



Volume 18 Number 3
Towards a differentiated digital-hermeneutic analysis tool for the detection of short quotations using the example of the Church Father Jerome
Abstract
Late Latin literature is characterized by numerous references to classical texts and authors. For Jerome of Stridon in particular, manual-hermeneutic research has revealed various intertextuality phenomena usually published in encyclopaedic collections of quotations. In this paper, we present a digital-hermeneutic analysis toolkit primarily designed to detect short text-text congruencies that have a high chance of being evaluated as an intentional quotation. We favour a mixed-methods approach, which is based on findings from manual-hermeneutic research. Our aim is to focus on Jerome's citation technique: Based on hermeneutic analysis of confirmed quotations, we formulate differentiated criteria that lead to a deeper understanding of the phenomenon of quoting and thus also have the potential to optimize our toolkit.
I. Classification of the digital analysis process
II. Principles, preconditions, and definitions
Corpus requirements
Terminology
III. The (digital) detection process
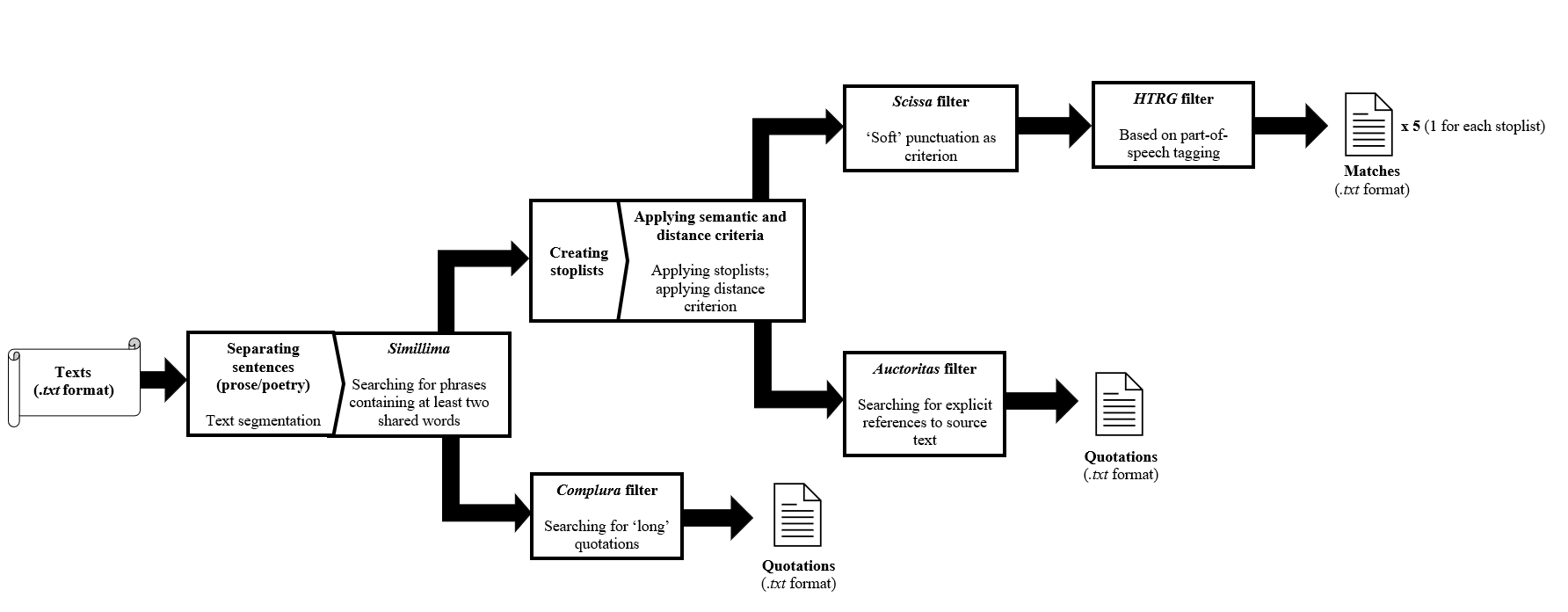
Step 0: Preparing the texts
Step 1: Separation of sentences und text comparison through Simillima
Step 2: Applying the Complura filter
| Verg. ecl. 8,57–63 | Hier. epist. 52,9,3 |
| incipe Maenalios mecum, mea tibia, uersus. / omnia uel medium fiat mare. uiuite siluae: / praeceps aërii specula de montis in undas / deferar; extremum hoc munus morientis habeto. / desine Maenalios, iam desine, tibia, uersus. / Haec Damon; uos, quae responderit Alphesiboeus, / dicite, Pierides: non omnia possumus omnes. | sed et genus adrogantiae est clementiorem te uideri uelle, quam pontifex Christi est. non omnia possumus omnes. alius in ecclesia oculus est, alius lingua, alius manus, alius pes, alius auris, uenter et cetera. lege Pauli ad Corinthios: diuersa membra unum corpus efficiunt. nec rusticus et tantum simplex frater ideo se sanctum putet, si nihil nouerit, nec peritus et eloquens in lingua aestimet sanctitatem. multoque melius est e duobus inperfectis rusticitatem sanctam habere quam eloquentiam peccatricem. |
| Begin with me, my flute, a song of Maenalus! Nay, let all become mid-ocean! Farewell, ye woods! Headlong from some towering mountain peak I will throw myself into the waves; take this as my last dying gift! Cease, my flute, now cease the song of Maenalus!” Thus Damon. Tell, Pierian maids, the answer of Alphesiboeus; we cannot all do everything. [19] | But it is also a kind of arrogance to want to appear more charitable than Christ's bishop is. Not all of us can do everything. In the Church, one is the eye, another the tongue, a third the hand, still another the foot, another the ears, the stomach, and so on. Read in Paul's letter to the Corinthians: the various members form one body. An uneducated and quite plain brother, if he knows nothing, should not therefore consider himself holy, and neither should an educated and eloquent brother measure his holiness by eloquence. But of the two imperfect kinds, holy modesty is far better than sinful eloquence.[20] |
Step 3: Applying filters based on semantic and distance criteria
Step 4: Applying the Auctoritas filter
| Verg. georg. 2,248–258 | Hier. epist. 121,10,5 |
| pinguis item quae sit tellus, hoc denique pacto / discimus: haud unquam manibus iactata fatiscit, / sed picis in morem ad digitos lentescit habendo. / umida maiores herbas alit, ipsaque iusto / laetior. a, nimium ne sit mihi fertilis illa, / nec se praeualidam primis ostendat aristis! / quae grauis est, ipso tacitam se pondere prodit, / quaeque leuis. promptum est oculis praediscere nigram, / et quis cui color. at sceleratum exquirere frigus / difficile est: piceae tantum taxique nocentes / interdum aut hederae pandunt uestigia nigrae. | nec hoc miremur in apostolo, si utatur eius linguae consuetudine, in qua natus est et nutritus, cum Uergilius, alter Homerus apud nos, patriae suae sequens consuetudinem ‘sceleratum’ frigus appellet. nemo ergo uos superet atque deuincat uolens humilitatem litterae sequi et angelorum religionem atque culturam, ut non seruiatis spiritali intellegentiae, sed exemplaribus futurorum, quae nec ipse uidit, qui uos superare desiderat, siue uidet — utrumque enim habetur in Graeco — ,praesertim cum tumens ambulet et incedat inflatus mentisque superbiam et gestu corporis praeferat — hoc enim significat ἐμβατεύων — ,frustra autem infletur et tumeat sensu carnis suae carnaliter cuncta intellegens et traditionum Iudaicarum deliramenta perquirens et non tenens caput omnium scripturarum illud, de quo dictum est: caput uiri Christus est, caput autem atque principium totius corporis eorumque, qui credunt, et omnis intellegentiae spiritalis. |
| Again, richness of soil we learn in this way only: never does it crumble when worked in the hands, but like pitch grows sticky in the fingers when held. A moist soil rears taller grass and is of itself unduly prolific. Ah! not mine be that over-fruitful soil, and may it not show itself too strong when the ears are young! A heavy soil betrays itself silently by its own weight; so does a light one. It is easy for the eye to learn at once a black soil and the hue of any kind. But to detect the villainous cold is hard; only pitch pines or baleful yews and black ivy sometimes reveal its traces. | Let us not be surprised at this in the apostle, that he uses his accustomed language, with which he was born and brought up, since Virgil, our second Homer, following the custom of his homeland, calls the cold ‘criminal’. Let no one, then, surpass you and prevail over you who wants to follow the simplicity of Scripture and the worship and adoration of angels, even if you do not serve the spiritual knowledge, but as examples for future times, which the one who wants to despise you has neither seen nor sees himself — for both translations are valid according to the Greek text — especially since he proudly parades around, comes along puffed up, and carries haughtiness before him in spirit and posture — for this is what ἐμβατεύων means — for in vain does he puff himself up and boast, when with the sense of his flesh he understands all things carnally, and investigates the silliness of Jewish traditions, and does not hold to the head of all scriptures, that of which it is written: The head of the man is Christ, namely the head and the beginning of the whole body and of those who believe, and the head of all spiritual knowledge. |
Step 5: Applying the “Scissa” filter
| Verg. georg. 1,322–327 | Hier. epist. 108,28,3 |
| saepe etiam immensum caelo uenit agmen aquarum, / et foedam glomerant tempestatem imbribus atris / collectae ex alto nubes: ruit arduus aether / et pluuia ingenti sata laeta boumque labores / diluit; implentur fossae et caua flumina crescunt / cum sonitu feruetque fretis spirantibus aequor. | aderant Hierosolymorum et aliarum urbium episcopi et sacerdotum inferioris gradus ac Leuitarum innumerabilis multitudo. omne monasterium uirginum et monachorum chori repleuerant. statimque ut audiuit sponsum uocantem: surge, ueni, proxima mea, speciosa mea, columba mea, quoniam ecce hiemps pertransiuit, pluuia abiit sibi, laeta respondit: flores uisi sunt in terra, tempus sectionis aduenit et: credo uidere bona domini in terra uiuentium. |
| Often, too, there appears in the sky a mighty column of waters, and clouds mustered from on high roll up a murky tempest of black showers: down falls the lofty heaven, and with its deluge of rain washes away the gladsome crops and the labours of oxen. The dykes fill, the deep-channelled rivers swell and roar, and the sea steams in its heaving friths. | Present were the bishops of Jerusalem and of other cities, priests of lower rank, and an innumerable multitude of Levites. The whole monastery was filled with crowds of virgins and monks. As soon as she heard the bridegroom speak, ‘Arise, come, my beloved, my fair one, my dove, for behold, winter is over, the rains have ceased,’ she answered joyfully, ‘Flowers have appeared on the earth, the time of cutting is here,’ and, ‘But I believe to behold the kindness of the Lord in the land of the living.’ |
Step 6: Applying the historical text-reuse grammar (HTRG) filter[31]
Potential findings from computer-assisted text comparison, whose matching word material consists of at least two nouns or two verbs as well as a combination of these two word classes, [are] particularly suited to establish a meaning-producing text-to-text relationship.[32] [Revellio 2022, 151]
IV. Optimization strategies based on the analysis of published Quotations of Virgil in Jerome
1. Optimization strategy: Taking into account the direct environment of shared words
| Verg. ecl. 4,60–63 | Hier. epist. 130,16,3 |
| Incipe, parue puer, risu cognoscere matrem: / matri longa decem tulerunt fastidia menses. / incipe, parue puer: qui non risere parentes, / nec deus hunc mensa, dea nec dignata cubili est. | solent enim huiusce modi per angulos musitare et quasi iustitiam dei quaerere: ‘cur illa anima in illa est nata prouincia? quid causae extitit, ut alii de Christianis nascantur parentibus, alii inter feras et saeuissimas nationes, ubi nulla dei notitia est?’ cumque hoc quasi scorpionis ictu simplices quosque percusserint et fistulato uulnere locum sibi fecerint, uenena diffundunt: ‘putasne, frustra infans paruulus et qui uix matrem risu et uultus hilaritate cognoscat, qui nec boni aliquid fecit nec mali, daemone corripitur, morbo opprimitur regio et ea sustinet, quae uidemus inpios homines non sustinere et sustinere deo seruientes? |
| Begin, baby boy, to recognize your mother with a smile: ten months have brought your mother long travail. Begin, baby boy! The child who has not won a smile from his parents, no god ever honoured with his table, no goddess with her bed! | Some of this kind are wont to whisper in silent corners and downright question the justice of God: ‘Why was that soul born in that region? What reason was found that some were conceived by Christian parents, others were born in savage and most wicked peoples who have no knowledge of God?’ As soon as they have shaken some simple people by this, as by the sting of a scorpion, and have made a place for themselves in the tubular wound, they spout their venom: ‘Do you think a very young child, one who barely recognizes its mother by her laughter and her face by her joy, who has done neither good nor bad, is seized by the devil for no reason, or prostrated by jaundice, or endures such things for no reason, which we see godless people do not suffer, but those who serve God do?’ |
2. Optimization strategy: Considering the syntactic complexity of highly frequent phrases
| Verg. Aen. 9,5–13 | Hier. epist. 130,5,3 |
| ad quem sic roseo Thaumantias ore locuta est: / ‘Turne, quod optanti diuum promittere nemo / auderet, uoluenda dies en attulit ultro. / Aeneas urbe et sociis et classe relicta / sceptra Palatini sedemque petit Euandri. / nec satis: extremas Corythi penetrauit ad urbes / Lydorumque manum, collectos armat agrestis. / quid dubitas? nunc tempus equos, nunc poscere currus: / rumpe moras omnis et turbata arripe castra.’ | urbs tua, quondam orbis caput, Romani populi sepulchrum est, et tu in Libyco litore exulem uirum ipsa exul accipies? quam habitura pronubam? quo deducenda comitatu? stridor linguae Punicae procacia tibi fescennina cantabit. rumpe moras omnes. perfecta dilectio foras mittit timorem. adsume scutum fidei, loricam iustitiae, galeam salutis, procede ad proelium. habet et seruata pudicitia martyrium suum. quid metuis auiam? quid formidas parentem? forsitan et ipsae uelint, quod te uelle non credunt. |
| To him, with roseate lips, thus spoke the child of Thaumas: ‘Turnus, what no god dared to promise to your prayers, see––the circling hour has brought unasked! Aeneas, leaving town, comrades and fleet, seeks the Palatine realm and Evander’s dwelling. Nor does that suffice; he has won his way to Corythus’ furthest cities, and is mustering the Lydian country folk in armed bands. Why hesitate? Now, now is the hour to call for steed and chariot; break off delay, and seize the bewildered camp! | Your city, once the head of the world, is the tomb of the Roman people, and will you, even in exile, accept a man, also exiled, on the coast of Libya? What matchmaker shalt thou have? By what companion shalt thou be led home? The hiss of the Punic language will sing cheeky Fescennine wedding songs for thee. Abandon all procrastination. Perfect love sends fear at the door. Seize the shield of faith, the armor of righteousness, the helmet of salvation, march out to battle. Even the preservation of chastity holds its own martyrdom. What do you fear your grandmother? What do you fear your mother? Maybe they even want for you what they don't think you want. |
| Verg. georg. 1,401–403 | Hier. epist. 108,17,1 |
| at nebulae magis ima petunt campoque recumbunt, / solis et occasum seruans de culmine summo / nequiquam seros exercet noctua cantus. | Uerum haec possunt communia esse cum <non> paucis et scit diabolus non in summo uirtutum culmine posita. |
| But the mists are prone to seek the valleys, and rest on the plain, and the owl, as she watches the sunset from some high peak, vainly plies her evening song. | But these things can be common to a few, and the devil knows that they are not on the highest pinnacle of virtue. |
3. Optimization strategy: Taking into account the manuscript tradition
| Verg. Aen. 4,31–44 | Hier. epist. 126,2,2 |
| Anna refert: ‘o luce magis dilecta sorori, / solane perpetua maerens carpere iuuenta, / nec dulcis natos Veneris nec praemia noris? / id cinerem aut manis credis curare sepultos? / esto: aegram nulli quondam flexere mariti, / non Libyae, non ante Tyro; despectus Iarbas / ductoresque alii, quos Africa terra triumphis / diues alit: placitone etiam pugnabis amori? / nec uenit in mentem quorum consederis aruis? / hinc Gaetulae urbes, genus insuperabile bello, / et Numidae infreni cingunt et inhospita Syrtis; / hinc deserta siti regio lateque furentes / Barcaei. quid bella Tyro surgentia dicam / germanique minas? | hoc autem anno, cum tres explicassem libros, subitus impetus barbarorum, de quibus tuus dicit Uergilius: lateque uagantes Barcaei et sancta scriptura de Ismahel: contra faciem omnium fratrum suorum habitabit, sic Aegypti limitem, Palaestinae, Phoenices, Syriae percucurrit ad instar torrentis cuncta secum trahens, ut uix manus eorum misericordia Christi potuerimus euadere. quodsi iuxta inclitum oratorem silent inter arma leges, quanto magis studia scripturarum, quae et librorum multitudine et silentio ac librariorum sedulitate, quodque uel proprium est, securitate et otio dictantium indigent! |
| Anna replies: ‘O you who are dearer to your sister than the light, are you, lonely and sad, going to pine away all your youth long, and know not sweet children or love’s rewards? Do you think that dust or buried shades give heed to that? Grant that until now no wooers moved your sorrow, not in Libya, nor before then in Tyre; that Iarbas was slighted, and other lords whom the African land, rich in triumphs, rears; will you wrestle also with a love that pleases? And does it not come to your mind whose lands you have settled in? On this side Gaetulian cities, a race invincible in war, unbridled Numidians, and the unfriendly Syrtis hem you in; on that side lies a tract barren with drought, and Barcaeans, raging far and wide. Why speak of the wars rising from Tyre, and your brother’s threats ...? | In this year, however, when I had already explained three books, a sudden onslaught of the barbarians, about whom your Virgil says: ‘the far-roaming Barkaeans’ and the holy scripture about Ishmael: ‘opposed to the face of all his brothers he shall live’, overtook the borders of Egypt, Palestine, Phoenicia, Syria and swept away everything like a torrent, so that we could escape their clutches just by the mercy of Christ. But if, according to the famous orator, laws are silent in war, how much more the occupation with the Scriptures, which requires a multitude of books, rest as well as busyness of the scribes and finally, as a special characteristic, the security and leisure for the person dictating! |
| Verg. Aen. 4,31–44 | Hier. epist. 129,4,3 |
| Anna refert: ‘o luce magis dilecta sorori, / solane perpetua maerens carpere iuuenta, / nec dulcis natos Veneris nec praemia noris? / id cinerem aut manis credis curare sepultos? / esto: aegram nulli quondam flexere mariti, / non Libyae, non ante Tyro; despectus Iarbas / ductoresque alii, quos Africa terra triumphis / diues alit: placitone etiam pugnabis amori? / nec uenit in mentem quorum consederis aruis? / hinc Gaetulae urbes, genus insuperabile bello, / et Numidae infreni cingunt et inhospita Syrtis; / hinc deserta siti regio lateque furentes / Barcaei. quid bella Tyro surgentia dicam / germanique minas? | ab Ioppe usque ad uiculum nostrum Bethleem quadraginta sex milia sunt, cui succedit uastissima solitudo plena ferocium barbarorum, de quibus dicitur: contra faciem omnium fratrum tuorum habitabis et quorum facit poeta eloquentissimus mentionem: lateque uagantes Barcaei, a Barca oppido, quod in solitudine situm est, quos nunc corrupto sermone Afri Baricianos uocant. hi sunt, qui pro locorum qualitatibus diuersis nominibus appellantur et a Mauritania per Africam et Aegyptum Palaestinamque et Phoenicem, Coelen Syriam et Osrohenen, Mesopotamiam atque Persidem tendunt ad Indiam. |
| Anna replies: ‘O you who are dearer to your sister than the light, are you, lonely and sad, going to pine away all your youth long, and know not sweet children or love’s rewards? Do you think that dust or buried shades give heed to that? Grant that until now no wooers moved your sorrow, not in Libya, nor before then in Tyre; that Iarbas was slighted, and other lords whom the African land, rich in triumphs, rears; will you wrestle also with a love that pleases? And does it not come to your mind whose lands you have settled in? On this side Gaetulian cities, a race invincible in war, unbridled Numidians, and the unfriendly Syrtis hem you in; on that side lies a tract barren with drought, and Barcaeans, raging far and wide. Why speak of the wars rising from Tyre, and your brother’s threats ...? | From Jaffa to our little village of Bethlehem is a distance of 46 miles, adjoining which is a vast wasteland, full of savage barbarians, about whom it is said: ‘opposed to the face of all thy brethren shalt thou live,’ and the mention of which our most eloquent poet thus forms: ‘the far-roaming Barkaeans,’ namely, from the city of Barka, which is situated in the wasteland, whom the Africans now call, in a neglected manner of speech, Barikians. These are the ones whom they call by different names according to the nature of the places, stretching from Mauritania through Africa and Egypt, Palestine and Phoenicia, Syria Coele and Osrhoene, Mesopotamia and Persia to India. |
4. Optimization strategy: Repeated quotations as evidence for source-text familiarity
| Verg. Aen. 11,278–287 | Hier. epist. 84,3,5 |
| ne uero, ne me ad talis impellite pugnas: / nec mihi cum Teucris ullum post eruta bellum / Pergama nec ueterum memini laetorue malorum. / munera quae patriis ad me portatis ab oris / uertite ad Aenean. stetimus tela aspera contra / contulimusque manus: experto credite quantus / in clipeum adsurgat, quo turbine torqueat hastam. / si duo praeterea talis Idaea tulisset / terra uiros, ultro Inachias uenisset ad urbes / Dardanus et uersis lugeret Graecia fatis. | quod autem opponunt congregasse me libros illius super cunctos homines, utinam omnium tractatorum haberem uolumina, ut tarditatem ingenii lectionis diligentia conpensarem! congregaui libros eius, fateor; et ideo errores non sequor, quia scio uniuersa, quae scripsit. credite experto, quasi Christianus Christianis loquor: uenenata sunt illius dogmata, aliena a scripturis sanctis, uim scripturis facientia. legi, inquam, legi Origenem et, si in legendo crimen est, fateor — et nostrum marsuppium Alexandrinae chartae euacuarunt — : si mihi creditis, Origeniastes numquam fui; si non creditis, nunc esse cessaui. |
| Do not, do not urge me to such battles! I have no war with Teucer’s race since Troy’s towers fell, and I have no joyful memory of those ancient ills. The gifts that you bring me from your country, take them rather to Aeneas. We have faced his fierce weapons, and fought him hand to hand: trust one who has experienced it, how huge he looms above his shield, with what whirlwind he hurls his spear! Had Ida’s land borne two others like him, the Trojans would even have stormed the towns of Inachus, and Greece would be mourning, with fate reversed. | But this they oppose, that I have gathered together the books of that one about all men; oh, if I had the volumes of all commentators, in order to compensate the slowness of the mind by the diligence of the reading! I have collected his books, I confess; and therefore, I do not follow errors, because I know all that he has written. Trust the one who has experienced it, as if I speak to Christians as a Christian; poisoned are his doctrines, strange in relation to the sacred writings, because they do violence to them. Yes, I have read, I say, I have read Origen, and, if in reading there is an offense, I confess it — and my purse emptied Alexandrian leaves — : If you believe me, I was never a follower of Origen; if you do not believe me, I have now ceased to be one. |
V. Concluding remarks and outlook
- (a) the lemmatization of the close environment of quotations,
- (b) the analysis of syntactic complexity, especially of compact frequent phrases,
- (c) the consideration of the manuscript tradition, and
- (d) the testing for iteration of quotations or quotation fragments.
- (a) either further quoted words (inflected or replaced by synonyms) or an explicit reference (e.g. naming the source author) are found in the environment,
- (b) high-frequency phrases are quoted in their exact syntactic structure (and thus at the same time are longer quotations),
- (c) editorial changes obscure further shared words (precisely a problem of computer-aided access to digital texts), or
- (d) finally the reuse of a quotation fragment can be proven.
Primary Sources
Notes
| Verg. georg. 1,401–403 | Hier. epist. 116,5,2 |
| at nebulae magis ima petunt campoque recumbunt, / solis et occasum seruans de culmine summo / nequiquam seros exercet noctua cantus | immo uero sanctam scripturam in summo et caelesti auctoritatis culmine conlocatam de ueritate eius certus ac securus legam |
| But the mists are prone to seek the valleys, and rest on the plain, and the owl, as she watches the sunset from some high peak, vainly plies her evening song | but of course I should read the holy scriptures, set on the highest, heavenly summit of validity, firmly convinced of their truth |
Works Cited
Recommendations
DHQ is testing out three new article recommendation methods! Please explore the links below to find articles that are related in different ways to the one you just read. We are interested in how these methods work for readers—if you would like to share feedback with us, please complete our short evaluation survey. You can also visit our documentation for these recommendation methods to learn more.
SPECTER Recommendations
Below are article recommendations generated by the SPECTER model:
- Textual Reuse in the Eighteenth Century: Mining Eliza Haywood’s Quotations, 2016, Douglas Ernest Duhaime, University of Notre Dame
- Deconstructing Bricolage: Interactive Online Analysis of Compiled Texts with Factotum, 2015, Tomas Zahora, Monash University; Dmitri Nikulin, Google; Constant J. Mews, Monash University; David Squire, Monash University
- Comparing Disciplinary Patterns: Exploring the Humanities through the Lens of Scholarly Communication, 2017, Daniel Burckhardt, Humboldt-Universität zu Berlin
- Comparative rates of text reuse in classical Latin hexameter poetry, 2015, Neil Bernstein, Ohio University; Kyle Gervais, University of Western Ontario; Wei Lin, Ohio University
- Canonical References in Electronic Texts: Rationale and Best Practices, 2014, Joel Kalvesmaki, Dumbarton Oaks
DHQ Keyword Recommendations
Below are article recommendations generated by DHQ Keywords:
- Continuous Integration and Unit Testing of Digital Editions, 2018, Bridget Almas, The Alpheios Project, Ltd.; Thibault Clérice, Centre Jean-Mabillon (École des chartes) - PSL
- Citation in Classical Studies, 2009, Neel Smith, College of the Holy Cross
- Technology, Collaboration, and Undergraduate Research, 2009, Christopher Blackwell, Furman University; Thomas R. Martin, College of the Holy Cross
- Exploring Citation Networks to Study Intertextuality in Classics, 2016, Matteo Romanello, Deutsches Archäologisches Institut, Berlin / École Polytechnique Fédérale de Lausanne
- Researcher as Bricoleur: Contextualizing humanists’ digital workflows, 2018, Smiljana Antonijevic, The Pennsylvania State University; Ellysa Stern Cahoy, The Pennsylvania State University
TF-IDF Recommendations
Below are article recommendations generated by the TF-IDF Model:
- Conclusion: Cyberinfrastructure, the Scaife Digital Library and Classics in a Digital age, 2009, Christopher Blackwell, Furman University; Gregory Crane, Tufts University
- A Culture of non-citation: Assessing the digital impact of British History Online and the Early English Books Online Text Creation Partnership, 2016, Jonathan Blaney, Institute of Historical Research, University of London; Judith Siefring, Bodleian Libraries, University of Oxford
- Fading Away... The challenge of sustainability in digital studies, 2020, Christine Barats, Cerlis, University of Paris Descartes; Valérie Schafer, C²DH, University of Luxembourg; Andreas Fickers, C²DH, University of Luxembourg
- Deconstructing Bricolage: Interactive Online Analysis of Compiled Texts with Factotum, 2015, Tomas Zahora, Monash University; Dmitri Nikulin, Google; Constant J. Mews, Monash University; David Squire, Monash University
- SEDES: Metrical Position in Greek Hexameter, 2023, Stephen A. Sansom, Florida State University; David Fifield, Independent Scholar

Comments: dhqinfo@digitalhumanities.org
Published by: The Alliance of Digital Humanities Organizations and The Association for Computers and the Humanities
Affiliated with: Digital Scholarship in the Humanities
DHQ has been made possible in part by the National Endowment for the Humanities.
Copyright © 2005 - 2025

Unless otherwise noted, the DHQ web site and all DHQ published content are published under a Creative Commons Attribution-NoDerivatives 4.0 International License. Individual articles may carry a more permissive license, as described in the footer for the individual article, and in the article’s metadata.
