Abstract
In this article, we discuss the main challenges in finding and extracting translation data from national library
catalogues and the literary press and propose solutions for researchers to access and analyze bibliographic data
for translations. To illustrate these issues, we present two case studies: the first being dedicated to translation
invisibility in the literary press, i.e., specialized and general literary journals and magazines, discussing
overall trends in the Canadian literary press and giving specific examples from the Quill
& Quire and the Montreal Review of Books. The second deals with the
institutional practices of collecting and cataloguing translations according to metadata standards at three
national libraries: the German National Library (DNB), the Austrian National Library (ÖNB), and the Bibliothèque et
Archive nationales du Québec (BAnQ). By doing so, we problematize how the cataloguing, collecting, and reviewing of
translated material can be viewed as a systemic issue, highlighting the parallels between these different types of
practices. We hope to broaden the understanding of translation invisibility by looking at how institutional,
cultural, and editorial practices inform the cataloguing, collecting, reviewing, and publishing of
translations.
Quantitative Translation Studies in the Digital Humanities
Though translation scholars such as Diana Roig-Sanz and Laura Fólica have advocated for and categorize research
that applies computational methods to translation history
[1], a brief look at some important research
outlets illustrates that quantitative translation research occupies a marginal position in the Digital Humanities
(DH). At the 2023 Alliance of Digital Humanities Organizations conference, for instance, a total of seven papers
and one panel on translation research are scattered in a programme of over 200 presentations
[2]. At the 2023 Digital Humanities Summer Institute, no workshop or talk on translations was
offered
[3]. This sparsity of quantitative
translation research can also be observed in DH scholarly publications. In
Digital Humanities
Quarterly, one of the central outlets for DH research, we could find only a single title [
Palladino, Foradi, and Tariq 2021] that explicitly mentions translations or their data in the last five years. The same
is true for the
International Journal of Humanities and Arts Computing [
Ngué Um et al 2022].
Current Research in Digital History as well as
Digital Studies / Le champ numérique
do not have any articles on translation from the last five years. The one exception seems to be
Digital Scholarship in the Humanities: a search for the keywords “corpus-based translation
studies” reveals 582 articles, while “quantitative translation” reveals 377. The majority of these results,
however, pertain to machine translation, which shows how challenging it can be to find and identify research that
applies quantitative methods in literary translation studies.
While a comprehensive review of the state of quantitative translation studies in DH beyond these few exemplary
environments is certainly required, this quick overview nevertheless illustrates an absence of translation data and
its analysis in DH, which, as we argue in this article, goes hand in hand with the invisibility of translation
itself. On the one hand, the phenomenon has been extensively discussed by translation scholars
[4], though this has mostly resulted in a textual conceptualization of the
translator’s invisibility [
Venuti 1995] [
Rybicki 2012]. On the other hand, the
invisibility of translations themselves has been only marginally addressed in terms of the challenges posed by
bibliography-based quantitative translation studies [
Roig-Sanz and Fólica 2021]; [
Zhou and Sun 2017]; [
Pickford 2016]; [
Smith-Yoshimura 2017]. This paper is
dedicated to this very issue and aims at broadening our understanding of the invisibility of translations by
looking at the institutional, cultural, and editorial practices involved in the cataloguing, collecting, reviewing,
and publishing of translations. These problems go beyond a textual understanding of translation invisibility toward
a data-driven one. Some of these issues, such as the relative availability but dispersion of historical translation
data [
Belle 2023, 798–799] and the limitations of DH methods with regard to translations [
Wakabayashi 2019, 141–143], have already been discussed. In contrast, we argue that this aspect,
that is, the invisibility of translations in the literary press, academic journals, national library collections,
and web archives, speaks to overarching institutional, cultural, and editorial practices.These facts thus challenge
DH to rethink some of its tools in the light of the specific characteristics of translations.
Translation Invisibility and Bibliographic Data
Translation invisibility occurs at various levels in the publication process. For example, a translator’s name is
unlikely to be found on the cover of their work. In Canada, where such translation credit is legally required, over
35% of translators still struggle to have their name printed on the front page of their publications [
Whitfield 2013, 218 and 225]. On a larger scale, translations are often ignored by literary
reviewers. Recent studies on translation reviews in publications like
The New York Review of
Books (USA),
The London Review of Books (UK),
The Times
Literary Supplement (UK),
Le Monde des livres (France), and
Domenica (Italy) [
Monti 2013] [
Monti 2016] [
Wardle 2020] reveal that translation researchers do not even bother quantifying translation credit
because it occurs so infrequently. According to the translation database established by Chad Post for
Three Percent, translations represent approximately 1% of the book market in the United
States [cited by
Monti 2016].
Ironically, what initially prompted the development of the
Three Percent translation
database was the lack of statistics on translations in the book market. Book publishing reports only marginally
include records on translations. For instance, the Federation of European Publishers’ book market statistics does
not include any mention of translations [
Levi and Turrin 2023]. Though other organizations — such as
Literature Across Frontiers (LAF) — have been reporting translation percentages in the book market [
Budapest Observatory 2011], the most recent global picture of translation from 1990–2005 stresses the central
position of Germany with 7.9% of all literary translations. However, no such reports have been produced for 2022 or
2023, and publishing data remain inaccessible
[5]. Limited access
to data on translations and the book market, and statistics on fiction especially, thus contribute to the
marginalization and invisibility of translation to readers, publishers, and researchers.
From these examples, we see that while invisibility is indeed a hurdle for quantitative studies of translation, it
is also revelatory, a finding in and of itself. The few existing translation metrics can inform us about literary
flows between literary catalogues, or lack thereof, and about the agents involved in constituting and reviewing
these objects. Additionally, the marginalization of translation in bibliographic data is but one aspect of
invisibility, which can in turn reveal much about the different definitions given to
translation in
each source
[6] and the motivations of translational agents
in the field, be they domestication (à la Venuti) or repertoire broadening (according to the logic of polysystem
theory). Finally, DH demands that we document the practices (translation invisibility being one phenomenon) that
condition how we work with various data sources. This allows us to discuss the space translations occupy in the
literary field, and also how different agents (libraries, the press, publishers) interact with that space.
In this article, we present two case studies: the first is dedicated to translation invisibility in the literary
press (i.e., specialized and general literary journals and magazines) discussing overall trends in the Canadian
literary press and specific examples from the Quill & Quire and the Montreal Review of Books. The second deals with the institutional practices of collecting and
cataloguing translations according to metadata standards and challenges for extracting translation data from three
national libraries, the German National Library (DNB), the Austrian National Library (ÖNB), and the Bibliothèque et
Archives nationales du Québec (BAnQ). We discuss some DH-related challenges in finding and extracting translation
data from these sources and propose solutions for researchers looking to access and analyze bibliographic data for
translations. By doing so, we show how the cataloguing, collecting, and reviewing of translations can be viewed as
a systemic issue relating to translation invisibility, highlighting the parallels between these different types of
practices. In describing these different levels of translation data, we hope to provide pointers to DH and
translation researchers on how they can use invisibility to their advantage, and make this otherwise silent data
“speak.”
Case Study I: Translation Reviews in the Canadian Literary Press and Challenges for Large-scale Studies
Beyond “The Translator’s Invisibility”
This invisibility of translations has been explained in various ways — cultural, theoretical, and technical.
Venuti’s well-known
regime of fluency in English-language translations explores Anglophone cultural
preferences for so-called domestication, that is the tendency to erase traces of cultural and linguistic
difference in literary translations. Venuti’s findings have been echoed by other researchers, with studies on
translation reviews confirming, for instance, that “fluid and idiomatic texts are [still]
more likely to be accepted without resistance” [
Monti 2016,
my translation]. A more recent study of Goodreads user attitudes with regard to translation has shown that these
preferences are also present among average readers of English-language translations, who often use “a trope of loss, mostly linked particularly to stylistic or fluency loss [...]” [
Kotze et al 2021, 167] when reviewing translated texts.
These cultural norms do little to encourage literary reviews to properly cite translated books, which are deemed
successful if the process of their translation is unremarkable, in the most literal sense of the word. In the
English-speaking world, these preferences have been integrated into periodical editing practices. As early as
1982, translator and author Ronald Christ described how quick magazines were to cut critiques of the translation
process from literary reviews [
Christ 1982, 17]. Indeed, according to his exchanges with
various editors, the consensus seems to be that “[…] unless the translation is notably poor,
[…] it’s simply assumed that the competent translator has accomplished what translators are supposed to
accomplish […]” [James Atlas, cited by
Christ 1982]. Cecilia
Alvstad goes beyond editorial guidelines and explores how translation invisibility is baked into the packaging of
translated literature from the start. She has formulated the concept of a
translation pact to
explain the invisibility of translations at all levels of readership — from editors and literary critics to
readers:
[...] [T]here is [...] a pact-inviting mechanism at work in translations, a rhetorical construction through
which readers are invited to read translated texts as if they were original texts written solely by the original
author. [...] [T]his convention is rhetorically supported, even cultivated, by textual and paratextual features
of translated books [
Alvstad 2014, 271].
According to Alvstad, the invisibility of translations is a reading strategy editors and readers are
continuously invited to adopt by mutually agreed upon publishing standards
[7]. As such, we can see how the marginalization of translated literature in
periodicals and libraries is in fact a reflection of various overarching cultural norms regarding translation. It
remains to be seen, however, how and to what extent these norms are applied across various publications and in
various contexts. Keeping this in mind, we can begin to employ interpretative strategies to make this silence
speak, and draw out meaning from what may otherwise appear to be an absence of information.
Translation(s) in/and the Literary Press
The literary press — an expression used here to refer to any general or scholarly periodical publishing reviews
of books and short-form original or translated fiction — is not exempt from institutional and cultural trends
tending to render translations invisible. As noted above and by a number of translation researchers [
Venuti 1995] [
Fawcett 2000] [
Alvstad 2014], translations may go completely
unreviewed or uncommented, and translators are often not credited in review headers. Indeed, after 40 years at
the head of
Translation Review, Rainer Schulte continues to assert that “[t]he field of reviewing translations is still in its infancy” [
Schulte 2022, 3]. In addition to impacting readers’ perception of translated literature, the invisibility of
translations in these publications greatly affects researchers’ capacity to study reviewing practices in context.
Similarly to studies underpinned by library collections as we will see in the following section, existing studies
of translations in the literary press are often limited in scope
[8]: corpora sizes are either determined by the translations identified by periodical editors or
by researchers themselves, and longitudinal studies are difficult to execute. When dealing with translated
fiction in periodicals, researchers are thus faced with a plethora of challenges: (re)translations and
translators can go unmentioned; ephemeral publications and formats may not have been adequately preserved;
citation standards may change over time, etc. [
Roig-Sanz , Fólica, and Ikoff 2021, 201]. Historical studies
of periodicals aiming to identify and analyze translated texts in periodicals are thus hindered both
theoretically — due to the cultural marginalization of translation — and technically — due to imprecise
text-recognition and multilingual limitations of software [
Roig-Sanz , Fólica, and Ikoff 2021, 203–205] [
O’Connor 2019, 245–246].
A quick survey of various Canadian periodicals reveals an incredibly diverse array of approaches to translation
reviewing, all of which fall within the framework of invisibility. Among the 15 periodicals and two
catalogues
[9] surveyed in the context of this article,
none offer the possibility to filter by translator or source language, for instance. It is not uncommon, however,
for publications to have a separate section for translated literature:
Les
libraires, for example, has a subsection of its literary reviews dedicated to “littérature
étrangère” (foreign literature), while
Lettres québécoises and the
University of Toronto Quarterly both publish distinct articles dealing with recently
translated books. The children’s literature magazine
Lurelu, on the other hand, uses
the tag “T” to signal the presence of a translator among a work’s contributors, allowing readers to identify
translated children’s books at a glance. A number of periodicals sporadically include the translator’s name in
the review header, to varying degrees of exhaustivity. At one extreme, we have the
Montreal
Review of Books (
mRb), where, with the exception of children’s
literature
[10], all
translators are credited. At the other end, we have publications like
Books in
Canada, in which no translator’s name is guaranteed a spot in review headers, and
Prairie Books NOW, where books are systematically reviewed in their original language (French or
English). In the middle, we find most other periodicals (e.g.,
The Malahat Review,
The Fiddlehead,
Canadian Literature, and
Muskrat Magazine), where translation credit is attributed sporadically.
Of course, translator and translation credit is but one aspect of translation visibility in the literary press,
though peritextual information in periodicals can and has been used to evaluate translator and translation
visibility in the target publishing context (as in studies cited above). In terms of reviewing standards,
however, the greatest challenge facing researchers working with reviews of translated literature is how difficult
these sources are to identify on a mass scale. Most pre-existing catalogues of reviews, such as the
Canadian Book Review Annual, and digital periodical platforms (
Nuit
blanche,
https://nuitblanche.com/commentaire-lecture, (accessed April 22, 2024) being a good example) do not allow
one to filter by a translator’s name and fail to tag translations in any consistent way, thus making anything
except semi-manual extraction impossible. In many ways, these review repositories are structured in a similar way
to the online library catalogues that will be discussed in the next section. Such catalogues have been criticized
since their conception in the mid-90s, for being “[...] arranged on the assumption that
searchers arrive at the catalog knowing at least one of the three access points (author, title, or
subject)” [
Borgman 1996, 495]. Under these conditions, researchers seeking reviews of
translations must proceed via proxy: filtering for known translations, translated authors, or translators;
keyword searches for variations of the verb
to translate or the nouns
translation and
translator in different languages; or looking for mentions of foreign languages. In all cases,
exhaustive studies of these digital sources are impossible, and translations published by smaller presses,
translated by lesser-known translators, or from marginalized languages that have been more thoroughly rendered
invisible by the editing or review process are not likely to be uncovered by any of these methods.
We can thus see that the implications of translation invisibility in the literary press are multiple. In this
section, our particular focus will be on using reviewing practices in periodicals to broaden our understanding of
“invisibility” beyond the single axis of “translator invisibility.” While large corpora of peritextual
information in review headers can indeed act as a proxy for translator and translation visibility in the target
publishing context, we will also be looking at how qualitative analyses of individual reviews showcase the
reviewing and crediting practices that work to foreground or background translation in the literary press. As
Wakabayashi underlines, quantitative DH methods allow “[...] greater focus on the ‘mundane’
translations that constitute the bulk of translation history” [
Wakabayashi 2019, 134],
thereby identifying overarching institutional, cultural, and editorial trends from which a handful of exceptional
items emerge. Hence, mixed methods are useful in revealing different
degrees of invisibility, i.e.,
why and how translations are made (in)visible by certain agents in particular contexts.
Interpreting (In)visibility in Translation Reviewing: The Case of the Quill &
Quire and the Montreal Review of Books
In order to illustrate the difficulties and possibilities facing researchers working with translations in the
literary press, we will outline our experience curating datasets of translation reviews from two Canadian
literary periodicals, the Toronto-based Quill & Quire (Q&Q) and the Montreal-based Montreal Review of Books (mRb). As a result of these journals’ position in two distinct English-language literary
systems, Anglo-Canadian and Anglo-Québécois respectively, both their reviewing practices illustrate the
well-documented trend of translation invisibility yet showcase wholly different rapports with translated
literature. We found that, while translation invisibility remains relatively stable over time in the Q&Q, the space dedicated to translations in the mRb — a
purportedly “Québécois” publication — has increased over time.
The
Q&Q is a Canadian literary periodical founded in 1935 aimed at writers,
editors, and other professionals in the publishing industry. It is published in two formats, digitally since 2004
with an archive of reviews dating back to 1996 and physically (with 10 issues annually). It has a circulation of
5,000 copies per print issue, reviewing around 40 books every time. Notably, the periodical boasts “the most comprehensive look at Canadian-authored books in the country” [
Q & Q], making it a particularly interesting window for researchers studying this publishing
landscape. The
mRb, founded in 1997, is the official review of the Association of
English-language Publishers of Quebec. It is also published both digitally (with an archive of issues dating back
to 2000) and in print (thrice annually). Each print issue has a circulation of 45,000 copies and reviews 29 books
on average [
Montreal Review of Books 2022]. The publication is characterized by a geographical specificity,
focusing on books whose “author, publisher, illustrator, or translator [is] based in the
province of Quebec” [
Montreal Review of Books 2021], thus making it an ideal point from which to study the
intersection of French- and English-language writing in the province. The study we describe here was founded on
the digital version of the
Q&Q [11] and the digital archive of paper issues of the
mRb between 2000 and
2020
[12].
Due to differences in reviewing standards at both these publications, our corpus assembly varied from journal to
journal. While the
mRb meticulously includes the translator’s name below the
author’s in every review peritext, the translator is only sporadically included among the contributors in
Q&Q reviews. The relative sizes of the journals also played a significant role in study
design: on the one hand, with a total number of 1,700 reviews, the
mRb was well
suited to semi-manual corpus assembly; on the other, the 7,642 reviews published in the
Q&Q were automatically extracted using Web Scraper (
https://webscraper.io/, accessed April 22, 2024). As summarized in
Table 1,
using the presence of a translator in the review header as a proxy, this approach yielded two corpora: 255
translation reviews in the
mRb (15% of the total) and 127 translation reviews in the
Q&Q (1.6% of the total). Already, we see a large discrepancy in reviewing
practices, leading us to understand that
translation invisibility should be nuanced according to the
degree of literary contact taking place (here, between Canadian, Québécois and Anglo-Québécois literature).
Though it is impossible to know how many translations our scrape of the
Q&Q
missed without a manual verification, the disparity in reviewing translations is immediately apparent (see
Table 1): despite having nearly four and half times as many reviews as the
mRb, the
Q&Q seems to have reviewed (or at least
identified) only half as many translated books in the same twenty-year period. In this case, we see that the
regional specificity of the
mRb, which insists on Québec-published books regardless
of source language, leads to a greater consideration for translators and translations in the periodical’s
reviewing and crediting standards than in those of the pan-Canadian, predominantly Anglophone
Q&Q. Indeed, even if a greater number of translations was reviewed in the
Q&Q between 2000 and 2020, their invisibility in the periodical is nevertheless
revelatory when placed in relation to the credited translations in the
mRb.
|
Montreal Review of Books |
Quill & Quire |
| Total number of reviews |
1,700 |
7,642 |
| Number of translation reviews identified |
255 |
127 |
| Proportion of reviews on translated books |
15% |
1.6% |
Table 1.
Overview of translation reviews published in the
mRb and the
Q&Q between 2000 and 2020
While our research revealed key differences in the reviewing standards of two Anglophone journals based in the
same country, illustrating unique features of the Anglo-Canadian and Anglo-Québécois reviewing practices with
regard to translation, there are also many similarities. In-text mentions of translation and translators in
mRb and
Q&Q reviews are quantitatively quite
similar. For example, the median number of sentences (1) dedicated to the discussion of the translation in the
body of reviews is the same in both journals (
Figure 1). Between 2000 and 2020, in
the
Q&Q and the
mRb alike, only one sentence out of
each review is used to review the translator’s work or to comment on the quality of the translation process. A
quantitative picture of the reviews reveals that almost 40% of all reviews in both periodicals make no mention of
translation whatsoever:
As we see in
Figure 1, only a marginal number of reviews in the
mRb and
Q&Q take note of translation issues and comment on
them in length. The traditional paradigm of translation invisibility does not appear to have been challenged in
any meaningful way. The same impression persists on when we zoom in from a sentence- to a word-level analysis of
these translation reviews. For instance, the 25 most frequent words employed in reviews of translated books in
the two journals were near identical (
Table 2):
| Ranking |
Montreal Review of Books |
Quill & Quire |
| 1 |
book |
book |
| 2 |
novel |
novel |
| 3 |
life |
story |
| 4 |
story |
life |
| 5 |
world |
quebec |
| 6 |
quebec |
world |
| 7 |
time |
french |
| 8 |
french |
narrator |
| 9 |
english |
readers |
| 10 |
characters |
english |
| 11 |
own |
author |
| 12 |
mother |
translation |
| 13 |
love |
narrative |
| 14 |
narrator |
father |
| 15 |
father |
montreal |
| 16 |
people |
love |
| 17 |
montreal |
mother |
| 18 |
translation |
family |
| 19 |
family |
little |
| 20 |
reader |
reader |
| 21 |
stories |
language |
| 22 |
author |
time |
| 23 |
readers |
own |
| 24 |
narrative |
books |
| 25 |
little |
children |
Table 2.
Net frequencies of the 25 most common words in translation reviews in the
mRb
and the
Q&Q between 2000 and 2020
What is most striking about these two lists is their similarity in terms of both words present and ranking.
Translation remains a marginal question, with few words on these lists used to describe the process — we should
note the presence of
French, English (among the top 10 in both columns of
Table 2),
translation, and
language, but the absence of the
word
translator[13] as well as any evaluative terms
relating to this agent’s work. At first view, it does indeed appear as though both these periodicals treat
translated literature nearly identically.
Table 2 plausibly suggests that the
mRb and the
Q&Q have adopted similar postures, both
tending to marginalize translated literature in book reviews.
Yet, what our synchronic, distant reading of these reviews and their peritextual information in the respective
periodicals has not revealed are the micro-trends that demonstrate the many ways in which translation
invisibility evolved between 2000 and 2020 and how it has been leveraged by editors to suit other cultural or
literary agendas. In order to interpret these relatively “silent” corpora of translation reviews and their
peritexts, we must pair our previous DH analysis with a diachronic, close reading of the data revealed by these
preliminary quantitative analyses. A closer analysis of translation reviews in the
Q&Q, for instance, revealed a series of outliers that showcase various editorial strategies that
have contributed to increasing the visibility of translations
[14].
We see, for instance, that the presence of the translator’s name on the cover, a translator’s note, or a glossary
all increase the chances of a thorough translation review [
Wells 2009] [
Whiteman 2014]. This is the case for works such as
One, written by Serge Thibodeau and
translated by Jo-Ann Elder, which features the translator’s name and input prominently. The reviewer, Zachariah
Wells, dedicated over three quarters (77%) of the review’s sentences to translation commentary and distinguishes
between the original (
Seul on est) and the translation, which he calls “
Elder’s One” [
Wells 2009, ¶4]. In
another notable case, half of the body of the review of
Sanaaq by Mitiarjuk
Nappaaluk, translated from Inuktitut into French by Bernard Saladin d’Anglure and from French into English by
Peter Frost, is used to discuss translation. While the review is not positive — “the constant
pain to which an English reader is put to check the glossary for untranslated Inuktitut words becomes
tiresome” [
Whiteman 2014, ¶3] — it quickly becomes clear that its author’s Inuit
background is of great interest when it comes to translation. Reviewer Bruce Whiteman concludes that
Sanaaq is “an important cultural and literary document” (
2014, ¶3) that can now be read by English-speaking readers.
Similar trends characterize translation reviews in the
mRb. Not only did we find an
evolution in the types of translation commentary over time, with an increasing number of reviews interested in
translator agency and source-culture representation [
Webster 2016] [
Miller 2019] [
Garlick 2020], but a high number of reviews in this periodical are also written by fellow
translators
[15]. For example, while early
reviews in the
mRb tended to focus on how “[e]ach language has a
unique syntactic style that defies perfect translation” [
Smith 2003, ¶7], later reviews
praised the “creative” choices made by certain translators — “[Oana Avasilichioaei’s]
creative use of the pronouns
s/he,
hir,
hirself,
e,
em, and
eir when representing Tiresias while in a state of flux is especially
inspired” [
Garlick 2020, ¶4]. Additionally, certain reviews of canonical Québécois
texts by figures like Dany Laferrière [
Bourgeois 2009] and Kim Thúy [
Moser 2014]
conduct interviews with the authors in English and strategically avoid identifying these works as translations.
These choices contribute to the geographical specificity of the Anglo-Québécois literary repertoire represented
in the
mRb and illustrating how translation invisibility can be instrumentalized in
certain target culture contexts
[16].
As we can see, though predominant reviewing standards tending to invisibilize translations in the literary press
apply at both the mRb and the Q&Q, interpretative
strategies abound and allow us to draw conclusions that go beyond an unfaceted translation invisibility
framework. The examples above illustrate the importance of mixed methods for these readings: starting with
classic DH synchronic distant readings, which tend to flatten differences between our sources and make
invisibility stand out, and turning next toward diachronic, context-informed close readings of the results
generated. As demonstrated in the case of the Q&Q and the mRb, while distant reading methods provide us with a general context for a larger corpus of translations
and their reviews, close readings reveal evolutions in predominant conceptions and expectations of translated
literature as well as certain strategic manipulations of literary repertoires by translators, editors, and
reviewers alike. As we will see in library collections and catalogues, the invisibility of translations in the
literary press is incredibly multifaceted and nuanced, demonstrating the contribution of large-scale corpus
studies of these new sources of information. These newly available corpora of texts can now be studied on a great
enough scale to make their apparent silence speak volumes, revealing patterns that could not be registered
through older, traditionally text-focused methods in translation studies.
Case Study II: Institutional Practices of Cataloguing and Collecting Translations in the DNB, ONB, and
BAnQ
Cataloguing Translations and the Library as a Living Archive
Each catalog record is the product of a complex yet hidden negotiation between a
cataloguer and the constraints of library systems and practices. [Belantara and Drabinski 2022, 1]
As Belantara and Bradinski point out in their 2022 ethnographic study of cataloguers at work, library
cataloguing is still a black box, and practices can sometimes be revealed only by close collaboration with the
librarians who create this metadata
[17]. For example, when approaching the DNB’s digital services (
Abteilung
Digitale Dienste der Deutschen Nationalbibliothek) for curating a dataset of German fiction in
translation [
Teichmann 2022], we noted that it was possible to query the catalogue and filter the
collection for translations using the language field contained in the metadata. What was less obvious, and what
DNB librarians confirmed, is that the language field had only been in use for items catalogued since 1996,
meaning that the metadata from before that date was still being updated. This shift highlights the fact that
translation invisibility is strongly tied to cataloguing and collection practices
[18], not mention that metadata standards that need to be contextualized and documented
over time
[19]. We can think of the library as a living archive, where entries and
their information are added and redacted on a running basis. Hence, it can be challenging to unravel on what
basis translations are catalogued, how they are catalogued, and in what ways they can be extracted using a
replicable method. This, in turn, results in the sparsity and rare utilization of library metadata for curating a
translation dataset.
As evoked in the introduction, translation datasets remain sparse in and beyond DH. Additionally, due to the
lack of a formalized method with respect to cataloguing practices and standards, it remains difficult to access
and extract bibliographic data on translations from national collections. Diana Roig-Sanz and Laura Folica (
2021, 242) stress that libraries as sources for metadata remain
largely unexploited, while scholars like Susan Pickford have repeatedly insisted on how incomplete existing
databases such as the
Index Translationum or VIAF are for bibliographic translation
data [
Pickford 2016]
[20]. Bibliographic data
[21] contain information on the author,
publisher, language, etc. of a given edition and are typically collected and maintained by libraries [
Umerle et al 2022, 12]
[22] according to strict metadata standards such as MARC (Machine-Readable Cataloguing
record),
[23] Dublin
Core, or the Library of Congress Classification. Translations bring with them specific characteristics to
bibliographic data, one of them being that language has a rather high importance, and an imposed relationship to
an original edition (which may or may not be documented). Additional creators of translated editions, such as
translators, original publishers, etc., also need to be contained in the bibliographic data. All this information
indicates to the user of the library catalogue whether the edition is a translation or not, a fact which is not
always apparent and poses specific challenges for the extraction of bibliographic data. An additional issue is
that translation-specific information may be in the metadata but not included in the online catalogue, which
further marginalizes translations. Utilizing the library’s bibliographic translation data therefore requires that
the data be available, accessible, and that cataloguing practices make it possible to extract them.
Unfortunately, as we saw in the previous section and continue to illustrate below, this can be very challenging:
the invisibility of translations in library catalogues results in a sparsity of translation data, which
oftentimes prompts scholars to curate a dataset semi-manually [
Roman 2022] [
Norrick-Rühl and Bold 2016] [
Zhou and Sun 2017] [
Pickford 2016]. Projects that
make use of bibliographic translation data are therefore mainly case-study specific and limited to the
translations of a single author, such as the
Jane Eyre project by Reynolds and
Vitali (
2021); a single genre; a single source or target language, such as
the project Intra-Belgian literary translations since 1970 [
BELTRANS].
[24] While these studies do use bibliographic data and sometimes draw on library collections for
their datasets, they also all highlight the necessity for semi-manual curation due to the difficulties in
identifying translations in the respective library catalogues, extracting these records, and the limitations in
applying these methods to other sources of data
[25].
An important issue with former, case-study specific research is that manual data curation practises do not allow
for the (re)use of formalized operations that can be replicated, both in terms of data extraction and
quantitative analyses that can be generalized across different datasets. As we show in this section, extracting
bibliographic translation data from different libraries (since researchers often work with more than one source:
for Germanophone literature, we have the Swiss, German, and Austrian national libraries besides the German, while
for Québécois Francophone literature, we must work with Québec and the French library collections) poses
challenges and highlights the limitations and possibilities of harvesting these data with a single formalized
method. The aim of presenting this case study hence is to describe cataloguing and collection practices as well
as metadata standards for translations to develop a replicable workflow for their extraction so that researchers
can use the (in)visibility of translations in various national collections to their advantage in curating and
analyzing bibliographic translation datasets.
Identifying Translation in Online Library Catalogues
The information that indicates whether a given edition is in fact a translation is not always in the same place
in the online library catalogues, and it can be difficult to differentiate a translation from an original
edition. The main challenge here is that, when it comes to a library collection or online catalogue, a
translation is treated as another edition of a publication. Translations thus do not form a distinct category, as
do genres or topics. Additionally, in most collections, it is not possible to trace a translation back to its
original
[26]. The information on languages and translators is also not contained in the same fields across
library catalogues. This is one of the central challenges in identifying and extracting bibliographic data on
translations in national libraries. We hence need to ask: how can we discern translations from other catalogue
entries, and can we formulate a rule that allows us to identify and extract translations across different library
collections? In this section, we exemplify differences in cataloguing practices by looking at three national
library online catalogues — the BAnQ, the ÖNB, and the DNB — explore the challenges they present, and propose
solutions for extracting bibliographic translation data.
Let us begin by looking at a couple of examples of translations in these three online library catalogues as
presented to any user searching for a translation. What indicates that this is a translation and where can this
information be found? We will be using Patrick Süskind’s bestselling novel Das
Parfum, which has been translated into numerous languages, as an example.
When looking up the English translation of Süskind’s
Das Parfum in the DNB online
catalogue, we can immediately see the fields indicating the edition’s language in addition to the original
language. As
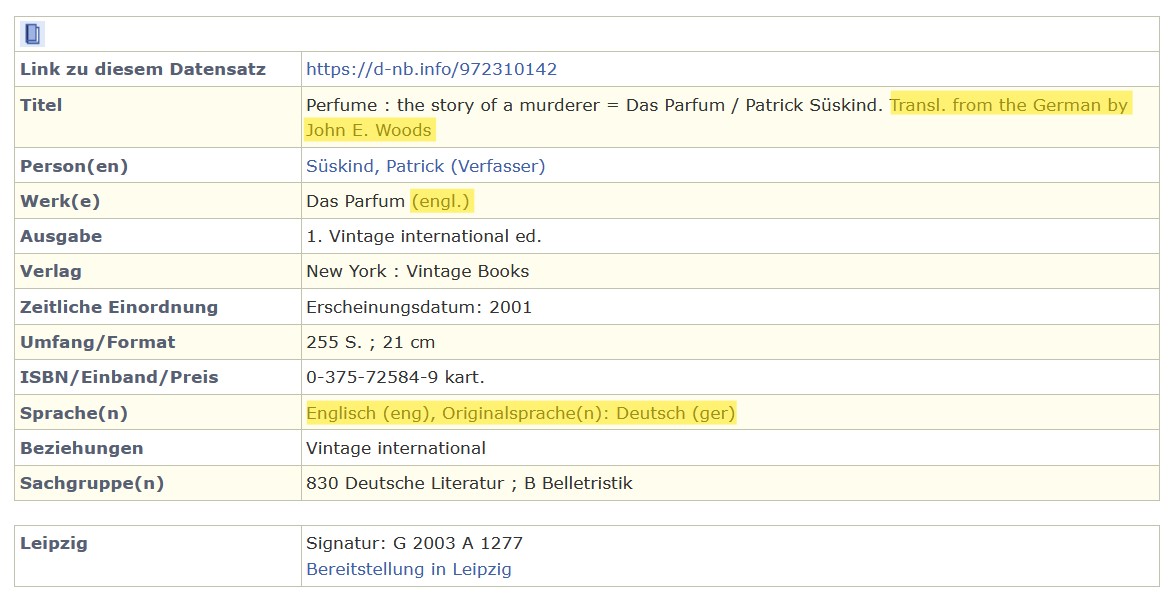
Figure 2 shows, besides the translator in the “Titel” (title)
field and the original title in the “Werk(e)” (works) field, the DNB online catalogue has a “Sprache”
(language) field that includes the original language (an excellent indicator for our definition of translation).
This mandatory field is really simple to work with, since we may easily formulate a rule for it — a translation
is any edition that has an “Originalsprache(n),” (original languages), next to the language of the edition.
The language field in the DNB follows ISO conventions for languages and is therefore consistent across all
entries, with a standardized format. Thus, even though a separate field or category for translation does not
exist in the online catalogue, as is the case for the BAnQ, it is possible to distinguish a translation by the
language field. For comparison, let us look at the BAnQ and ONB and see if they also keep a language field, to
which we could theoretically apply the same rule for identifying translations.
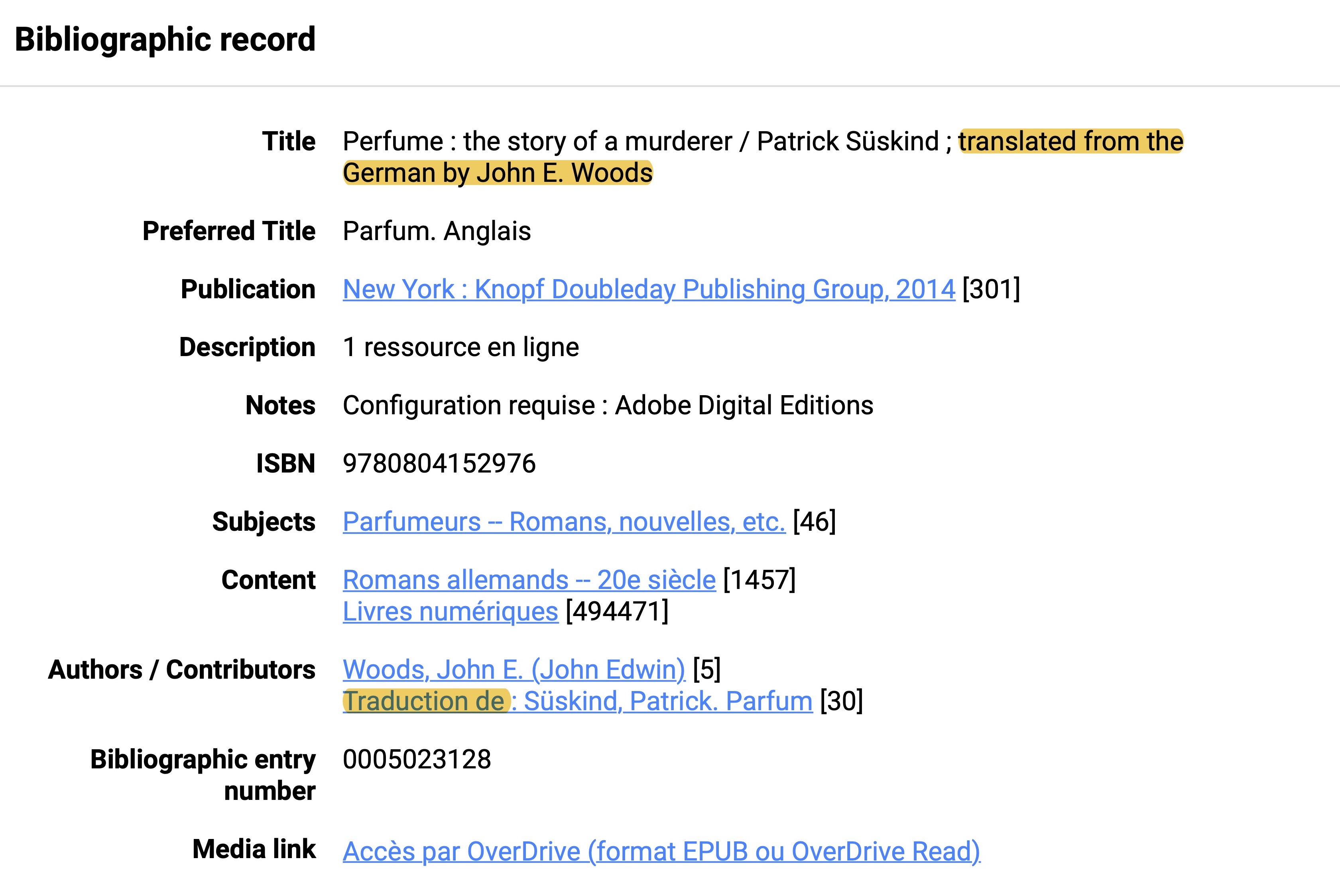
When searching the BAnQ’s online catalogue for Süskind’s
Perfume, there are
indications that we are dealing with a translated work in the “Title” field, which contains the translator’s
name, and in the “Preferred Title” field, which contains the edition’s language but not the original
language. Besides the indicator “translated by,” there is no separate category that distinguishes this
edition as a translation from an original edition. Additionally, the “Content” field contains the
categorical descriptor “Romans allemands – 20e siècle” (German novels – 20th century), which stresses the
importance of categorizing editions according to their national literature in the BAnQ. This can also be an
indicator of translation, albeit on an implied basis. It is important to note that there is no other field in the
online catalogue containing the original language or title, which, as the next example shows, is also the case
for the ÖNB
[27].
Unlike the DNB but similarly to the BAnQ, the ÖNB online catalogue does not have a field for a work’s original
language in its online catalogue. Some indicators that this edition is a translation can be found in the field
“Weitere Beteiligte” (additional participants), which includes the “ÜbersetzerIn” (translator), and the
field “Verantwort.angabe,” (responsible entity), which includes the note “Trad. de” (translated by).
Again, there is no separate field for translation as its own category. If we wanted to identify all translations
of Kafka, we would have to look for any edition that either has a translator in the “Weitere Beteiligte”
field or search for all the different variations of the phrase “Trad. de” in each language — for English we
had “Trans.” or “translated from” in the examples above. In either case, formulating a rule based on
these fields is challenging and has a larger error margin due to the numerous variations. Going by language
field, as for the DNB online catalogue, seems much more feasible.
What these examples of translations in various online catalogues — all revelatory of the general trend to
invisibilize translations — illustrate are the plethora of cataloguing practices at work in each library
[28]. How, then, can we utilize the metadata and especially the language fields to propose a solution for
identifying translations in these different libraries despite their overall invisibility in these catalogues?
Extracting Translations from Libraries: A Replicable Method Using the Language Fields in MARC Records
For a formalized, replicable method of extraction of translation metadata from library collections, we may
formulate a “rule” based on the language field, according to a linguistic definition of translation —
presuming that the translated edition has a different original language than the current
edition
[29]. To
extract translations from the DNB, we can write a query that finds any edition with both an original and other
language listed. In the catalogue, this appears as “Originalsprache(n),” which is included only for
translations, while “Sprache” is used to indicate the given edition’s language
[30]. A search for the original language (“spo”) in the DNB, “spo=ger”
[31], for instance, yields all titles that originally appeared in German. We can
hence apply this rule with high confidence that it will yield only translations
[32]. The question
remains if the same rule can be applied to the other library catalogues, such as the ÖNB and the BAnQ, even in
the absence of an original language field in their online catalogues.
Metadata standards are a precondition for applying this (and other) rule(s) across catalogues and extracting
large quantities of bibliographic translation data for analysis. The catalogues in question hence need to contain
a language field. In the online catalogues, this field is only visible for the DNB, but not for the ÖNB and BAnQ.
However, since all these catalogues follow the same standards for bibliographic metadata in a fixed MARC or MARC
21 format, we can therefore utilize the MARC 21 fields and operationalize the search query to extract
translations. How do the fields containing the original language (which are specific to DNB and do not appear in
BAnQ or ÖNB catalogues) translate to MARC 21 as a standard format? Let us have a look at our Süskind translation,
extracted in MARC 21 from the DNB:
<record xmlns="http://www.loc.gov/MARC21/slim" type="Bibliographic">
<leader>00000nam a2200000 c 4500</leader>
<controlfield tag="001">972310142</controlfield>
<controlfield tag="003">DE-101</controlfield>
<controlfield tag="005">20171203165742.0</controlfield>
<controlfield tag="007">tu</controlfield>
<controlfield tag="008">040924s2001 xxu||||| |||| 00||||eng </controlfield>
<datafield tag="015" ind1=" " ind2=" ">
<subfield code="a">04,A44,1706</subfield>
<subfield code="2">dnb</subfield>
</datafield>
<datafield tag="016" ind1="7" ind2=" ">
<subfield code="2">DE-101</subfield>
<subfield code="a">972310142</subfield>
</datafield>
<datafield tag="020" ind1=" " ind2=" ">
<subfield code="a">0375725849</subfield>
<subfield code="c">kart.</subfield>
<subfield code="9">0-375-72584-9</subfield>
</datafield>
<datafield tag="035" ind1=" " ind2=" ">
<subfield code="a">(DE-599)DNB972310142</subfield>
</datafield>
<datafield tag="035" ind1=" " ind2=" ">
<subfield code="a">(OCoLC)76513721</subfield>
</datafield>
<datafield tag="040" ind1=" " ind2=" ">
<subfield code="a">1140</subfield>
<subfield code="b">ger</subfield>
<subfield code="c">DE-101</subfield>
<subfield code="d">9999</subfield>
</datafield>
<datafield tag="041" ind1=" " ind2=" ">
<subfield code="a">eng</subfield>
<subfield code="h">ger</subfield>
</datafield>
...
</record>
Example 1.
MARC 21 record of the English translation of Patrick Süskind’s
Das Parfum from
the DNB,
https://d-nb.info/972310142, accessed September 28,
2023. In this example, line 7 and lines 27–36 are highlighted
There are several mandatory fields in MARC 21 for language.
Controlfield 008, for
instance, contains the language of the edition (the record in
Figure 2 contains
"eng" in the language field). Additionally, we have three more fields that contain
information on the languages:
- field 040 subfield b Cataloguing Source / Language of
Cataloguing
- field 041 Language Code
- field 041 subfield h Original Language[Library of Congress (b)]
For the Süskind record above,
field 041 contains
"eng" or the language of the edition, while
field 041 subfield h, more
importantly, contains the original language (
"ger"). This is the field that has been
made visible in the online catalogue of the DNB. Hence, using the information in MARC 21
field 041 subfield h, we could apply our rule and query the catalogue for any entries that have German
(
"ger") as an original language under the assumption that these are translations.
Indeed, according to OCLC standards,
field 041 subfield h is required (if
applicable) and hence should include original language of a translation [
OCLC]
[33].
Additionally, there is the option to add information on whether the edition is a translation as a first indicator
(see the value of
ind1 for
field 041). If this
translation indication is set to
ind1="1" then, according to OCLC standards, “the work is or includes a translation and is used regardless of whether the work in the original
language has been published” [
OCLC]. As we can see in
Example
1, however, the first indicator for
field 041 is left blank, which suggests
that the indicator (which categorizes the edition as a translation) is not consistently used in some libraries’
metadata.
Nevertheless, even without the first indicator, the information on original and edition language in the
field 041 (language) is a consistent and reliable source of information to identify and
extract the editions that are translations. Since
field 041 is required according
to OCLC standards and according to the ÖNB’s documentation, these (sub)fields’ metadata should be
included
[34].
We can now test whether our filter based on language can be applied to other library collections for identifying
translations. Let us retrieve the MARC file for the French Kafka translation in the ÖNB catalogue we mentioned
above
[35]:
<datafield ind1=" " ind2=" " tag="040">
<subfield code="a">ONB</subfield>
<subfield code="b">ger</subfield>
<subfield code="d">ONB</subfield>
<subfield code="e">rakwb</subfield>
</datafield>
<datafield ind1=" " ind2=" " tag="041">
<subfield code="a">fre</subfield>
<subfield code="h">ger</subfield>
</datafield>
<datafield ind1=" " ind2=" " tag="044">
<subfield code="c">XA-FR</subfield>
</datafield>
<datafield ind1="1" ind2=" " tag="100">
<subfield code="a">Kafka, Franz</subfield>
<subfield code="d">1883-1924</subfield>
<subfield code="0">(DE-588)118559230</subfield>
<subfield code="4">aut</subfield>
</datafield>
<datafield ind1="1" ind2="0" tag="240">
<subfield code="a"><<Die>> Verwandlung</subfield>
<subfield code="l">franz.</subfield>
</datafield>
<datafield ind1="1" ind2="0" tag="245">
<subfield code="a"><<La>> métamorphose</subfield>
<subfield code="c">Franz Kafka. Lecture accompagnée par Dorian Astor. Trad. de Claude David</subfield>
</datafield>
<datafield ind1=" " ind2="1" tag="264">
<subfield code="a">Paris</subfield>
<subfield code="b">Gallimard</subfield>
<subfield code="c">2004</subfield>
</datafield>
<datafield ind1=" " ind2=" " tag="300">
<subfield code="a">173 S.</subfield>
<subfield code="b">Ill.</subfield>
</datafield>
As we can see in
Example 2, the ÖNB uses
field 041
and
subfield h for translation, but not the first indicator. Again, this confirms that
our rule based on original language to extract translations can be applied not only to the DNB, but also the ÖNB,
despite apparent differences in their visible online catalogues. This formalized method can thus be used across
different libraries to filter translations, offering a solution to the invisibility and inconsistency challenges
researchers face. However, the practice of including only the information from the bibliographic data on original
language and not the first indicator that would categorize the edition as a translation (even though it is so
valuable and important for translation researchers) highlights the marginal status of translations in our
cultural institutions, a fact even more apparent in collection practices.
Availability and Accessibility of Library Translation Data
Now that we have established that we can utilize the metadata standards and the language fields to identify
translations, we also need to establish whether and to what extent libraries even collect translations. As the
astute reader will have noticed, the last example for cataloguing practices mentioned above is not Süskind’s
Perfume, but Franz Kafka’s
La métamorphose. Indeed, the
ÖNB’s catalogue does not contain any translations by Süskind, because the library does not collect them in the
first place
[36].
When approaching a library to obtain bibliographic data, we oftentimes need to contact the responsible librarians
and ask not only whether they collect translation data but when and how much. As the ÖNB catalogue illustrates,
not all libraries collect translations to the same extent and in the same manner. When we contacted the ÖNB to
ask whether they collect translations, they confirmed that they only do so to a very limited extent
[37]. Indeed, in addition to cataloguing practices, collection practices condition the
(in)visibility of translations. This brings us to our second challenge: just as the representation of the
bibliographic data varies for each catalogue, so too do data availability and accessibility. Collection practices
— the rate, amount, and type of publications that are collected by national libraries — are by no means
standardized, a problem that also affects data availability
[38]. Not all national libraries collect translations or editions published outside of their
national boundaries, due to budget and resource constraints, for instance. Depending on a national library’s
priorities, users, resources, and staff, translations may or may not be collected. Coming back to Belantara and
Bradinski, when working on bibliographic data we need to remind ourselves that “[m]etadata
reflects a compromise between what the cataloguer knows about an item and the existing system into which she is
bound to embed it” [
Belantara and Drabinski 2022, 4]. Hence, whether and how translations are
catalogued and collected is not only due to the cataloguers at work, but also the institutional policies,
standards, and practices. This subsection is thus dedicated to the collection practices in the institutional
system and the resulting availability and accessibility of bibliographic translation data.
From the examples of the online catalogues above, we can get a sense of which national libraries collect
translations and which do not, or more precisely which authors they collect — the ÖNB did not have translations
of Süskind, but of Kafka. While this may be conditioned by a library’s target readerbase, it comes down to the
library’s collection policy. The DNB, for instance, has a legal deposit regulation (Pflichtablieferungsverordnung
or PflAV) that includes translations. It therefore collects “all publications issued in
Germany, irrespective of their language,” and “m
edia works published abroad for which
a publisher or a person who has a legal domicile, business premises or their
principal residence in Germany has
sold (licensed) the right to publish the work abroad”[
DNB (f)] (emphasis ours) need to be
deposited at the DNB. The latter specifically includes translations published outside of Germany.
[39]In comparison, the ÖNB’s deposit regulation is applicable to works published in or relevant to Austria
(Auslandsaustriaca) [
ÖNB (c)]
[40], which explains why the translation of Süskind’s Perfume is missing from their online catalogue. While
the DNB and ÖNB’s deposit regulations are geographically defined,
[41] the
BAnQ predominantly collects works in French and, on occasion, in English published outside of Québec
[42]. However,
which authors’ translations are collected may depend on many factors, including readership. Again, translations
do not explicitly appear in any of the lists of works collected, which underlines their invisibility and the
challenges in establishing whether a library collects translations published outside of their official languages
or geographic borders. A collection policy or deposit regulation that explicitly reaches beyond the linguistic
and geographic borders is a good indicator of whether a library collects translations.
Finally, data accessibility may vary for each library and lead to severe usage restrictions. Not all libraries
give free access to their data. For instance, even though MARC 21 is also a metadata standard in Canadian
libraries [
MARC], the Library and Archives of Canada's online catalogue only provide access to
MARC records for their employees
[43]. Similarly, the BAnQ does not provide any access to its MARC records, and information
on how to access these data is difficult to find. These differences between the Germanophone national libraries
and the Canadian libraries highlight the last major challenge we will discuss in this section for extracting
bibliographic translation data from libraries arising from institutional practices: data accessibility. As
Table 3 illustrates, access to data ranges from accessible and extractable in various
formats (DNB) to limited access (BAnQ):
|
DNB[44] |
ONB |
BAnQ |
| Accessibility |
Open access |
Open access |
Not open access |
Data extraction
(via the online catalogue) |
Extraction in batches in MARC, CSV, PDF formats |
Individually in Excel, RIS, and other formats |
Individually in Excel, RIS, and other formats |
| License |
CC0 1.0 Universal (CC0 1.0)
Public Domain Dedication |
CC0 1.0 Universal (CC0 1.0)
Public Domain Dedication |
Closed license, no sharing, no data publication |
Table 3.
Comparison of data use licenses, extraction tools, and accessibility to data for the DNB, ÖNB, and BAnQ
online catalogues.
Compared to the ÖNB and BAnQ, the DNB gives the most access to its bibliographic data, allowing users to freely
extract the data directly from the online catalogue in large batches and various formats, and to re-publish their
data under a universal license. Their Datenshop online portal allows registered users to query the online
catalogue by original language, for instance, and to save their selection and extract it. This makes
bibliographic data from the DNB accessible and easy to find, extract, and publish. For comparison, the ÖNB does
not have any such option, and records can only be individually, manually selected and extracted from the online
catalogue. For extraction in batches with specific search queries, the ÖNB offers an SRU (Search/Retrieve via
URL) and an OAI-PMH (Open Archives Initiative Protocol) service for extracting data in MARCXML (MARC data in an
XML environment). Additionally, a Gitlab repository
[45] needs to be consulted for the
respective Python scripts, which adds an additional hurdle to data accessibility for user groups who may not have
Python coding skills
[46].The ÖNB has the same license as the DNB for their
metadata, a Creative Commons Zero (CC0, “No rights reserved”)[
ÖNB (b)].
The BAnQ is the least accessible in terms of their bibliographic data. While they do supply some summary
statistics on the BAnQ’s new acquisitions, full bibliographic records can only be obtained on a case-by-case
basis by communicating directly with the institution. As preliminary data exploration of their collections has
shown [
Brissette, Vallières, and Teichmann 2023], the sharing of data for publication is not allowed. Comparing the DNB
and ÖNB to the BAnQ clearly highlights the differences in availability and accessibility as well as the
difficulties researchers face when trying to establish whether translation data is available to them and whether
they can freely use and publish them.
Next Steps: Toward a Snapshot Repository Documenting Collection Practices
Coming back to our initial argument, collection and cataloguing practices give a good indication of the status of
translations in the respective institutions and their practices as well as their agency in rendering this
information accessible and available to the public. An open data policy, a legal deposit regulation that extends
beyond linguistic and geographic boundaries, as well as close collaboration with the libraries are conditional for
working with bibliographic translation data.
One of the next steps toward a big translation history is to make visible not only translations but also the
libraries’ respective collection practices. In this section we therefore propose a replicable workflow — using the
query by original language in MARC records — that allows us to extract data at different points in time to build a
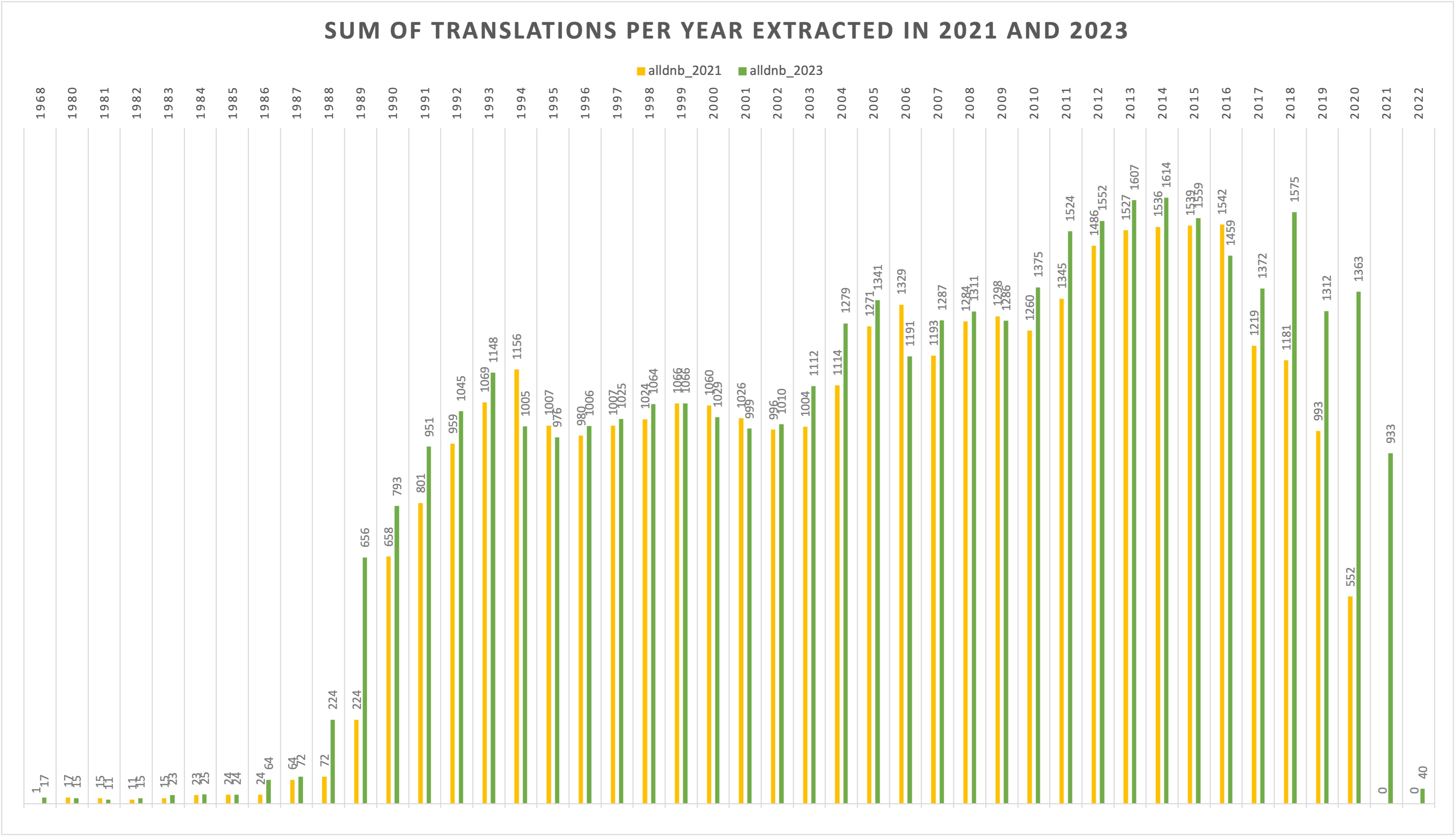
snapshot repository of the catalogue. Preliminary work [
Teichmann 2022, 62–63] on extracting
translations of German fiction in 2021 and 2023 from the German National Library has highlighted that titles are
retroactively being added for previous years, especially between 1980 and 1990 (see
Figure
5):
Re-extracting the data with the same query at a later point in time allows us to observe how, when, and to what
extent translations are collected over time. Additionally, it would be of value to operationalize and test the rule
for extraction by original language on different catalogues and to compare the catalogued translations by looking
at where they overlap or differ. In this way, the underlying institutional practices that contribute to the
invisibility of translations can be made visible.
Making translations across library catalogues (as well as cataloguing and collection practices, accessibility, and
availability) visible and developing tools and datasets for doing so is thus a crucial endeavour to open up these
rich resources and build the infrastructure for future studies in quantitative translation research. In alignment
with the main research focus of critical archival studies, one may ask what role libraries play in the
dissemination and collection of translations, what status translations have in a given literary culture, the
international canonization of national canons, and most importantly the institutional practices that contribute to
translation (in)visibility.
Conclusion
As demonstrated in the documented case studies of Germanophone and Francophone national library collections and
the Canadian literary press, translation invisibility is just as present in institutional and cultural standards as
in the textual features of many translations and their paratexts. Indeed, our survey of the Canadian literary press
as well as the German, Austrian, and Québécois national libraries’ cataloguing and collecting standards has
revealed a tendency to marginalize translations. In library catalogues, “translation” is not its own category,
translators and original editions are not consistently identified across languages, while some institutions forgo
the collection of translated material altogether. What is more, these trends persist despite the presence of
translation-specific and language fields in the metadata underlying library records. Similarly, reviewing standards
in the Canadian literary press — specifically literary journals publishing reviews of translated literature — often
do not account for the specific bibliographic information required to identify translations in the header and body
of reviews. As a result, researchers face many challenges when assembling corpora of bibliographic data pertaining
to translations drawn from these resources, mainly due to difficulties in identifying which books are translations
in the first place.
Despite the prevalence of what we have called
translation invisibility in library catalogues and
collections as well as in the literary press, we propose a number of solutions for data extraction and
interpretation that future researchers can employ to overcome and use this invisibility to their advantage. In
particular, we suggest that researchers rely on the predominantly linguistic definition of translation in use by
libraries and utilize the language fields contained in MARC records to retrieve translations from library
catalogues with a high degree of precision
[47]. We also
encourage translation researchers to collaborate with librarians to understand and document collection practices
over time. Additionally, bibliographic data should be extracted at various points in time in order to illustrate
translation collection and cataloguing practices at different points throughout the duration of the research. When
dealing with the literary press, we urge researchers to employ mixed methods, creating large datasets to
quantitatively showcase translation (in)visibility within given publications on a large scale and at many levels,
but following up with close readings of reviews themselves, which tend to nuance these preliminary impressions.
Such qualitative analyses reveal the context-specific agents and motivations behind predominant trends that make
translations invisible, which vary widely as we have seen.
Additionally, factors such as publishing standards, a Eurocentric market, and illegitimate translations also
result in translation marginalization outside the institutional and cultural trends we have discussed. Market
reports such as the
Literature Across Frontiers are mainly available for the European
and North American markets, where copyright is more readily enforced. They thus do not account for the countless
unauthorized translations in circulation — these included pirated books, fan-translated media, and illegal
translations of censored content [
Dwyer 2011] [
Karaganis 2011] [
Nkiko 2014]. Finally, the institutional standards of the literary press and national libraries are intimately enmeshed with
those enforced by the publishing industry and (inter)national copyright policies. The challenges we discuss here
are but one element of a larger network of cultural attitudes that affect the accessibility and availability of
translation data and therefore the diversity of DH research on translation.
Overall, we wish to sensitize digital humanists and translation scholars alike to the multiple facets of
translation invisibility at work in quantitative and data-based studies of translated sources. While the apparent
textual invisibility of the translator has been well documented in translation studies, the relatively recent
accessibility of bibliographic data has not yet led to many reflections on the data-related aspects of translation
invisibility. We hope that the challenges, solutions, and interpretative strategies proposed in this article will
be of use to future researchers harnessing these data sources. Additionally, we hope the multidisciplinary nature
of DH will increase the visibility of translations in other fields — including literature, information science, and
archival studies — leading scholars to consider these institutional and cultural aspects of translation
cataloguing, collection, and reviewing practices and to import them into their respective disciplines.
Notes
[4] In general,
quantitative translation research is more so situated in the bibliographic data sciences, information and library
sciences, archival studies, cultural analytics, and, of course, translation studies, for which the number of
projects using quantitative methodologies and bibliographic data increase each year. In the last five years, a
number of titles on the topic have been published: Advances in Empirical Translation
Studies [Ji and Oakes 2019]; Complexity Thinking in Translation
Studies [Marais and Reine 2019]; Advances in Corpus Applications in Literary
and Translation Studies [Li and Moratto 2022]; to name but three, not to mention the various
articles on the topic. At the 2023 annual conference of the Canadian Association for Translation Studies, out of 60
contributions, at most five or six (including those by authors of this paper) presented quantitatively driven
research projects. Questions pertaining to bibliographic translation data are, however, absent from the vast
majority of these studies. [5] Partially because the data needs to be requested from publishers
directly by conducting surveys (as in the case of the association of the German book trade).
[6] In this article, we use a primarily linguistic definition of translation. As such, a
translation is a publication that has a translator, an original edition in another language, and is
attributed to an author distinct from the translator (with the exception of clearly identified cases of
self-translation). Many other definitions of translation are possible, often depending on the source from which the
data is extracted. We encourage researchers in quantitative translation studies to consider these various
definitions when structuring their datasets and describing their sources, as in Poupaud et al. (2009, 268–269). [7] This might explain why
translators continue to fight for name attribution of book covers, despite being legally extended this right in
Canada, as mentioned above [ATTLC/LTAC, 5] [Whitfield 2006, 9–11,19] [Stewart 2021]. [9] A complete list of periodicals includes Nuit blanche, Les libraires, University of Toronto Quarterly, Lettres québécoises, Lurelu, The
Antigonish Review, Canadian Literature, The Malahat
Review, The Fiddlehead, Prairie Fire, Muskrat Magazine, Quill & Quire, Prairie Books NOW, Montreal Review of Books, Books in
Canada, while the two repositories of literary reviews were the Canadian Book Review
Annual and Kwahiatonhk!.
[10] It is worth mentioning that, as of the mRb’s 25th anniversary
edition in 2023 and following communication with the authors of this article within the context of a previous
study, translators of children’s literature are also credited on the pages of this publication.
[13] While this article deals primarily with so-called translation invisibility, it
is important to note that many other figures involved in book publishing have also been marginalized to various
degrees — editors, literary agents, and cover artists, for instance — and are equally absent from these reviews
and lie beyond the scope of our analysis. For a discussion of editorial invisibility, for instance, see [Taivalkoski-Shilov 2013] [Glinoer and Lefort-Favreau 2019]. [14] The results of this analysis of Q&Q reviews were first presented at the CATS 35th annual congress in May 2023.
[15] For a close reading and analysis of translation reviews published in the mRb between 2000 and 2020 [Roman 2022, 47–67]. [16] For the reverse trend, that is the assimilation of Anglo-Québécois
translated into French in Quebec [Lane-Mercier 2018, 461–466] [Leconte 2019, 114–115] [17] Belantara and Bradinski’s study showed to what extent cataloguing
practices represent a process of negotiation of the cataloguer with the existing metadata standards such as MARC.
They claim that “[m]etadata reflects a compromise between what the cataloger knows about an
item and the existing system into which she is bound to embed it” [Belantara and Drabinski 2022, 4]. [18] In this article,
cataloguing practices encompasses the process of how the information on the records (author, publisher, year,
edition, etc.) is curated and published in the online catalogue so that the user can browse, filter, and access
the collection as well as the bibliographic data. Accordingly, the online catalogue represents the interface or
index that allows us to see what the collection contains. In comparison, collection practices describe the
process of adding editions to the library collection according to the deposit regulations — described in detail
in the last subsection.
[19] Hence, researchers should be cautious to either run analyses on recent data (e.g., a researcher
may choose to exclude pre-1996 data extracted from the DNB), or contextualize changing cataloguing practices when
dealing with earlier DNB datasets.
[20] A data quality assessment of these databases revealed that their
translation data appears to be less comprehensive as compared to the German National Library [Teichmann 2022, 56–58]. [21] According to the Bibliographic Data
Working Group (BDWG), “[b]ibliographical data are structured information about the form,
content, and context of documents in any form (textual, graphic, musical notation, etc.) or medium (printed,
electronic, etc.)” [Umerle et al 2022, 6]. [22] Bibliographic data on translations is also collected by companies for
marketing purposes or other institutions such as UNESCO in case of the Index
Translationum, publishing agencies, foundations, or alliances such as Bücher in Zahlen, Literatures
Across Frontiers, European, and the Federation of European Publishers. The BDWG also notes that “[t]oday OCLC’s WorldCat is the main service used to access the currently collected contents of
library catalogues” [Umerle et al 2022, 25]. This is the case for the German National
Library, though their collection and deposit regulations differ slightly, which we discuss in the last subsection
of this case study. [23] MARC can be defined as a “[s]tandard for the representation and exchange of
data in machine-readable form” [Umerle et al 2022, 115], which “provides the mechanism by which computers exchange, use, and interpret bibliographic information, and its data
elements make up the foundation of most library catalogs used today”[Library of Congress (a)] [24] The Digital Library
& Bibliography for Literature in Translation and Adaptation (DLBT) is another constantly expanding project
that collects bibliographic data on translation from national libraries such as the DNB and from research
projects.
[25] Several scholars working with translation data have noted
similar difficulties in a panel discussion on big translation history that took place at the Congress of the
European Society for Translation Studies in Stellenbosch in September of 2019 [Vimr 2020]. [26] Indeed, this information tends to be omitted in printed versions of books as well, making it
difficult to know with which edition of a book a given translator worked with when producing their
translation.
[27] The same is the case for the Library and Archives Canada online catalogue, which does not
include the original title or an additional language field for the original language. See https://bac-lac.on.worldcat.org/oclc/59166116,
accessed August 23, 2023. [28] In
addition, a certain level of expertise is required to successfully query the online catalogues for translations,
a difficulty that was pointed out by Borgman as early as 1996. Currently, most query languages do not contain an
option to only display translations since, as our examples show, translations are not visibly categorized as
such.
[29] Smith-Yoshimura proposed to identify translations by using the author/title field in the
bibliographic data from WorldCat in combination with Wikidata to establish whether it exists in another language.
If it was the case, it could be classified as a translation [Smith-Yoshimura 2017]. [30] A similar definition has
also been used for extracting data from the Biblioteca Nacional de Espana [Roig-Sanz and Fólica 2021]. [32] For a quality assessment of
the resulting data extracted from the DNB using this query see Teichmann 2022, 60–65.
[33] The same
applies to ExLibris, who provide services to most European national libraries. [ExLibris Indizes] [35] While the DNB online catalogue provides the option to export any record in MARC 21 to the user, for
the ÖNB catalogue this is only possible by using a Python code or manually, by first looking up the Metadata
Management System ID (MMS-ID), the AC-Nummer, or the barcode and adding it to a custom link: https://obv-at-oenb.alma.exlibrisgroup.com/view/sru/43ACC_ONB [Datalab] [38] A discussion of the influence of WorldCat on the
national library’s collection policies of translation lies beyond the scope of this study. The DNB shares
bibliographic data with WorldCat, however, to what extent that applies to translations has yet to be
investigated. As looking at the DNB, the ONB, and the BAnQ suggest, the collection practices are first and
foremost tied to their deposit regulations and not to enriching their catalogue with data from WorldCat. However,
these national libraries may still share their data with WorldCat, for which case I argue that documenting
collection and cataloguing practices on a national level “can reveal the ways these
large-scale discovery systems are built” [Belantara and Drabinski 2022, 2]. How often, how many
records, and which records are shared by national libraries with global databases such as OCLC or VIAF has yet to
be studied. [39] “All translations from the German language are collected. We receive most of these as mandatory
deposits. Other publications are acquired by donation, exchange or purchase.” [DNB (b)] [40] “Aus budgetären und
platztechnischen Gründen werden Übersetzungen nur in Auswahl gesammelt.[...] Eine Ausnahme wird bei der Schönen
Literatur gemacht. Hier bemüht sich die ÖNB alle erreichbaren Übersetzungen von österreichischen Werken (ohne
Mehrfachauflagen) in größtmöglicher Vollständigkeit anzuschaffen.” [Due to budget and spatial limitations,
only a selection of translations is collected, with the exception of belles
lettres (Schöne Literatur). For these works, the ÖNB endeavors to acquire all available translations of
Austrian works (without multiple editions) in the greatest possible completeness.] [OBV Wiki 2018] [41] Or rather “nationally”.
[42] See
“5.3 Langue des ressources documentaires” [5.3 Languages of ressources] in the “Politique de développement de la Collection universelle” [“Policy for
the development of the universal collection”]: “[La] BAnQ acquiert et
rend accessibles d’importantes collections en français. Dans une moindre mesure, BAnQ acquiert et rend
accessibles des ressources documentaires en anglais et dans d’autres langues en usage au Québec, en fonction des
besoins de ses clientèles. [” “The BAnQ acquires and provides access to important
collections in French. To a limited extent, the BAnQ also acquires and gives access to documents in English and
other languages which are used in Québec, based on the needs of its clients.”] [BAnQ] In
comparison, the Library and Archives of Canada collect any publications on a selective basis that are of interest
to Canada, which may reach beyond the national boundaries (see https://laws-lois.justice.gc.ca/eng/acts/l-7.7/page-1.html, accessed August 23, 2023). [47] For example, in a subset of 552 translated titles extracted from
the DNB for the year 2020, only three were identified as false positives (non-translations), which accounts for the
high precision and efficacy of the extraction method [Teichmann 2022, 60]. Works Cited
Armstrong etal 2022 Armstrong, Guyda, Marie-Alice Belle, A E B Coldiron,
Brenda M Hosington, and Joshua Reid. (2022) “On Researching Early Modern Mediated Translations:
Challenges and Prospects”.
Forum for Modern Language Studies 58 (4): 513–21.
https://doi.org/10.1093/fmls/cqac064.
Belantara and Drabinski 2022 Belantara, Amanda, and Emily Drabinski. (2022)
“Working Knowledge: Catalogers and the Stories They Tell”.
KULA:
Knowledge Creation, Dissemination, and Preservation Studies 6 (3): 1–10.
https://doi.org/10.18357/kula.233.
Belle and Hosington 2017 Belle, Marie-Alice, and Brenda M. Hosington. (2017)
“Translation, History and Print: A Model for the Study of Printed Translations in Early Modern
Britain”.
Translation Studies 10 (1): 2–21.
https://doi.org/10.1080/14781700.2016.1213184.
Brissette, Vallières, and Teichmann 2023 Brissette, Pascal, Julien
Vallières, and Lisa Teichmann. (2023) “Romans à Lire : statistiques descriptives
(2023)”.
Borealis.
https://doi.org/10.5683/SP3/HMSNVE.
DNB (c) DNB. “Feldbeschreibung Der Titeldaten Der Deutschen
Nationalbibliothek Und Der Zeitschriftendatenbank Im Format MARC 21”. (2023) Deutsche Nationalbibliothek.
https://d-nb.info/1282570226/34.
Dwyer 2011 Dwyer, Tessa. (2011) “Bad Talk: Media Piracy and
‘Guerilla’ Translation”. In Words, Images and Performances in Translation,
edited by Rita Wilson and Brigid Maher, 194–216. Bloomsbury Publishing.
Fawcett 2000 Fawcett, Peter. (2000) “Translation in the
Broadsheets” 6 (2): 295–307.
Ji and Oakes 2019 Ji, Meng, and Michael Oakes, eds. (2019)
Advances in Empirical Translation Studies: Developing Translation Resources and Technologies. Cambridge:
Cambridge University Press.
https://doi.org/10.1017/9781108525695.
Kotze et al 2021 Kotze, Haidee, Berit Janssen, Corina Koolen, Luka Van Der
Plas, and Gys-Walt Van Egdom. (2021) “Norms, Affect and Evaluation in the Reception of Literary
Translations in Multilingual Online Reading Communities: Deriving Cognitive-Evaluative Templates from Big
Data”.
Translation, Cognition & Behavior 4 (2): 147–86.
https://doi.org/10.1075/tcb.00060.kot.
Laforce and Ratté 2019 Laforce, Pascal, and Sylvie Ratté. (2019) “Système de recommandation basé sur les notices bibliographiques MARC 21 : étude de cas à Bibliothèque
et archives nationales du Québec (BAnQ)”.
Documentation et Bibliothèques 64
(2): 40–50.
https://doi.org/10.7202/1059160ar.
Lane-Mercier 2018 Lane-Mercier, Gillian. (2018) “From
English into French: Literary Translation as a Measure of the (Inter)Cultural Vitality of Quebec’ Anglophone
Communities”. In Engaging with Diversity: Multidisciplinary Reflections on Plurality
from Québec, edited by Stéphan Gervais, Raffaele Iacovino, and Mary Anne Poutanen, 457–76. Brussels: Peter
Lang.
Leconte 2019 Leconte, Marie. (2019) “Theorizing the
Peregrinations of Anglo/Québécois Literature in Translation”. PhD Thesis, Montréal: Université de
Montréal.
Li and Moratto 2022 Li, Riccardo Moratto, Defeng, ed. (2022)
Advances in Corpus Applications in Literary and Translation Studies. London: Routledge.
https://doi.org/10.4324/9781003298328.
Monti 2013 Monti, Enrico. (2013) “Échos de la traduction dans la
presse culturelle : étude comparative de trois suppléments littéraires – États-Unis, France et Italie”.
Synergies Pologne, no. 10: 109–21.
Monti 2016 Monti, Enrico. (2016) “La traduction dans la presse
culturelle. Une étude contrastive : France, États-Unis, Royaume-Uni”. Atelier de
traduction, no. 26: 121–35.
Ngué Um et al 2022 Ngué Um, Emmanuel, Émilie Eliette, Caroline Ngo Tjomb
Assembe, and Francis Morton Tyers. (2022) “Developing a Rule-Based Machine-Translation System,
Ewondo–French–Ewondo.”
International Journal of Humanities & Arts Computing
16 (2): 166–81.
https://doi.org/10.3366/ijhac.2022.0289.
Norrick-Rühl and Bold 2016 Norrick-Rühl, Corinna, and Melanie Ramdarshan
Bold. (2016) “Crossing the Channel: Publishing Translated German Fiction in the UK”.
Publishing Research Quarterly 32 (2): 125–38.
https://doi.org/10.1007/s12109-016-9458-3.
Özmen 2019 Özmen, Ceyda. (2019) “Beyond the
Book: The Periodical as an ‘Excavation Site’ for Translation Studies”.
TranscUlturAl: A
Journal of Translation and Cultural Studies 11 (1): 3–21.
https://doi.org/10.21992/tc29447.
Pickford 2016 Pickford, Susan. (2016) “The Factors Governing
the Availability of Maghrebi Literature in English: A Case Study in the Sociology of Translation”. CLINA 2–1 (June): 77–94.
Poupaud, Pym, and Simón 2009 Poupaud, Sandra, Anthony Pym, and Ester Torres
Simón. (2009) “Finding Translations. On the Use of Bibliographical Databases in Translation
History”.
Meta 54 (2): 264–78.
https://doi.org/10.7202/037680ar.
Regniers 2021 Regniers, Gaëtan. (2021) “War, Peace and
Franco-Russian Relations: French Translations of Tolstoy’s ‘Sebastopol Sketches’ in Periodicals
(1855–1885)”. World Literature Studies 13 (3): 56–67.
Reynolds and Vitali 2021 Reynolds, Matthew, and Giovanni Pietro Vitali.
(2021) “Mapping and Reading a World of Translations: Prismatic Jane Eyre”.
Modern Languages Open 1 (December): 23.
https://doi.org/10.3828/mlo.v0i0.375.
Roig-Sanz , Fólica, and Ikoff 2021 Roig-Sanz, Diana, Laura Fólica, and
Ventsislav Ikoff. (2021) “Translation in Literary Magazines”. In
The Routledge Handbook of Translation and Media, edited by Esperança Bielsa, 1st ed. London: Routledge.
https://www.taylorfrancis.com/books/9781003221678.
Roig-Sanz and Fólica 2021 Roig-Sanz, Diana, and Laura Fólica. (2021)
“Big Translation History: Data Science Applied to Translated Literature in the Spanish-speaking
World, 1898–1945”.
Translation Spaces 10 (2): 231–59.
https://doi.org/10.1075/ts.21012.roi.
Rybicki 2012 Rybicki, Jan. (2012) “The Great Mystery of the
(Almost) Invisible Translator”. Quantitative Methods in Corpus-Based Translation
Studies: A Practical Guide to Descriptive Translation Research 231.
Smith-Yoshimura 2017 Smith-Yoshimura, Karen. (2017) “Using the Semantic Web to Improve Knowledge of Translations”. In Proceedings of the
2017 International Conference on Dublin Core and Metadata Applications, 27. DCMI’17. Washington, DC, USA:
Dublin Core Metadata Initiative.
Taivalkoski-Shilov 2013 Taivalkoski-Shilov. (2013) “Tracing the Editor’s Voice: On Editors’ Autobiographies”. In Authorial and Editorial
Voices in Translation: Editorial and Publishing Practices, edited by Hanne Jansen and Anna Wegener, Vol. 2,
65–83. Montréal: Éditions québécoises de l’œuvre.
Umerle et al 2022 Umerle, Tomasz, Giovanni Colavizza, Elżbieta Herden, Rindert
Jagersma, Péter Király, Beata Koper, Leo Lahti, et al. (2022) “An Analysis of the Current
Bibliographical Data Landscape in the Humanities. A Case for the Joint Bibliodata Agendas of Public
Stakeholders”, May.
https://doi.org/10.5281/ZENODO.6559857.
Vanderschelden 2000 Vanderschelden, Isabelle. (2000) “Quality Assessment and Literary Translation in France”. The Translator 6 (2):
271–93.
Venuti 1995 Venuti, Lawrence. (1995) The Translator’s
Invisibility. New York/London: Routledge.
Vimr 2020 Vimr, Ondřej. (2020) “Big Translation History and the
Use of Data Mining and Big Data Approaches: Panel Report and Observations”.
Chronotopos
- A Journal of Translation History, February, 192-195 Pages.
https://doi.org/10.25365/CTS-2019-1-2-11.
Vimr 2022 Vimr, Ondřej. (2022) “Choosing Books for Translation: A
Connectivity Perspective on International Literary Flows and Translation Publishing”. In
Global Literary Studies, edited by Diana Roig-Sanz and Neus Rotger, 279–300. De Gruyter.
https://doi.org/10.1515/9783110740301-012.
Wakabayashi 2019 Wakabayashi, Judy F. (2019) “Digital
Approaches to Translation History”. Translation & Interpreting 11 (2):
132–45.
Whitfield 2006 Whitfield, Agnès. (2006) Writing Between the
Lines: Portraits of Canadian Anglophone Translators. Waterloo: Wilfrid Laurier Univ. Press.
Whitfield 2013 Whitfield, Agnès. (2013) “Author-Publisher-Translator Communication in English-Canadian Literary Presses since 1960”. In Authorial and Editorial Voices in Translation - Editorial and Publishing Practices, edited by
Anna Wegener and Hanne Jansen. Vol. 209–237, Montréal: Éditions québécoises de l’œuvre.