


Volume 17 Number 4
Problems of Authorship Classification: Recognising the Author Style or a Book?
Abstract
The presented article proposes that one of the problems regarding authorship attribution tasks is the attribution of a specific book rather than the author. This often leads to overestimated reported performance. This problem is in general connected to the dataset construction and more specifically to the train-test data split. Using a heavily delexicalized and diverse dataset of Czech authors and basic LinearSVC classifiers, we designed a three-step experiment setting to explore book versus author attribution effects. First, the authorship attribution task is performed on a dataset split to train and test data segments across books. Second, the same task is performed on a dataset where individual books are used wholly either for training or testing. Expectedly, this leads to poorer results. In the third step, we do not attribute book segments to authors but to books themselves. This step reveals that there is a general tendency towards attributing to a specific book rather than to different books of the same author. The results indicate that authors who show a higher inner confusion among their works (i.e., the model attributes their works to other works of theirs) tend to perform better in the task of attribution of an unseen book.
Introduction
| Train and Test Across All Books of the Dataset (Experiments: Step 1) | |||||
| Segment Length | s-1000 | s-500 | s-200 | s-100 | s-50 |
| Full Dataset | 0.96 | 0.90 | 0.73 | 0.58 | 0.42 |
| Validation | 0.96 | 0.91 | 0.74 | 0.58 | 0.42 |
| Train Books vs. Test Books (Experiments: Step 2) | |||||
| Set 1 | 0.86 | 0.80 | 0.62 | 0.44 | 0.29 |
| Set 2 | 0.86 | 0.78 | 0.58 | 0.38 | 0.23 |
| Set 3 | 0.90 | 0.82 | 0.63 | 0.42 | 0.26 |
| Set 4 | 0.77 | 0.69 | 0.51 | 0.35 | 0.23 |
| Set 5 | 0.92 | 0.85 | 0.66 | 0.47 | 0.33 |
Dataset
Data Preparation
Data Cleaning
Segments and Train-Test Split
Delexicalisation
Hyperparameter Search: Authorship Classification at Varying Levels of Delexicalisation
- r-04: No delexicalisation (baseline) — original word forms are used
- r-05: Lemmatisation — lemmas used instead of word forms
- r-06: Part-of-speech tags for all words
- r-07: Morphological tags for all words
- r-08: Part-of-speech tags for autosemantic words, others lemmatised
- r-09: Morphological tags for autosemantic words, others lemmatised
- r-10: NameTag tags for recognised named entities, others with original word forms
- r-11: NameTag tags for recognised named entities, others lemmatised
- r-12: NameTag tags for recognised named entities, part-of-speech tags for autosemantic words, others lemmatised
- r-13 NameTag tags for recognised named entities, morphological tags for autosemantic words, others lemmatised
- Naive Bayes (sklearn.naive_bayes.MultinomialNB)
- C-Support Vector Classification (sklearn.svm.SVC)
- Linear Support Vector Classification (sklearn.svm.LinearSVC)
- K-Nearest Neighbours (sklearn.neighbors.KNeighborsClassifier)
- Stochastic Gradient Descent (sklearn.linear_model.SGDClassifier)
- Decision Tree (sklearn.tree.DecisionTreeClassifier)
| Segment Length | s-1000 | s-500 | s-200 | s-100 | s-50 |
| r-04 | 0.99 | 0.99 | 0.97 | 0.94 | 0.87 |
| r-05 | 1.00 | 0.99 | 0.97 | 0.94 | 0.87 |
| r-06 | 0.95 | 0.91 | 0.79 | 0.69 | 0.60 |
| r-07 | 0.97 | 0.96 | 0.90 | 0.83 | 0.71 |
| r-08 | 0.96 | 0.95 | 0.86 | 0.77 | 0.62 |
| r-09 | 0.97 | 0.96 | 0.89 | 0.82 | 0.70 |
| r-10 | 0.99 | 0.98 | 0.96 | 0.93 | 0.86 |
| r-11 | 1.00 | 0.98 | 0.97 | 0.93 | 0.86 |
| r-12 | 0.97 | 0.95 | 0.88 | 0.78 | 0.64 |
| r-13 | 0.98 | 0.95 | 0.89 | 0.83 | 0.71 |
Experiments and Results
- The full dataset (see above; 23 authors, 210 books) was used for a task of authorship attribution with each book divided into “train” (80%) and “test” (20%) passages. We reported performance across different lengths of passages. This is an “easy” setting for the classifier.
- Next, we performed the experiment with the same settings, but this time we built the “test” set by choosing one book from each author and adding all its segments into the test set. All other books of each author were used in their entirety for training. In this “harder” setting, performance dropped significantly, which is the main point of this paper. Furthermore, classification performance was influenced by the selection of the testing books.
- Finally, we performed the same experiment as outlined in #1, but instead of classifying by author, we classified segments into individual books. With this experiment, it is possible to discuss further why the test-book selection in Experiment #2 is so influential, as well as to show that some authors are more consistent in their style (as expressed by the selected features) than others.
Step 1. Train and Test Across All Books of the dataset
| Across Books | s-1000 | s-500 | s-200 | s-100 | s-50 |
| Full Dataset | 0.96 | 0.91 | 0.74 | 0.58 | 0.42 |
| Full Dataset, Validation | 0.96 | 0.9 | 0.73 | 0.58 | 0.42 |
| Small Dataset (6 Authors) | 0.96 | 0.95 | 0.86 | 0.77 | 0.62 |
Step 2. “Train” Books Versus “Test” Books
| Book-Based | s-1000 | s-500 | s-200 | s-100 | s-50 |
| Set 1 | 0.86 | 0.80 | 0.62 | 0.44 | 0.29 |
| Set 2 | 0.86 | 0.78 | 0.58 | 0.38 | 0.22 |
| Set 3 | 0.90 | 0.82 | 0.63 | 0.42 | 0.26 |
| Set 4 | 0.77 | 0.69 | 0.51 | 0.35 | 0.23 |
| Set 5 | 0.92 | 0.85 | 0.66 | 0.47 | 0.22 |
| Average | 0.86 | 0.79 | 0.60 | 0.41 | 0.24 |
| Cf. Step 1 (Across Books) | 0.96 | 0.91 | 0.74 | 0.58 | 0.42 |
| All Tokens | Set 1 Rest Ratio Accuracy |
Set 2 | Set 3 | Set 4 | Set 5 | |
| a-01 | 1,044,186 | 7.76% 0.97 |
13.50% 0.91 |
6.38% 1.00 |
8.81% 0.97 |
8.79% 0.82 |
| a-02 | 364,582 | 4.05% 1.00 |
17.00% 0.53 |
21.00% 0.94 |
24.43% 0.88 |
33.51% 0.83 |
| a-03 | 1,197,470 | 6.10% 1.00 |
3.34% 1.00 |
7.43% 0.93 |
13.62% 0.20 |
10.44% 0.99 |
| a-04 | 371,909 | 25.74% 0.83 |
27.00% 0.90 |
23.46% 0.91 |
4.94% 0.67 |
18.86% 0.97 |
| a-05 | 285,386 | 22.12% 0.95 |
39.89% 0.81 |
28.83% 0.85 |
3.55% 0.90 |
5.90% 0.94 |
| a-06 | 299,530 | 63.53% 0.64 |
8.56% 0.96 |
3.89% 0.83 |
2.93% 0.78 |
21.09% 0.83 |
| a-07 | 1,512,167 | 14.22% 0.98 |
4.96% 0.91 |
1.79% 0.70 |
11.90% 0.99 |
9.66% 0.99 |
| a-08 | 174,115 | 3.45% 0.00 |
63.19% 0.13 |
10.37% 0.67 |
22.99% 0.10 |
3.45% 0.00 |
| a-09 | 374,104 | 10.69% 0.45 |
*3.21% *0.42 |
12.57% 0.91 |
19.79% 0.24 |
24.06% 0.80 |
| a-10 | 514,131 | 19.26% 0.97 |
14.20% 0.79 |
13.42% 1.00 |
3.70% 0.53 |
13.81% 0.93 |
| a-11 | 715,093 | 11.33% 0.86 |
5.73% 0.78 |
6.43% 1.00 |
16.36% 0.74 |
9.93% 0.93 |
| a-12 | 241,111 | 14.52% 0.66 |
*8.71% *0.86 |
*6.23% *0.53 |
*14.53% *0.89 |
10.39% 0.32 |
| a-13 | 417,080 | 8.16% 0.62 |
16.78% 0.89 |
14.15% 0.90 |
16.54% 1.00 |
14.39% 0.92 |
| a-14 | 731,207 | 5.88% 1.00 |
4.10% 1.00 |
12.45% 1.00 |
15.73% 0.96 |
7.80% 1.00 |
| a-15 | 785,198 | 5.35% 0.24 |
*3.06% *0.96 |
10.57% 0.84 |
*2.93% *0.83 |
*3.18% *0.84 |
| a-16 | 1,099,103 | 12.46% 0.90 |
27.30% 0.96 |
7.01% 0.99 |
4.00% 0.93 |
11.46% 0.95 |
| a-17 | 614,032 | 4.40% 1.00 |
23.45% 0.86 |
37.46% 0.96 |
*3.26% *0.75 |
17.43% 1.00 |
| a-18 | 819,145 | 10.74% 0.98 |
5.98% 0.98 |
15.14% 0.96 |
7.33% 1.00 |
15.63% 0.95 |
| a-19 | 765,197 | 2.75% 0.86 |
12.81% 1.00 |
9.42% 0.99 |
9.15% 0.89 |
8.49% 0.97 |
| a-20 | 1,137,133 | 3.52% 1.00 |
6.16% 0.84 |
4.13% 0.98 |
2.11% 1.00 |
15.04% 0.99 |
| a-21 | 703,121 | 5.41% 1.00 |
12.38% 0.93 |
24.18% 0.55 |
**2.42% **0.65 |
8.25% 0.98 |
| a-22 | 618,089 | 6.15% 0.79 |
5.50% 1.00 |
5.34% 0.94 |
2.91% 0.56 |
17.64% 0.88 |
| a-23 | 683,108 | 9.66% 1.00 |
25.92% 0.98 |
9.37% 1.00 |
16.84% 1.00 |
9.08% 0.98 |
| Average (Per Author) | 672,443 | 12.05% 0.81 |
15.32% 0.84 |
12.65% 0.89 |
10.03% 0.76 |
12.97% 0.86 |
| Full Performance | 672,443 | 0.86 | 0.86 | 0.90 | 0.77 | 0.92 |
| Set 1 | Set 2 | Set 3 | Set 4 | Set 5 | |
| Train Ratio | -0.19474 | -0.01766 | -0.01495 | -0.18115 | 0.176758 |
| Full Token Count | 0.356384 | 0.390591 | 0.234502 | 0.259228 | 0.502111 |
| Test Token Count | 0.091817 | 0.217205 | 0.126774 | 0.099459 | 0.510302 |
| Train Token Count | 0.358298 | 0.361026 | 0.217488 | 0.268124 | 0.477041 |
Step 3. Books as Targets
- The greater the ratio of b / (a + b), the more consistent an author's style is.
- The greater the ratio of a / (b + c), the more inconsistent an author's style.
- The greater the ratio of (a + b) / (a + b + c), the more distinctive an author is.
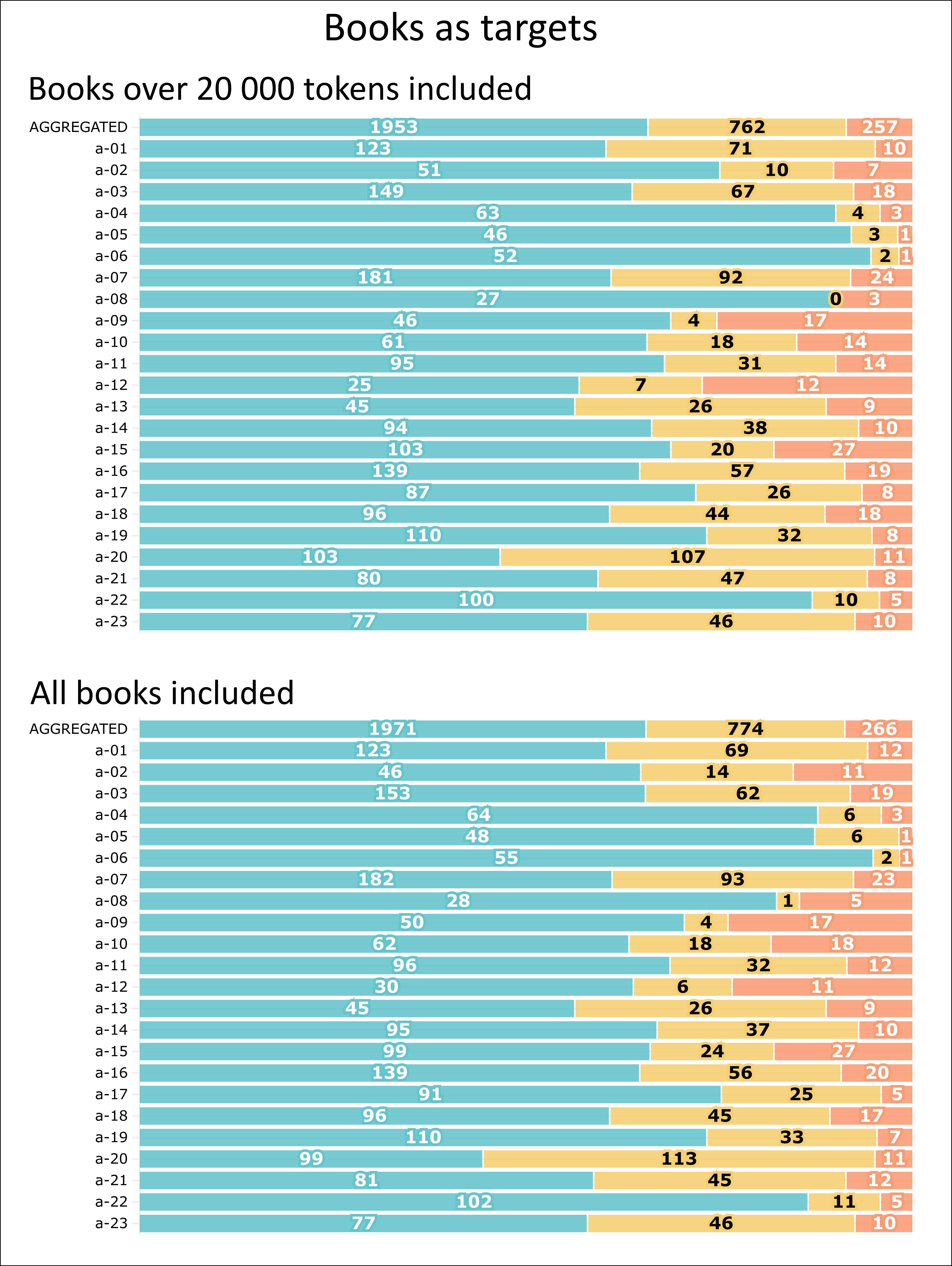
| Set 1 | Set 2 | Set 3 | Set 4 | Set 5 | |
| Attribution to Correct Book | 0.183381 | -0.23135 | -0.51682 | -0.26735 | 0.523796 |
| To Correct Author // Incorrect Book | 0.486218 | 0.443661 | 0.441649 | 0.416486 | 0.413774 |
| To Incorrect Author | -0.87451 | -0.15772 | 0.286852 | -0.27283 | -0.88701 |
| To Correct Author | 0.872354 | 0.154229 | -0.293 | 0.270222 | 0.885652 |
| Proportion of the Test Book Segments Attributed to the Correct Author but an Incorrect Book (Step 3) |
Author's Performance (Step 2) | |||||||||
| Set 1 | Set 2 | Set 3 | Set 4 | Set 5 | Set 1 | Set 2 | Set 3 | Set 4 | Set 5 | |
| a-01 | 0.54 | 0.03 | 0.17 | 0.00 | 0.17 | 0.98 | 0.91 | 1.00 | 0.97 | 0.82 |
| a-02 | 0.00 | 0.50 | 0.33 | 0.33 | 0.05 | 1.00 | 0.53 | 0.94 | 0.88 | 0.83 |
| a-03 | 1.00 | 0.06 | 0.00 | 0.00 | 0.27 | 1.00 | 1.00 | 0.93 | 0.20 | 0.99 |
| a-04 | 0.38 | 0.14 | 0.89 | 0.25 | 0.47 | 0.83 | 0.90 | 0.91 | 0.67 | 0.97 |
| a-05 | 0.00 | 0.16 | 0.14 | 0.50 | 0.38 | 0.95 | 0.81 | 0.85 | 0.90 | 0.94 |
| a-06 | 0.12 | 0.44 | 0.08 | 0.67 | 0.36 | 0.64 | 0.96 | 0.83 | 0.78 | 0.83 |
| a-07 | 0.80 | 0.11 | 0.02 | 0.50 | 0.10 | 0.98 | 0.91 | 0.70 | 0.99 | 0.99 |
| a-08 | 0.15 | 0.10 | 0.47 | 0.25 | 0.32 | 0.00 | 0.13 | 0.67 | 0.10 | 0.00 |
| a-09 | 0.00 | 0.00 | 0.12 | 0.25 | 0.40 | 0.45 | 0.42 | 0.91 | 0.24 | 0.80 |
| a-10 | 0.25 | 0,33 | 0,33 | 0,00 | 0,09 | 0,97 | 0,79 | 1,00 | 0,53 | 0,93 |
| a-11 | 0.17 | 0.21 | 0.18 | 0.23 | 0.50 | 0.86 | 0.78 | 1.00 | 0.74 | 0.93 |
| a-12 | 0.43 | 0.25 | 0.00 | 0.00 | 0.00 | 0.66 | 0.86 | 0.53 | 0.89 | 0.32 |
| a-13 | 0.31 | 0.38 | 1.00 | 0.17 | 0.64 | 0.62 | 0.89 | 0.90 | 1.00 | 0.92 |
| a-14 | 0.16 | 0.21 | 0.08 | 0.00 | 0.00 | 1.00 | 1.00 | 1.00 | 0.96 | 1.00 |
| a-15 | 0.00 | 0.00 | 0.11 | 0.00 | 0.00 | 0.24 | 0.96 | 0.84 | 0.83 | 0.84 |
| a-16 | 0.00 | 0.00 | 0.33 | 0.00 | 0.00 | 0.90 | 0.96 | 0.99 | 0.93 | 0.95 |
| a-17 | 0.23 | 0.26 | 0.00 | 0.47 | 0.51 | 1.00 | 0.86 | 0.96 | 0.75 | 1.00 |
| a-18 | 0.00 | 0.40 | 0.00 | 0.00 | 0.00 | 0.98 | 0.98 | 0.96 | 1.00 | 0.95 |
| a-19 | 0.17 | 0.00 | 0.06 | 1.00 | 0.33 | 0.86 | 1.00 | 0.99 | 0.89 | 0.97 |
| a-20 | 0.11 | 0.05 | 0.06 | 0.00 | 0.14 | 1.00 | 0.84 | 0.98 | 1.00 | 0.99 |
| a-21 | 0.43 | 0.63 | 0.53 | 0.06 | 0.12 | 1.00 | 0.93 | 0.55 | 0.65 | 0.98 |
| a-22 | 1.00 | 0.08 | 0.33 | 0.06 | 0.17 | 0.79 | 1.00 | 0.94 | 0.56 | 0.88 |
| a-23 | 0.13 | 0.21 | 0.69 | 0.67 | 0.17 | 1.00 | 0.98 | 1.00 | 1.00 | 0.98 |
Conclusion
Acknowledgements
Appendix
| Author | Title | Genre | Book ID in Dataset | Token Count | Set in Which Used as Test Book (Experiment Step 2) |
| A. Stašek | Nedokončený obraz | Prose | a-01.b-01 | 91,746 | Set 5 |
| A. Stašek | Otřelá kolečka | Prose | a-01.b-02 | 83,978 | |
| A. Stašek | Vzpomínky | Prose | a-01.b-03 | 155,266 | |
| A. Stašek | Bohatství | Prose | a-01.b-04 | 54,474 | |
| A. Stašek | Bratři | Prose | a-01.b-05 | 66,637 | Set 3 |
| A. Stašek | Blouznivci našich hor | Prose | a-01.b-07 | 141,011 | Set 2 |
| A. Stašek | O ševci Matoušovi a jeho přátelích | Prose | a-01.b-08 | 83,005 | |
| A. Stašek | Na rozhraní | Prose | a-01.b-09 | 106,018 | |
| A. Stašek | V temných vírech (1) | Prose | a-01.b-11 | 89,013 | |
| A. Stašek | V temných vírech (3) | Prose | a-01.b-12 | 92,030 | Set 4 |
| A. Stašek | Stíny minulosti | Prose | a-01.b-13 | 81,008 | Set 1 |
| A. Stašek Full Tokens Count: 1,044,186 | |||||
| J. Neruda | Arabesky | Prose | a-02.b-01 | 69,981 | Set 2 |
| J. Neruda | Trhani | Prose | a-02.b-02 | 14,772 | Set 1 |
| J. Neruda | Menší cesty | Prose | a-02.b-03 | 76,567 | Set 3 |
| J. Neruda | Povídky malostranské | Prose | a-02.b-04 | 89,079 | Set 4 |
| J. Neruda | Studie, krátké a kratší | Prose | a-02.b-05 | 122,183 | Set 5 |
| J. Neruda Full Tokens Count: 364,582 | |||||
| J. Arbes | Ethiopská lilie | Prose | a-03.b-01 | 79,873 | |
| J. Arbes | Kandidáti existence | Prose | a-03.b-02 | 81,821 | |
| J. Arbes | Poslední dnové lidstva | Prose | a-03.b-03 | 88,181 | |
| J. Arbes | Persekuce lidu českého v letech 1869-1873 | Prose | a-03.b-04 | 163,125 | Set 4 |
| J. Arbes | Svatý Xaverius | Prose | a-03.b-05 | 28,370 | |
| J. Arbes | Elegie a idyly | Prose | a-03.b-06 | 159,003 | |
| J. Arbes | Moderní upíři | Prose | a-03.b-09 | 93,009 | |
| J. Arbes | Anděl míru | Prose | a-03.b-10 | 106,028 | |
| J. Arbes | Sivooký démon | Prose | a-03.b-11 | 89,031 | Set 3 |
| J. Arbes | Štrajchpudlíci | Prose | a-03.b-12 | 125,003 | Set 5 |
| J. Arbes | Akrobati | Prose | a-03.b-13 | 40,001 | Set 2 |
| J. Arbes | Divotvorci tónů | Prose | a-03.b-15 | 73,023 | Set 1 |
| J. Arbes | Z víru života | Prose | a-03.b-16 | 71,002 | |
| J. Arbes Full Tokens Count: 1,197,470 | |||||
| K. Klostermann | Ze světa lesních samot | Prose | a-04.b-01 | 87,234 | Set 3 |
| K. Klostermann | Za štěstím | Prose | a-04.b-02 | 95,745 | Set 1 |
| K. Klostermann | Domek v Polední ulici | Prose | a-04.b-03 | 100,419 | Set 2 |
| K. Klostermann | Vypovězen | Prose | a-04.b-04 | 70,129 | Set 5 |
| K. Klostermann | Kulturní naléhavost | Prose | a-04.b-05 | 18,382 | Set 4 |
| K. Klostermann Full Tokens Count: 371,909 | |||||
| F. X. Šalda | Boje o zítřek | Prose | a-05.b-01 | 63,141 | Set 1 |
| F. X. Šalda | Moderní literatura česká | Prose | a-05.b-02 | 16,843 | Set 5 |
| F. X. Šalda | Duše a dílo | Prose | a-05.b-03 | 82,283 | Set 3 |
| F. X. Šalda | Umění a náboženství | Prose | a-05.b-04 | 10,141 | Set 4 |
| F. X. Šalda | Juvenilie: stati, články a recense z let 1891-1899 (1) | Prose | a-05.b-05 | 112,978 | Set 2 |
| F. X. Šalda Full Tokens Count: 285,386 | |||||
| T. G. Masaryk | Blaise Pascal, jeho život a filosofie | Prose | a-06.b-01 | 11,662 | Set 3 |
| T. G. Masaryk | O studiu děl básnických | Prose | a-06.b-02 | 8,786 | Set 4 |
| T. G. Masaryk | Česká otázka: snahy a tužby národního obrození | Prose | a-06.b-03 | 63,168 | Set 5 |
| T. G. Masaryk | Otázka sociální: základy marxismu sociologické a filosofické | Prose | a-06.b-04 | 190,279 | Set 1 |
| T. G. Masaryk | Jan Hus: naše obrození a naše reformace | Prose | a-06.b-05 | 25,635 | Set 2 |
| T. G. Masaryk Full Tokens Count: 299,530 | |||||
| A. Jirásek | Na Chlumku | Prose | a-07.b-02 | 8,016 | |
| A. Jirásek | Na dvoře vévodském | Prose | a-07.b-04 | 81,005 | |
| A. Jirásek | Psohlavci | Prose | a-07.b-05 | 88,007 | |
| A. Jirásek | Zahořanský hon a jiné povídky | Prose | a-07.b-06 | 75,002 | Set 2 |
| A. Jirásek | Skály | Prose | a-07.b-07 | 90,021 | |
| A. Jirásek | Temno | Prose | a-07.b-08 | 215,002 | Set 1 |
| A. Jirásek | Bratrstvo (1): Bitva u Lučence | Prose | a-07.b-09 | 146,023 | Set 5 |
| A. Jirásek | Bratrstvo (2): Mária | Prose | a-07.b-10 | 158,003 | |
| A. Jirásek | Bratrstvo (3): Žebráci | Prose | a-07.b-11 | 180,009 | Set 4 |
| A. Jirásek | F.L. Věk | Prose | a-07.b-12 | 152,028 | |
| A. Jirásek | Maryla | Prose | a-07.b-13 | 53,035 | |
| A. Jirásek | Husitský král (2) | Prose | a-07.b-13 | 115,006 | |
| A. Jirásek | Lucerna | Drama | a-07.b-14 | 27,001 | Set 3 |
| A. Jirásek | Mezi proudy (1) | Prose | a-07.b-16 | 124,009 | |
| A. Jirásek Full Tokens Count: 1,512,167 | |||||
| Č. Slepánek | Srbsko od prvého povstání 1804 do dnešní doby | Prose | a-08.b-01 | 110,022 | Set 2 |
| Č. Slepánek | Črty z Ruska a odjinud | Prose | a-08.b-02 | 40,032 | Set 4 |
| Č. Slepánek | Svědomí Lidových novin, čili, Jak bylo po léta v českém tisku štváno lživě proti mně |
Prose | a-08.b-03 | 6,004 | Set, Set 5 |
| Č. Slepánek | Dělnické hnutí v Rusku | Prose | a-08.b-04 | 18,057 | Set 3 |
| Č. Slepánek Full Tokens Count: 174,115 | |||||
| E. Krásnohorská | Svéhlavička | Prose | a-09.b-01 | 74,030 | Set 4 |
| E. Krásnohorská | Celínka | Prose | a-09.b-02 | 90,003 | Set 5 |
| E. Krásnohorská | Pohádky Elišky Krásnohorské | Prose | a-09.b-03 | 40,004 | Set 1 |
| E. Krásnohorská | Srdcem i skutkem | Prose | a-09.b-04 | 24,032 | |
| E. Krásnohorská | Do proudu žití | Prose | a-09.b-06 | 47,013 | Set 3 |
| E. Krásnohorská | Medvěd a víla | Drama | a-09.b-08 | 12,002 | Set 2 |
| E. Krásnohorská | Čertova stěna | Drama | a-09.b-10 | 14,003 | |
| E. Krásnohorská | Trojí máj | Prose | a-09.b-11 | 73,017 | |
| E. Krásnohorská Full Tokens Count: 374,104 | |||||
| F. Herites | Amanita | Prose | a-10.b-01 | 73,015 | Set 2 |
| F. Herites | Tajemství strýce Josefa | Prose | a-10.b-02 | 52,010 | |
| F. Herites | Maloměstské humoresky | Prose | a-10.b-03 | 69,021 | Set 3 |
| F. Herites | Tři cesty | Prose | a-10.b-04 | 28,010 | |
| F. Herites | Bez chleba | Prose | a-10.b-06 | 92,013 | |
| F. Herites | Všední zjevy | Prose | a-10.b-07 | 99,011 | Set 1 |
| F. Herites | Bůh v lidu | Prose | a-10.b-09 | 11,022 | |
| F. Herites | Vodňanské vzpomínky | Prose | a-10.b-10 | 19,009 | Set 4 |
| F. Herites | Sebrané spisy Fr. Heritesa | Prose | a-10.b-11 | 71,020 | Set 5 |
| F. Herites Full Tokens Count: 514,131 | |||||
| I. Olbracht | Nikola Šuhaj loupežník | Prose | a-11.b-01 | 67,028 | |
| I. Olbracht | Anna proletářka | Prose | a-11.b-02 | 81,016 | Set 1 |
| I. Olbracht | Karavany v noci | Prose | a-11.b-03 | 99,007 | |
| I. Olbracht | Žalář nejtemnější | Prose | a-11.b-04 | 41,002 | Set 2 |
| I. Olbracht | Dobyvatel | Prose | a-11.b-05 | 193,020 | |
| I. Olbracht | O smutných očích Hany Karadžičové | Prose | a-11.b-06 | 46,004 | Set 3 |
| I. Olbracht | O zlých samotářích | Prose | a-11.b-07 | 117,007 | Set 4 |
| I. Olbracht | Golet v údolí | Prose | a-11.b-08 | 71,009 | Set 5 |
| I. Olbracht Full Tokens Count: 715,093 | |||||
| J. Vrchlický | Povídky ironické a sentimentální | Prose | a-12.b-01 | 25,041 | Set 5 |
| J. Vrchlický | Barevné střepy | Prose | a-12.b-03 | 26,001 | |
| J. Vrchlický | Nové barevné střepy | Prose | a-12.b-05 | 35,002 | Set 1 |
| J. Vrchlický | Loutky | Prose | a-12.b-06 | 84,012 | |
| J. Vrchlický | Noc na Karlštejně | Drama | a-12.b-07 | 21,002 | Set 2 |
| J. Vrchlický | Drahomíra | Drama | a-12.b-08 | 15,010 | Set 3 |
| J. Vrchlický | Knížata | Drama | a-12.b-09 | 35,043 | Set 4 |
| J. Vrchlický Full Tokens Count: 241,111 | |||||
| J.S. Machar | Nemocnice | Prose | a-13.b-01 | 34,020 | Set 1 |
| J.S. Machar | Pod sluncem italským | Prose | a-13.b-01 | 57,027 | |
| J.S. Machar | Třicet roků | Prose | a-13.b-03 | 60,014 | Set 5 |
| J.S. Machar | Vídeň | Prose | a-13.b-04 | 68,009 | |
| J.S. Machar | Řím | Prose | a-13.b-05 | 69,005 | Set 4 |
| J.S. Machar | Vzpomíná se… | Prose | a-13.b-06 | 70,002 | Set 2 |
| J.S. Machar | Kriminál | Prose | a-13.b-07 | 59,003 | Set 3 |
| J.S. Machar Full Tokens Count: 417,080 | |||||
| J. Zeyer | Ondřej Černyšev | Prose | a-14.b-01 | 91,005 | |
| J. Zeyer | Román o věrném přátelství Amise a Amila | Prose | a-14.b-02 | 91,036 | |
| J. Zeyer | Báje Šošany | Prose | a-14.b-03 | 43,010 | Set 1 |
| J. Zeyer | Fantastické povídky | Prose | a-14.b-04 | 82,017 | |
| J. Zeyer | Dobrodružství Madrány | Prose | a-14.b-05 | 57,017 | Set 5 |
| J. Zeyer | Gompači a Komurasaki | Prose | a-14.b-06 | 38,011 | |
| J. Zeyer | Rokoko: Sestra Paskalina | Prose | a-14.b-07 | 30,001 | Set 2 |
| J. Zeyer | Jan Maria Plojhar | Prose | a-14.b-08 | 115,022 | Set 4 |
| J. Zeyer | Stratonika a jiné povídky | Prose | a-14.b-09 | 91,026 | Set 3 |
| J. Zeyer | Maeldunova výprava a jiné povídky | Prose | a-14.b-10 | 34,046 | |
| J. Zeyer | Tři legendy o krucifixu | Prose | a-14.b-11 | 59,016 | |
| J. Zeyer Full Tokens Count: 731,207 | |||||
| K. Čapek | Válka s mloky | Prose | a-15.b-01 | 83,021 | Set 3 |
| K. Čapek | Nůše pohádek (3) | Prose | a-15.b-02 | 42,020 | Set 1 |
| K. Čapek | Povídky z jedné kapsy | Prose | a-15.b-03 | 61,027 | |
| K. Čapek | Povídky z druhé kapsy | Prose | a-15.b-04 | 52,019 | |
| K. Čapek | Věc Makropulos | Drama | a-15.b-05 | 22,007 | |
| K. Čapek | Devatero pohádek | Prose | a-15.b-06 | 56,004 | |
| K. Čapek | Ze života hmyzu | Drama | a-15.b-07 | 22,004 | |
| K. Čapek | Měl jsem psa a kočku | Prose | a-15.b-08 | 25,021 | |
| K. Čapek | Matka | Drama | a-15.b-09 | 24,005 | Set 2 |
| K. Čapek | Zahradníkův rok | Prose | a-15.b-10 | 25,007 | |
| K. Čapek | Povětroň | Prose | a-15.b-11 | 52,003 | |
| K. Čapek | Jak se co dělá | Prose | a-15.b-12 | 34,004 | |
| K. Čapek | Loupežník | Drama | a-15.b-13 | 23,003 | Set 4 |
| K. Čapek | Cesta na sever | Prose | a-15.b-14 | 33,003 | |
| K. Čapek | Hovory s T.G. Masarykem | Prose | a-15.b-15 | 24,013 | |
| K. Čapek | Továrna na Absolutno, Krakatit | Prose | a-15.b-16 | 147,012 | |
| K. Čapek | Bílá nemoc | Drama | a-15.b-17 | 25,003 | Set 5 |
| K. Čapek | Boží muka | Prose | a-15.b-18 | 35,022 | |
| K. Čapek Full Tokens Count: 785,198 | |||||
| K. Nový | Plamen a vítr | Prose | a-16.b-01 | 174,008 | |
| K. Nový | Železný kruh | Prose | a-16.b-02 | 300,021 | Set 2 |
| K. Nový | Peníze | Prose | a-16.b-03 | 77,003 | Set 3 |
| K. Nový | Chceme žít | Prose | a-16.b-04 | 58,001 | |
| K. Nový | Na rozcestí | Prose | a-16.b-05 | 126,002 | Set 5 |
| K. Nový | Atentát | Prose | a-16.b-06 | 113,009 | |
| K. Nový | Rytíři a lapkové | Prose | a-16.b-07 | 137,001 | Set 1 |
| K. Nový | Balada o českém vojáku | Prose | a-16.b-08 | 47,054 | |
| K. Nový | Rybaříci na Modré zátoce | Prose | a-16.b-09 | 23,001 | |
| K. Nový | Potulný lovec | Prose | a-16.b-10 | 44,003 | Set 4 |
| K. Nový Full Tokens Count: 1,099,103 | |||||
| K. Sabina | Synové světla | Prose | a-17.b-01 | 230,005 | Set 3 |
| K. Sabina | Hrobník | Prose | a-17.b-02 | 27,001 | Set 1 |
| K. Sabina | Morana čili Svět a jeho nicoty | Prose | a-17.b-03 | 144,003 | Set 2 |
| K. Sabina | Oživené hroby | Prose | a-17.b-04 | 86,020 | |
| K. Sabina | Černá růže | Drama | a-17.b-05 | 20,002 | Set 4 |
| K. Sabina | Blouznění | Prose | a-17.b-07 | 107,001 | Set 5 |
| K. Sabina Full Tokens Count: 614,032 | |||||
| K.V. Rais | Zapadlí vlastenci | Prose | a-18.b-01 | 125,026 | |
| K.V. Rais | Maloměstské humorky | Prose | a-18.b-02 | 128,004 | Set 5 |
| K.V. Rais | Kalibův zločin | Prose | a-18.b-03 | 65,028 | |
| K.V. Rais | Paničkou: obraz z podhoří | Prose | a-18.b-04 | 60,008 | Set 4 |
| K.V. Rais | Povídky o českých umělcích | Prose | a-18.b-05 | 22,004 | |
| K.V. Rais | Povídky ze starých hradů | Prose | a-18.b-07 | 32,012 | |
| K.V. Rais | Výminkáři | Prose | a-18.b-09 | 48,001 | |
| K.V. Rais | Stehle: podhorský obraz | Prose | a-18.b-10 | 124,023 | Set 3 |
| K.V. Rais | Z rodné chaloupky | Prose | a-18.b-11 | 23,008 | |
| K.V. Rais | Skleník | Prose | a-18.b-12 | 33,004 | |
| K.V. Rais | Pantáta Bezoušek | Prose | a-18.b-13 | 88,006 | Set 1 |
| K.V. Rais | Ze srdce k srdcím | Prose | a-18.b-14 | 22,002 | |
| K.V. Rais | Horské kořeny | Prose | a-18.b-15 | 49,019 | Set 2 |
| K.V. Rais Full Tokens Count: 819,145 | |||||
| K. Světlá | Černý Petříček | Prose | a-19.b-01 | 35,025 | |
| K. Světlá | Poslední poustevnice | Prose | a-19.b-02 | 52,001 | |
| K. Světlá | Z let probuzení | Prose | a-19.b-03 | 70,037 | Set 4 |
| K. Světlá | Na úsvitě | Prose | a-19.b-04 | 108,002 | |
| K. Světlá | Kantůrčice | Prose | a-19.b-05 | 65,001 | Set 5 |
| K. Světlá | O krejčíkově Anežce | Prose | a-19.b-06 | 21,011 | Set 1 |
| K. Světlá | Časové ohlasy | Prose | a-19.b-07 | 72,044 | Set 3 |
| K. Světlá | Kříž u potoka | Prose | a-19.b-08 | 102,025 | |
| K. Světlá | Vesnický román | Prose | a-19.b-09 | 77,015 | |
| K. Světlá | Frantina | Prose | a-19.b-10 | 65,001 | |
| K. Světlá | Nemodlenec | Prose | a-19.b-11 | 98,035 | Set 2 |
| K. Světlá Full Tokens Count: 765,197 | |||||
| S.K. Neumann | Československá cesta | Prose | a-20.b-04 | 32,009 | |
| S.K. Neumann | Vzpomínky (1) | Prose | a-20.b-05 | 40,006 | Set 1 |
| S.K. Neumann | Francouzská revoluce (1) | Prose | a-20.b-06 | 158,001 | |
| S.K. Neumann | Francouzská revoluce (2) | Prose | a-20.b-07 | 171,012 | Set 5 |
| S.K. Neumann | Francouzská revoluce (3) | Prose | a-20.b-08 | 157,013 | |
| S.K. Neumann | Ať žije život | Prose | a-20.b-09 | 42,022 | |
| S.K. Neumann | Jelec | Prose | a-20.b-10 | 11,008 | |
| S.K. Neumann | Enciány s Popa Ivana | Prose | a-20.b-11 | 24,012 | Set 4 |
| S.K. Neumann | O umění | Prose | a-20.b-12 | 217,009 | |
| S.K. Neumann | Paměti a drobné prózy | Prose | a-20.b-13 | 47,018 | Set 3 |
| S.K. Neumann | Zlatý oblak | Prose | a-20.b-14 | 70,018 | Set 2 |
| S.K. Neumann | Konfese a konfrontace (2) | Prose | a-20.b-15 | 168,005 | |
| S.K. Neumann Full Tokens Count: 1,137,133 | |||||
| V. Hálek | Na vejminku | Prose | a-21.b-01 | 46,020 | |
| V. Hálek | Pod pustým kopcem | Prose | a-21.b-03 | 58,023 | Set 5 |
| V. Hálek | Mejrima a Husejn | Poetry | a-21.b-04 | 17,009 | Set 4 |
| V. Hálek | Král Rudolf | Drama | a-21.b-06 | 25,012 | |
| V. Hálek | Komediant | Prose | a-21.b-08 | 87,019 | Set 2 |
| V. Hálek | Na statku a v chaloupce | Prose | a-21.b-09 | 38,004 | Set 1 |
| V. Hálek | Kresby křídou i tuší | Prose | a-21.b-10 | 146,014 | |
| V. Hálek | Povídky I | Prose | a-21.b-11 | 116,005 | |
| V. Hálek | Fejetony | Prose | a-21.b-12 | 170,015 | Set 3 |
| V. Hálek Full Tokens Count: 703,121 | |||||
| V. Vančura | Obrazy z dějin národa českého | Prose | a-22.b-01 | 141,011 | |
| V. Vančura | Kubula a Kuba Kubikula | Prose | a-22.b-02 | 18,016 | Set 4 |
| V. Vančura | Pole orná a válečná | Prose | a-22.b-03 | 46,002 | |
| V. Vančura | Amazonský proud; Dlouhý, Široký, Bystrozraký | Prose | a-22.b-04 | 38,002 | Set 1 |
| V. Vančura | Pekař Jan Marhoul | Prose | a-22.b-05 | 34,015 | Set 2 |
| V. Vančura | Poslední soud | Prose | a-22.b-06 | 37,004 | |
| V. Vančura | Luk královny Dorotky | Prose | a-22.b-07 | 33,001 | Set 3 |
| V. Vančura | Tři řeky | Prose | a-22.b-08 | 93,014 | |
| V. Vančura | Rozmarné léto | Prose | a-22.b-10 | 23,011 | |
| V. Vančura | Markéta Lazarová | Prose | a-22.b-11 | 46,008 | |
| V. Vančura | Rodina Horvatova | Prose | a-22.b-12 | 109,005 | Set 5 |
| V. Vančura Full Tokens Count: 618,089 | |||||
| Z. Winter | Nezbedný bakalář a jiné rakovnické obrázky | Prose | a-23.b-01 | 115,003 | Set 4 |
| Z. Winter | Ze staré Prahy | Prose | a-23.b-02 | 62,005 | Set 5 |
| Z. Winter | Krátký jeho svět a jiné pražské obrázky | Prose | a-23.b-04 | 102,009 | |
| Z. Winter | Staré listy | Prose | a-23.b-05 | 66,007 | Set 1 |
| Z. Winter | Rozina sebranec | Prose | a-23.b-06 | 64,019 | Set 3 |
| Z. Winter | Bouře a přeháňka | Prose | a-23.b-07 | 69,001 | |
| Z. Winter | Panečnice | Prose | a-23.b-08 | 28,025 | |
| Z. Winter | Mistr Kampanus | Prose | a-23.b-09 | 177,039 | Set 2 |
| Z. Winter Full Tokens Count: 683,108 | |||||
Notes
Works Cited

Comments: dhqinfo@digitalhumanities.org
Published by: The Alliance of Digital Humanities Organizations and The Association for Computers and the Humanities
Affiliated with: Digital Scholarship in the Humanities
DHQ has been made possible in part by the National Endowment for the Humanities.
Copyright © 2005 -

Unless otherwise noted, the DHQ web site and all DHQ published content are published under a Creative Commons Attribution-NoDerivatives 4.0 International License. Individual articles may carry a more permissive license, as described in the footer for the individual article, and in the article’s metadata.
