader and between reading and writing begin to
dissolve (as the very act of reading becomes a statement of at least initial
interest and thus a contribution).
[33]
Cyberinfrastructure
From the anvil Hephaestus rose, a huge, panting bulk,
halting the while, but beneath him his slender legs moved nimbly. The bellows he
set away from the fire, and gathered all the tools with which he was building a
silver chest; and with a sponge wiped he his face and his two hands, [415] and his
mighty neck and shaggy breast, and put on a tunic, and grasped a stout staff, and
went forth halting; but there moved swiftly to support their lord servants wrought
of gold in the semblance of living women. They possessed understanding in their
hearts, and speech [420] and strength, and they knew cunning handiwork by gift of
the immortal gods. These busily moved to support their lord.
(Homer, Iliad 18.411-421, tr. after
A. T. Murray)
The three classes of digital project outlined above reflect three different sources
of energy: the industrialized processes of mass digitization and of general
algorithms, the specialized production of domain specific, machine actionable
knowledge, and the generalized ability for many different individuals to contribute,
in ways large and small. When these three sources of energy begin to interact with
one another, the resulting environment is qualitatively different not only from print
culture but from any of the three digital environments taken in isolation. Having
reviewed some developments in the previous generation, we can now begin to consider
the implications for ePhilology (primary and secondary sources relevant to classical
Greek and Latin), eClassics (ancient Greek and Latin as they work within human
minds), and Cyberinfrastructure (the material systems whereby we exchange the objects
of our intellectual labor and ourselves internalize these objects). The following
sections describe ePhilology and eClassics. The conclusion to this collection returns
to the Cyberinfrastructure towards which the individual articles point.
Producing new knowledge: ePhilology
Any one can discourse to you forever about the
advantages of a brave defence, which you know already. But instead of listening
to him I would have you day by day fix your eyes upon the greatness of Athens,
until you become filled with the love of her; and when you are impressed by the
spectacle of her glory, reflect that this empire has been acquired by men who
knew their duty and had the courage to do it, who in the hour of conflict had
the fear of dishonor always present to them, and who, if ever they failed in an
enterprise, would not allow their virtues to be lost to their country, but
freely gave their lives to her as the fairest offering which they could present
at her feast.
(Pericles’ Funeral Oration, Thuc.
1.43.2)
If we think only in terms of word searches, the production of camera-ready copy,
image management, the ability to generate basic maps, and manually produced format
such as wikis and blogs, increased storage and computational power may seem
relatively unimportant. For anyone whose career extends more than a decade,
current technologies are astonishingly powerful. In 1982, it cost the Harvard
Classics Computing Project $34,000 to purchase a 660 megabyte disk drive to store
early versions of the TLG: the disk was the size of a washing machine, arrived in
a wooden crate, needed a special disk controller, took two days for the
technicians to install and required modifications to the version of the Unix
operating system then available. The maintenance contract cost c. $4,000/year and
was essential. As this introduction is written, $100 buys a terabyte of storage —
more than 1000 times as much storage as its 1982 predecessor for 300 times less
money, a decrease in cost of more than 300,000 in one quarter of a century. We can
now take for granted storage that was previously unimaginable, collecting huge
digital images as well as texts and datasets with little regard for the costs of
storage or computation. A generation ago, only a few of the wealthiest departments
could raise tens of thousands of dollars to provide the storage to search a few
million words of Greek and support the first generation of digital publishing. In
2008, many cell phones have more than enough storage and computational power to do
much more.
All of us in the academy and in society as a whole, of course, already depend upon
general services, such as Google, that require stunning amounts of storage and
computational power — even academics who may proudly dissociate themselves from
the web of digital services depend completely upon those services for the paper
publications that arrive in the mail and the catalogues by which they find books
on the shelf. And, of course, we already depend upon digital infrastructure for
the paychecks, medical treatments and other fundamental components of material
life. Within classical studies, it is easy to see the need for vast networked
storage and high performance computing for the analysis and visualization of
quantitative and visual evidence from the material culture.
[34]
Consider the basic problem of reading Greek and Latin. The machine-actionable
Liddell-Scott-Jones (LSJ) Greek-English and Lewis and Short Latin-English lexica
developed by the Perseus Project contain 422,000 and 303,000 tagged citations to
800 Greek and 80 Latin authors. In LSJ, half of the 422,000 citations are to a
half dozen canonical authors. For Lewis and Short, the top dozen authors account
for more than two-thirds (215,000) of the citations.
Not all lexicographic projects have such narrow focus, but extensive lexicographic
coverage is extraordinarily labor intensive. The
Thesaurus
Linguae Latinae (TLL) is building a lexicon that covers Latin from
earliest times through AD 600 and bases its work on an archive of 10,000,000 slips
with information about particular words. The TLL in 2008 boasts a staff of twenty
Latinists, began work in 1894, published its first fascicle, and has been an
international project since 1949. Its official website promises that the TLL will
during 2009 “reach the end of the letter P, at
which point more than two thirds of the complete work will have
appeared”.
[35]
The ten million or so words of ancient Latin may require more then a century of
labor, but they constitute, of course, a relatively small corpus. The TLG had
accumulated 99,000,000 words in 2007.
[36] An
individual Latinist, Johann Ramminger, had accumulated a wordlist of later Latin
from Petarch up through 1700 that was based on 200,000,000 words of text already
available in digital form. Semi-automated methods involving computerized data but
still dependent upon manual analysis of each form may increase productivity by a
factor of two or three, but simply enhancing traditional approaches would require
centuries to provide us with truly comprehensive lexica of Greek and Latin.
No branch of scholarship is probably older than lexicography, but our traditional
methods do not scale up to the challenges of representing textual materials in
Greek and Latin. We have no choice but to exploit, as vigorously as we can,
automated methods. The essay by
Bamman and Crane in this collection describes some of these methods as
they exist today. The essay by
Finkel and Stump illustrates how automated methods can reconfirm — but
place on a profoundly new foundation — ancient analytical instruments such as the
reduction of Latin verbs to a four dimensional space defined by the traditional
principal parts.
Ultimately, automated and manual methods reinforce one another. Decisions embedded
in print reference materials such as lexica, indices, and grammars can be, at
least in part, extracted and converted into machine actionable data. In effect,
human annotators provide the examples and rules from which automated systems
learn. The automated systems present the results of what they learn when they work
with new materials. Human readers then correct and augment the automated results.
The automated systems recalculate their statistical models and then
recalculate.
[37] In a mature system, we separate training
data from test data so that we can automatically measure the impact that our
changes have upon performance.
Complex algorithms can be computationally demanding even when we are working with
small corpora. In preliminary work on sense detection in 2005, we found that by
comparing five different translations with the 150,000 Greek words in Thucydides
we can identify words with many senses in Thucydides: e.g., passages where the
Greek word archê corresponds to “beginning” or to “empire”. It took days
of processing power from a single CPU to identify clusters of word senses in five
translations of the 150,000 words in Thucydides.
[38] Even if we shift to these algorithms, analyzing millions of
words and thousands of translations in a half dozen languages would require more
computational power than any desktop system could readily deploy.
The infrastructure of 2008 forces researchers in classics and in the humanities to
develop autonomous, largely isolated, resources. We cannot apply any analysis to
data that is not accessible. We need, at the least, to be able gather the data
that is available today and, second, to ensure that we can retrieve the same data
in 2050 or 2110 that we retrieve in 2010.
[39] We need digital
libraries that may be physically distributed in different parts of the world but
that act as a single unit: we need to be able to pose queries such as “find all
Greek editions and modern language translations of Aeschylus,
Persians, lines 1-40” and retrieve machine
actionable results from a variety of sites.
[40]
There are two components to this problem. First, we need libraries that can
preserve collections in the digital world as they have preserved them in the print
world. The institutional repository movement is slowly addressing this
challenge.
[41] Thus, the publications in this
collection are a part of a long-term institutional repository that can manage
static expository prose with very general features such as sections, footnotes,
bibliography etc.
We need, however, more than digital preprints. A second component is the need for
sophisticated citation and reference linking services. Smith’s paper in this
collection,
“Citation in Classical Studies”, describes the system of canonical text citations by which classicists
identify precise chunks of text within the surviving corpus of classical Greek and
Latin. The
Canonical Text Services (CTS) described in this piece begin where
library catalogues end and provide furthers layers of granularities essential for
classical scholarship: the CTS provides a common language whereby we can aggregate
information about particular lines in the
Iliad or a
numbered section from a chapter in Thucydides.
[42]
The TEI has developed a shared language whereby humanists can describe the same
phenomena in similar ways so that we can more readily combine documents produced
by different groups. The TEI has many different methods, however, and it is
possible to represent the same phenomenon in many different TEI-compliant ways.
Cayless et al. describes
how experts in Greek inscriptions as a community adapted the very general TEI
framework to their needs, allowing classicists to create documents that are
increasingly interoperable and easy to maintain over time.
Robertson documents research in
methods to describe historical events in a format that is not only machine
actionable but language independent, contributing to the production of
multilingual scholarship.
Dué and
Ebbott describe editorial standards for a new generation of dynamic
digital editions. These new editions do not simply provide a single best attempt
at reconstructing a single text but can dynamically represent multiple versions of
the text as it has appeared over time and provide databases of variants,
conjectures, testimonia and other materials.
Elliott and Gillies look more
generally at how we can then build on these and other services to manage
geographic information about the ancient world in new ways. Wikipedia has provided
a famous and famously successful model for distributed authorship, but classicists
had already begun pioneering such systems in the 1990s.
Mahoney’s article describes the
infrastructure for the Suda On Line project, which has produced translations for
more than 24,000 entries of a fundamental reference work about the classical Greek
world produced in 10th century Byzantium. At the same time,
Finkel and Stump illustrate how
methods from computer science can manage such fundamental structures as Latin
morphology.
And, of course, only a small part of the printed record relevant to classical
Greek and Latin has been — or will be — carefully transcribed and edited. If we
begin to consider the challenge of extracting and analyzing information about
classical Greek and Latin scattered throughout very large collections of books
available as scanned page images, the challenges of storage and computation become
daunting. The collection of essays thus ends with articles about converting print
materials into a form that can support the kinds of services that the previous
articles have articulated.
Rydberg-Cox describes the issues involved in trying to convert early
printed scholarship into a machine actionable form. Later publications lend
themselves much more readily to automated analysis.
Crane et al. consider the
problems and opportunities that emerge for classics as whole research libraries
become available in digital form.
Infrastructure includes not only data, services and physical systems but the
social practices as well.
Figure 6 illustrates some
of the particular elements of the cyberinfrastructure needed for philology. The
papers in this collection illustrate shifts in the practices of classicists as a
new cyberinfrastructure develops:
-
Expository argumentation: While new forms of
scholarship and new intellectual practices are taking shape, we should
emphasize that the collection published here reflects the on-going need for
expository arguments that articulate particular points of view constructed
at a particular time. Nevertheless, even when the superficial form of
argumentation remains largely traditional in form, the substitution of
dynamic links for static citations can exercise a major impact upon the
content and the audience that publications can reach. Stoa.org was founded
in 1997 to support, among other things, new forms of publication that would
provide rich links to original sources while bringing classics to a broader
audience. Thomas Martin’s Overview of Classical Greek History in the Perseus Digital Library and Ross Scaife’s Diotima, an electronic publication on gender in antiquity, did much to
inspire this goal. All of the publications associated with the Stoa
illustrate forms of publication that were not feasible a generation ago.
Christopher Blackwell’s Demos: Classical Athenian Democracy illustrates how a publication that is traditional in form can exploit
online evidence and publication to provide better documentation on a major
subject to a wider audience than was feasible in print.
-
Collaboration: While the final form of the papers
in this collection may be familiar, their production and content reflects a
fundamental change in scholarly practice: the majority of the papers
published here have multiple authors, while the single-author papers either
report on group projects or on general methods whereby classicists can
create interoperable data.
-
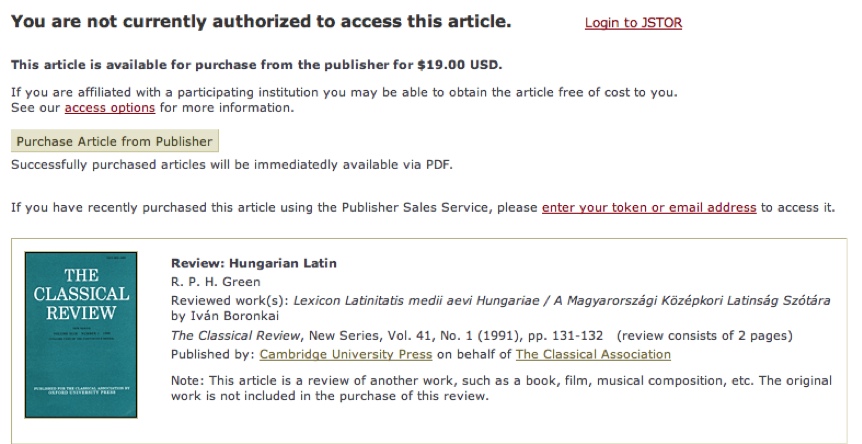
Open access and open source production: All of
the scholars who have contributed to this collection depend upon open access
and open source production. In contrast, Figure
7 illustrates an example of a much more closed form of access. In
cases where authors are making particular arguments at a particular point in
time, open access allows third parties to locate and automatically analyze
what they have produced: search engines such as Google can index and then
deliver their arguments to anyone online; more specialized text mining
systems could analyze what has been written to search for trends in
scholarship or to apply specialized services designed for classics (e.g.,
the ability to recognize strings such as “Thuc. 1.86” as citations to
primary sources).
The authors of these papers represent, however, a greater advance than the work
that they have produced so far. In part, this reflects the hope that they will
produce even more in the future. They also represent a new community, one large
enough to foster junior scholars within the field, and in this way they may
indirectly spawn far more productive work than all of them could in the aggregate
produce during their own careers. But more significant than any output is the
sense within this community that the field of classics is being reborn and that
limitations with which many of us grew up are no longer relevant. This new digital
world not only changes what we can do but who can do what. The collection of
essays thus opens with
Blackwell and
Martin’s article about undergraduate research. Before introducing that
discussion, we need return to the broader topic of classics and the humanities in
a digital environment that has begun to increase the intellectual reach of
humanity as a whole
Extending the intellectual reach of humanity: eClassics &
eHumanities
In short, I say that as a city we are the school
of Hellas; while I doubt if the world can produce a man, who where he has only
himself to depend upon, is equal to so many emergencies, and graced by so happy
a versatility as the Athenian.
(Pericles’ Funeral Oration, Thuc.
2.41.1)
We look to a new digital infrastructure not only so that we can increase the body
of published information about classical Greek and Latin but so that these
languages can play an increased role in the intellectual life of humanity. We can
do this in two ways. First, we can create environments that more fully engage
those already working with Greek and Latin — we have already begun to address this
by creating searchable corpora of Greek and Latin, by making secondary sources
available online as PDF files or by adding links between inflected words in a text
and their dictionary entries and thus reducing time spent flipping large
dictionaries. These all reduce the time between when we pose a question and when
we receive an answer. It would be hard to overstate the degree to which
cost-benefit decisions, often unconscious, shape the directions that we take in
our intellectual lives. Classicists have for millennia understood the difference
between being in a small, poorly organized collection and a large collection in
which it is easy to find what we want. Cyberinfrastructure provides new threads
that we can follow through the vast body of published information.
The second way to increase the role of classical Greek and Latin is to engage more
people in reading and thinking about these languages. Anecdotal evidence suggests
that this began to happen as soon as substantial bodies of Greek and Latin became
available to the general public. Perseus quickly received letters from students in
isolated locations such as rural homes and naval vessels at sea who were using
online lexica and texts. Even more interesting, people who had studied Greek and
Latin decades before found that the reading support tools available online gave
them the support that they needed to begin reading Greek and Latin again.
The first paragraph in the opening “Call to action” of
the National Science Foundation’s 2007 “Cyberinfrastructure
Vision for 21st Century Discovery” calls for “an
individualized health model of every human being for personalized health care
delivery” (
“Cyberinfrastructure Vision for 21st Century
Discovery”, March 2008: page 5). Such models would open up new methods where doctors
and patients could not only determine the best courses with which to treat disease
but also to identify potential problems and predispositions in advance. Health
records that include decades of medical tests and case histories clearly raise
daunting issues of confidentiality, but the potential benefits are enormous.
Emergent cyberinfrastructure for health care includes thus both methods to
represent our particular background in great detail and a major investment in
maintaining personal privacy.
The same instruments developed for health care can be adapted for our intellectual
backgrounds. We can begin to devise ways for us to keep track of what we have
learned so that we can receive background information customized for our
particular needs when we confront a new object of study.
[44]
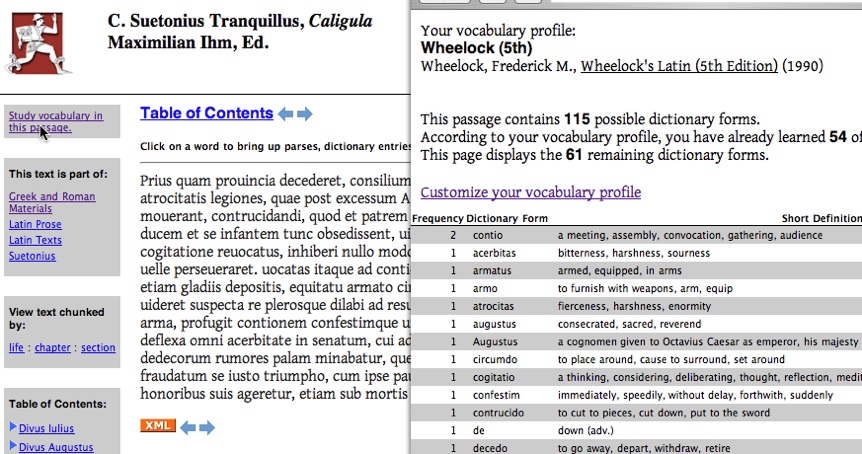
Figure 8 illustrates a system that compares an
arbitrary text of Latin against a model of the vocabulary that a particular reader
has encountered, then calculates which words have been seen before and which are
new. Seen words can then be associated with the places where they have been seen
in the past, while unseen words can be ranked by their importance according to
various criteria (e.g., numerical frequency, relevance to a particular theme etc.)
The implementation is conceptually simple but represents the first stage at an
open-ended process. As our data sources improve, we can look for more complex
linguistic phenomena such as syntax and semantics (e.g., a new sense of a seen
word). As our learning models grow more sophisticated, we can begin helping
readers identify areas of weakness on which they can focus to enhance their
ability to read with fluency.
Even small advances in our ability to work with multiple languages can be
important if they open up historical languages to new audiences, whether these
audiences are professional researchers using more linguistic sources or members of
the public reading Greek poetry that they would not otherwise have experienced.
The biggest benefits are likely to come when we open up linguistic materials to
audiences with little or no training in the language. None of us has the
opportunity to become familiar with more than a handful of languages. None of us
can, in print culture, work with un-translated sources in dozens of languages.
Classics can, however, show how knowledge about an ancient culture can be designed
to serve the speakers of multiple languages. The traditional method is for
communities to choose a lingua franca — Akkadian, Greek, Latin, French, German,
and now English have all served as common languages of diplomacy and scholarship.
The speakers of an unbounded set of local languages communicate by learning one of
these linguae francae — thus, the Chinese businessman in a Damascus hotel will
probably carry on his business in English. Classicists are more broad-minded but
generally expect scholars to publish materials in English, French, German and
Italian. Speakers of Croatian or Modern Greek must learn these languages if they
are to gain access to most information about the Greco-Roman world.
Classicists can, however, design their cyberinfrastructure from the start to be as
portable as possible across multiple languages. There are at least three basic
strategies, the third and most important of which is peculiarly suitable to
historical fields where primary sources are finite and heavily studied.
First, we need to be able to optimize machine translation for the field of
classics.
[45] We can develop statistical models that
capture the idiosyncrasies of documents about Greco-Roman culture. We develop
these models by adding markup, using a combination of manual and automated
methods, to finite bodies of material as training sets. Machine learning systems
then scan these bodies and recognize that Alexandria usually refers to the city in
Egypt and almost never to the suburb of Washington, DC, by that name. An ambiguous
word such as “case” probably designates a grammatical case in a Greek grammar and
a display case in a museum catalogue. These domain specific features, once
identified, can help general machine translation systems avoid many of the worst
problems they face and improve the quality of their output.
Second, we need to include as much basic information as we can in forms from which
they can be converted into multiple languages. Thus, if we represent birth and
death dates in a generic form, we can then develop modules to represent that
knowledge in multiple languages.
[46] Some ontologies such as the
CIDOC-CRM for museum objects and
FRBR for books have
been under development for years and can represent a great deal of basic
background information.
[47]
Third, canonical literary texts attract very large amounts of labor. We can use
that labor to create databases of linguistic annotations that describe syntax
(e.g., the subject and object of a verb), co-reference (e.g., which person is the
subject of a particular verb), semantics (e.g., where does
oratio
correspond to “prayer” rather than “oration” or some other concept).
These annotations stored in treebanks and other linguistic databases not only
allow us to put our understanding of Greek and Latin on a wholly new, quantifiable
foundation but can resolve the ambiguities that bedevil machine translation and
can ultimately support higher quality machine translation.
[48] Such
annotations are expensive but are, in effect, the digital successors to print
editions. Where print editors labored to resolve ambiguities and problems in the
textual tradition, digital editors provide machine actionable annotations that
resolve where possible ambiguities in the reconstructed texts.
The problem of multilingual knowledge thus breaks down into language independent
and language dependent phases.
Knowledge bases (e.g., basic propositional statements) and linguistic annotation
can be created by speakers of any language. The tag sets of ontologies and
annotation schemes are relatively contained and can themselves be translated,
allowing authors to work entirely with Greek, Latin and their own primary
languages: the birthdate of a given author may be uncertain but that uncertainty
can be represented in a general form by the speaker of any language. We may differ
in how we construe the syntax of a sentence, but anyone who knows Greek,
regardless of their native language, can decide which word depends on which and
represent this in a common format.
Communities that want to make publications in their own languages accessible to
wider audiences will have to develop the training sets for documents about
classics. The results will not be perfect but readers can then use dictionary
lookups and other translation aids to more closely study the original language.
Each language needs its own training sets but this approach will not only make
publications in the traditional languages of publication accessible to wider
audiences but will also open up publications in less widely read languages (e.g.
Croatian and Dutch) to much larger audiences.
Communities that want to be able to read basic knowledge about the Greco-Roman
world in their own language will need machine translation that can be optimized
for classics and language specific drivers that can convert the basic knowledge
from ontologies into their language, and systems that can exploit the dense
linguistic annotations available for major canonical source texts.
The creation of knowledge bases designed from the start to flow from language to
language would be a radical change from traditional scholarly practice.
Nevertheless, there are profound strategic reasons for this new form of
scholarship in the two major classes of society that produce scholarship about the
Greco-Roman world.
Classical Greek and Latin are the foundational languages of Europe and were the
languages of high culture and trans-European discourse until relatively recent
times — in fact, Turkey, whatever its religious background, would only restore to
Europe a region that had been lost to it from the past. The European Union has a
commitment to make the cultural heritage of its nations intellectually accessible
to the widest possible audience. This implies an infrastructure that maximizes
what can be learned not only in English, French, German, and Italian, but in all
of the other official languages of Europe.
[49]
The United States, Canada, Australia, New Zealand, and South Africa are, however,
not only geographically distinct from Europe but are fashioning themselves into
cosmopolitan societies, European in origin but creating new identities with roots
from every civilization of humanity. The United States has in particular
identified Chinese and Arabic as the two strategic languages on which it will
concentrate its resources. While Europe concentrates on making its cultural
heritage accessible to the speakers of its official languages, American scholars
can take the lead in making classical antiquity increasingly accessible to
speakers of Chinese, Arabic and other languages. Ultimately, the increased
distribution of Greco-Roman cultural materials into many other languages will
speed the complementary process of opening up materials in classical Chinese,
Arabic, Sanskrit and other languages to speakers of English and other European
languages. Our larger goal must be to make the record of humanity accessible to
everyone regardless of linguistic and cultural background.
While a linguistically and culturally portable knowledge base about the
Greco-Roman world may seem daunting, the tools already at hand allow us to rethink
not only who can read and consume primary and secondary sources but who can
contribute substantively to the field.
Blackwell and Martin’s essay
opens this collection by describing how the practices of undergraduates have begun
to change. The rise of undergraduate research is arguably the most important and
promising development for classics as a discipline since classics lost its
privileged position. Before we can appreciate the possibilities of the technology
now available but not yet fully exploited, we need to see how much classicists
have already begun to accomplish.
Before turning to the prospects for undergraduate and more general non-specialist
research in classics, we should emphasize that the collection of essays published
here themselves illustrate the greatest achievement of classical philology in this
digital world. We now have a critical mass of classicists who are committed to
building and exploiting the evolving digital infrastructure upon which all
scholarship and teaching in our field will depend. While discussions of digital
humanities still revert to the problem of tenure and promotion, several of the
contributors to this collection have already earned tenure by pursuing digital
projects. All of the authors here are able to review innovative forms of digital
scholarship on its intellectual merits, neither penalizing or rewarding the use of
digital technologies per se but assessing the degree to which the new work
advances our ancient and unchanging goals to bring the Greco-Roman heritage in
general and ancient Greek and Latin in particular ever more fully to life in the
minds of the broadest audience possible.
No one showed more vision and patience to create this community than our colleague
and beloved friend, Allen Ross Scaife. He showed the way with his own pioneering
work on Diotima, a digital representations of women
in antiquity. As director of the Stoa from its
founding until his death ten years later, Ross always understood that the greatest
resource for any field was the people whom it attracted. Ross supported, fostered,
encouraged, and advanced careers that will continue now for decades and will shape
other careers as well. “Do not lament,” the
Pericles of Thucydides (1.143.5) tells the Athenians, “houses and land but people, for it is not houses and land that
acquire people but people who acquire them.” The passing of Ross Scaife
wounds the field of classics more deeply than would have the loss of everything
that the field as a whole has produced. But the community that Ross fostered with
intelligence, patience and love and that produced these essays is greater than any
single achievement that their authors could ever produce.
Works Cited
Agosti 2007 Agosti, M. et al. “Roadmap for Multilingual Information Access in the European
Library.” In Proceedings of the ECDL 2007:
136-147.
Borin 2007 Borin, L. et al. “Naming the Past: Named Entity and Animacy Recognition in 19th
Century Swedish Literature.” In
Proceedings of the
Workshop on Language Technology for Cultural Heritage Data (LaTeCH 2007):
1-8.
http://www.aclweb.org/anthology-new/W/W07/W07-0901.pdf.
Buckland 2007 Buckland, M. “The Digital Difference in Reference Collections.”
Journal of Library Administration, 46:2 (2007):
87-100.
Busa 1974 Busa, R. Index Thomisticus. Stuttgart: Frommann-Holzboog, 1974.
Busa 1980 Busa, R. “The Annals of Humanities Computing: The Index Thomisticus.”
Computers and the Humanities, 14:2 (1980): 8390.
Cantara 2006 Cantara, L. “Long term Preservation of Digital Humanities Scholarship.”
OCLC Systems & Services, 22:1 (2006): 38-42.
Chi 2007 Chi, E. H. et al. “ScentIndex and ScentHighlights: Productive Reading Techniques for
Conceptually Reorganizing Subject Indexes and Highlighting Passages.”
Information Visualization, 6:1 (2007): 32-47.
Cosley 2006 Cosley, D. et al. “Using Intelligent Task Routing and Contribution Review to Help
Communities Build Artifacts of Lasting Value.”
CHI '06: Proceedings of the SIGCHI conference on Human Factors
in computing systems: 1037-1046.
Crane 2006c Crane, G. and A. Jones.
“The Challenge of Virginia Banks: an Evaluation of Named
Entity Analysis in a 19th-Century Newspaper Collection.” In
JCDL '06: Proceedings of the 6th ACM/IEEE-CS joint conference on
Digital libraries: 31-40.
http://dl.tufts.edu/view_pdf.jsp?pid=tufts:PB.001.001.00007.
Csomai 2006 Csomai, A. and R.
Mihalcea. “Creating a Testbed for the Evaluation of Automatically
Generated Back-of-the-Book Indexes.” In
Conference on
Computational Linguistics and Intelligent Text Processing (CICLing), 2006.
http://www.cse.unt.edu/~rada/papers/csomai.cicling06.pdf.
Dalbello 2006 Dalbello, M. et al.
“Electronic Texts and the Citation System of Scholarly
Journals in the Humanities: Case Studies of Citation Practices in the Fields of
Classical Studies and English Literature.” In
LIDA
2006: Proceedings of Libraries in the Digital Age,
http://dlist.sir.arizona.edu/1638/.
Dekhtyar 2006 Dekhtyar, A. et al.
“Support for XML Markup of Image-Based Electronic
Editions.”
International Journal of Digital Libraries, 6:1 (2006):
55-69.
Don 2007 Don, A. et al. “Discovering Interesting Usage patterns in Text Collections:
Integrating Text Mining with Visualization.” In
CIKM
'07: Proceedings of the sixteenth ACM conference on Conference on Information and
Knowledge Management: 213-222.
http://hcil.cs.umd.edu/trs/2007-08/2007-08.pdf.
Gatos 2006 Gatos, B. et al. “An Efficient Segmentation-Free Approach to Assist Old Greek
Handwritten Manuscript OCR.”
Pattern Analysis & Applications, 8:4 (2006):
305-320.
Geleijnse 2007 Geleijnse, G.
and J. Korst. “Creating a Dead Poets Society: Extracting a Social
Network of Historical Persons from the Web.” In
Proceedings of the Sixth International Semantic Web Conference and the Second
Asian Semantic Web Conference (ISWC + ASWC 2007): 156-168.
http://iswc2007.semanticweb.org/papers/155.pdf.
Heilman 2008 Heilman, M. et al.
“Retrieval of Reading Materials for Vocabulary and Reading
Practice.”
Proceedings of the Third ACL Workshop on Innovative Use of NLP
for Building Educational Applications, 2008: 80-88.
http://aclweb.org/anthology-new/W/W08/W08-0910.pdf.
Hockx-Yu 2006 Hockx-Yu, H. “Digital Preservation in the Context of Institutional
Repositories.”
Program: Electronic Library & Information Systems,
40:3 (2006): 232-243.
Jones 2007 Jones, G. J. F. et al.
“Multilingual Search for Cultural Heritage Archives via
Combining Multiple Translation Resources.” In
Proceedings of the Workshop on Language Technology for Cultural Heritage Data
(LaTeCH 2007): 81-88.
http://www.aclweb.org/anthology-new/W/W07/W07-0911.pdf.
Kolak 2008 Kolak, O. and B. N. Schilit.
“Generating Links by Mining Quotations.” In HT '08: Proceedings of the nineteenth ACM conference on Hypertext
and hypermedia: 117-126.
Kraft 2005 Kraft, J. C., Rapp, G.,
Gifford, J. and Aschenbrenner, S., “Coastal Change and
Archaeological Settings in Elis”, in Hesperia
74 (2005): 1-39.
Lagoze 2006 Lagoze, C. et al. “Metadata Aggregation and Automated Digital Libraries: a
Retrospective on the NSDL Experience.”. In JCDL '06:
Proceedings of the 6th ACM/IEEE-CS joint conference on Digital Libraries:
230-239.
Lu 2008 Lu, X. et al. “A
Metadata Generation System for Scanned Scientific Volumes.” In JCDL '08: Proceedings of the 8th ACM/IEEE-CS joint conference on
Digital libraries: 167-176.
Luce 2008 Luce, R. E. “A New Value Equation Challenge: The Emergence of E-Research and
Roles for Research Libraries.” In
No Brief Candle:
Reconceiving Research Libraries for the 21st Century. CLIR 2008: 42-50,
http://www.clir.org/pubs/reports/pub142/pub142.pdf.
Marshall 2008 Marshall, C. C.
“From Writing and Analysis to the Repository: Taking the
Scholars' Perspective on Scholarly Archiving.” In JCDL
'08: Proceedings of the 8th ACM/IEEE-CS joint conference on Digital
libraries: 251-260.
Moalla 2006 Moalla, I. et al. “Image Analysis for Palaeography Inscription.” in DIAL 2006: Document Image Analysis for Libraries:
303-311.
Monroy 2007 Monroy, C. et al. “A Multilingual Approach to Technical Manuscripts: 16th and
17th-century Portuguese Shipbuilding Treatises.” In JCDL '07: Proceedings of the 2007 conference on Digital libraries:
413-414.
Plaisant 2006 Plaisant, C. et al.
“Exploring Erotics in Emily Dickinson's Correspondence with
Text mining and Visual Interfaces.” In JCDL '06:
Proceedings of the 6th ACM/IEEE-CS joint conference on Digital libraries:
141-150.
Riva and Zafrin 2005 Riva, M. and V.
Zafrin. “Extending the Text: Digital Editions and the
Hypertextual Paradigm.” In HYPERTEXT '05: Proceedings
of the sixteenth ACM conference on Hypertext and hypermedia:
205-207.
Robinson 2000 Robinson, P. “The One Text and the Many Texts.”
Literary and Linguistic Computing, 15:1 (2000):
5-14.
Romanello 2008 Romanello, M.
“A Semantic Linking Framework to Provide Critical Value- Added
Services for E-Journals on Classics.” In
ELPUB2008.
Open Scholarship: Authority, Community, and Sustainability in the Age of Web 2.0 -
Proceedings of the 12th International Conference on Electronic Publishing.
http://elpub.scix.net/cgi-bin/works/Show?401_elpub2008.
Schilit 2008 Schilit, B. N. and O.
Kolak. “Exploring a Digital Library through Key Ideas.” In
JCDL '08: Proceedings of the 8th ACM/IEEE-CS joint conference
on Digital libraries: 177-186.
Simeoni 2007 Simeoni, F. et al.
“A Grid-Based Infrastructure for Distributed
Retrieval.”
Proceedings of the ECDL 2007: 161-173.
Smith 2001 Smith, D.A. and G. Crane.
“Disambiguating Geographic Names in a Historical Digital
Library.” In
ECDL '01: Proceedings of the 5th European
Conference on Research and Advanced Technology for Digital Libraries:
127-136,
http://perseus.mpiwg-berlin.mpg.de/Articles/geodl01.pdf.
Sperberg 1994 Sperberg-McQueen,
C. M. and L. Burnard, Eds. Guidelines for Electronic Text
Encoding and Interchange. Chicago and Oxford: Text Encoding Initiative,
1994.
Trnkoczy 2006 Trnkoczy, J. et al.
“A Grid-Based Architecture for Personalized Federation of
Digital Libraries.”
Library Collections, Acquisitions, and Technical
Services, 30:3-4 (2006): 139-53.
United 1880 United States. War Dept.,
United States. War Dept. War Records Office., et al. The War of
the Rebellion: a compilation of the official records of the Union and Confederate
armies. Washington, Govt. Print. Off., 1880.
van 2006 van Gendt, M. et al.
“Semantic Web Techniques for Multiple Views on Heterogeneous
Collections: A Case Study.” In Proceedings of ECDL
2006: 426-437.