Notes
[1] One
might just as easily scan this essay’s bibliography for other examples, but
among them: McGrath et al. (2018); Ross and O’Sullivan (2016); Jeffrey
Drouin, “Close- And Distant-Reading Modernism: Network
Analysis, Text Mining, and Teaching The Little
Review” (2014); Sean Weidman and James O’Sullivan,
“The limits of distinctive words: Re-evaluating
literature’s gender marker debate” (2018).
[2] In fact, David James and Urmila
Seshagiri recently bolstered that organizing logic, arguing how “[r]etaining modernism across deep time can dehistoricize
it as a movement but repoliticize it as a global practice, a practice
that serves instrumental ends in the context of cultural circumstances
with which modernist writing has yet to be associated”
[James and Seshagiri 2014, 90]. [3] Peter B.
Hirtle of Cornell University Library hosts a “Copyright Information
Center” page that’s kept updated for the complex copyright terms of
public domain in the US. See Hirtle’s article, “When Is
1923 Going to Arrive and Other Complications of the U.S. Public
Domain” (2012), for an explanation of why published works after
1923 have remained out of the public domain. As of 1 January, 2019, a
variety of US-published works from 1923 have entered the public domain, and
each subsequent year will see a correlative year’s worth of once-copyrighted
works do the same. An exception must be made, however, for Matthew Huculak
and Claire Battershill’s Open Modernisms project, which as of this writing represents an online archive of
nearly 500 modernist works in various genres (see also Claire Battershill et
al.’s Making The Modernist Archives Publishing
Project (2017)). Otherwise, in the past half-decade, the
HathiTrust Research Center is the only digital collection that offers access
to sets of post-1923 texts for scholars doing computational research, and it
comes with several restrictions. [4] We should clarify that our use of
the term style diverges from other variants used by modernist
literary scholars (e.g. Rebecca Walkowitz), which tend to invoke the term
loosely and synonymously with form, insofar as each denotes a
literary pattern traceable through (for example) close reading. In the realm
of stylometry, a notion of literary style is technical and tied to word use,
and the term stands in for the aggregate of a set of formal, observable
textual features. Our underlying assumption is that word preference can be
measured by first counting words, both within individual texts and
comparatively within a group of texts, and that those counts will be unique
along different axes (e.g. different from writer to writer; genre to genre;
etc.). By extension, those counts tell us something about the content and
style of a text/writer relative to other texts. For a
terrific account of the interdisciplinary use of the term among textual
studies fields, see Herrmann et al. (2015).
[5] And this line probably owes a great
critical debt to those recent critiques of computational literary study
proffered by Katherine Bode (2017) and Nan Z. Da (2019) — though, our study tends toward slightly
more optimism: in the end, while we suggest stylometric critique needs to be
wary of drawing firm conclusions about modern life via modernist fiction, we
nevertheless think stylometry has much to offer the study of
modernism.
[6] In this we uphold Losh
et al.’s call for a “genuinely messy, heterogeneous, and
contentious pluralism” as the underlying ethic of our digital
methods, a critical approach that may also productively join — or
productively digitize — the political investments of our data, its
structures, and our own methods of analyzing and contextualizing modernism
[Losh et al. 2016, 98]. [7] For Bode, this manner of viewing texts often ends in “dismiss[ing] the documentary record’s multiplicity”
[Bode 2017, 92]. [8] Burrows popularized the field of literary
computational stylistics with his book, and his was one of the first to
recognize the scales of semantic meaning within patterns of function word
usage; although he doesn’t really study gender in Austen explicitly,
literary stylometrists continue to build on his principles.
[9] Refer also
to Jan Rybicki (2016) and Mark Algee-Hewitt (2015) for two more essays
utilizing similar methods to reach similar ends.
[10] Although not limited to
modern literature, this claim is made even clearer and more forcefully by
Earhart et al. (2020) in their recent account of gender and scholarly
citational practices.
[11] In fact, aside from Lavin’s essay
about modern reviewing, we can think of only two studies that employ some
form of quantitative formalist approach to modernist work and even vaguely
relate it to gender. Stephen Ramsay’s Reading Machines
opens with a chapter that analyzes Virginia Woolf’s The Waves in relation to its feminist criticism,
and David Hoover’s later “Argument, Evidence, and the
Limits of Digital Literary Studies” positions itself directly
opposite Ramsay’s earlier study by rereading The Waves
with different computational methods [Ramsay 2011]
[Hoover 2016]. Among other thematically adjacent studies: see
González et al. (2019) for an account of gender, stylometry, and
modernismo; and outside of modernism’s computational
literary study, see Churchill et al. (2018) regarding their work on Mina
Loy, style, and UX design and their interactive digital project of feminist
modernist design (which builds on D’Ignazio and Klein’s (2016) foundational
feminist visualizations essay). [12] Among other, longer accounts, Katherine Bode’s A World of Fiction: Digital Collections and the Future of
Literary History (2018) and Ted Underwood’s Distant Horizons: Digital Evidence and Literary Change (2019)
also each contain a section on gender and (mainly) 19th-century
literature.
[13] Richard Jean So contends similarly
that errors help us realign models to the unseen peripheries of data, and
echoes Brown and Mandell’s sentiment through the oft-quoted adage of famed
statistician George E.P. Box: “All models are wrong, but
some are useful”
[So 2017, 669]. Andrew Piper makes a comparable remark
when he considers that “[m]odeling puts computation not
on the outside of what is known but as part of the process
itself,” a reflexive process toward the contingency of knowledge
he terms the New Recursivity
[Piper 2016]. Piper also argues convincingly that every aspect
of the modeling process, especially those required by its implementation on
particular data selections, necessitates reduction — and that in its
ubiquity reductiveness can actually be generative [Piper 2017, 654]. [14] A case in point about this own study, which began many years ago
(and before the resources of HathiTrust were widely accessible): our corpus
of women authors is almost entirely hand-scanned and OCRed, because the
continued gender inequality of the literary marketplace, which Piper and So
have studied, also occupies the realm of text digitization. Riddell and
Bassett (2020) have measured this gender inequity, finding (in a corpus from
the 1830s to the present day) that novels by women have been digitized at
substantially lower rates than novels by men. For a more detailed account on
the many levels of infrastructural relevance women writers require to be
studied by digital methods, see Laura Mandell’s “Gendering Digital Literary History: What Counts for Digital
Humanities” (2016), then see Roopika Risam’s “Navigating the Global Digital Humanities: Insights from Black
Feminism” (2016) for a take on the complexity of foregrounding
racial and multicultural diversity while doing so.
[15]
While our analyses included the default standardization of all texts with
z-scores (such that variations in a term like “novel-length” no longer
come into play) and might have analyzed works of intentionally disparate
lengths, we wanted to ensure our corpus maintained a cohesive genre; the
phrase “novel-length fiction” is one common compromise.
[16] Give or take a
year or two — we cheated, for example, to fit in Conrad’s Heart of Darkness (1899).
[17] For the sake of space, the full text list isn’t included here,
but it is of course available upon request.
[18] We would be remiss if we didn’t mention Evans and
Wilkens (2018) as a recent computational study that adds to the mounting
rationales against such a canon. The authors argue convincingly
that, when modeling British fiction as a whole (and not just its canonical
works), the modernist period produced narrative attentions to international
locales that greatly outnumbered national ones. Most modern British fiction,
that is, spent more time discussing international milieus than not, which
reaffirms concerns about the representative validity of something like an
orthodox canon of British modern fiction.
[19] Hence conventional
caveats apply: our corpus may indeed produce a narrative driven by
ease-of-access or proximity over actual representativeness; a larger, more
diverse, more global (in short, a “different”) corpus may have provided
different results; and the claims we hope to make about gender and modernist
style thus can’t reliably be extrapolated to modernist literature’s other
flavors without further analysis. We admit this is a substantial, but so far
largely unavoidable, limitation of studying the literary canon of a period
still heavily under material and economic wraps. It’s reason, too, to be
skeptical of the midrange scale of our study, which ends by looking at one
text and one author and is thus not nearly as macroanalytic as most
stylometric studies of literature. (It should be said that Marks
Algee-Hewitt and McGurl explore this and other rationales of corpus-making
in the Stanford Literary Lab’s Pamphlet 8,
“Between Canon and Corpus: Six Perspectives on
20th-Century Novels,” 2-8.)
[20] Though, there are indeed more nuanced measures of
stylistic distance that weight function and content words in different ways.
Regardless, this general technique is often called the bag of
words approach, and while it is popular in text analysis it also
has its drawbacks. Its most basic model treats every word in each text in
the same way, regardless of that word’s (a) syntactic or semantic contexts
and (b) relation to the narrative or literary forms — thus, every novel
merely becomes a countable bag of words. The approach makes measuring
stylistic difference simple and effective, but in doing so it erases the
context of all other literary elements in a work, which makes “reading”
the resulting wordlists a precarious task. Take the exchange in Orlando between the newly acquainted Shelmerdine and
Orlando as a brief example — and take first a jumbled approximation of what
our machine sees, in the spirit of big-data experimentalism:
“a” (2), “cried” (2), “[a]re” (2), “you” (2),
“he” (1), “man” (1), “Orlando” (1), “she” (1),
“Shel” (1), “woman” (1). What’s happened in this sequence, now
that we’ve merely counted words and glossed over all context? Maybe a man
and a woman were crying together, but who really knows? The flattening
perils of decontextualized computational analysis are indeed laid bare. Now,
here’s the moment as it appears in the actual narrative: “‘You’re a woman, Shel!’ she cried. ‘You’re a man,
Orlando!’ he cried.” Even in a short, two-sentence example,
Woolf’s tremendous gender-/word-play and its meaning for the speakers, who
have fallen for one another (and soon marry) in part because of their gender
non-conforming androgyny, is entirely lost if one merely rushed to count
one’s computational chickens.
[21] Although we don’t
engage with it here, Underwood and So have raised a few conceptual concerns
with this approach, asking recently whether statistical distance and
stylistic distance are comparable measures of relation at all [Underwood and So 2021]. [22] A basic note
may be necessary regarding the difference between supervised and
unsupervised machine learning techniques (though, there are other techniques
that borrow from both types). Supervised techniques tend to require the
input of pre-classified data to “learn from,” so that the algorithm can
track and then predict future patterns from similarly classified data (e.g.
one might train a road sign classification machine on thousands of different
stop sign images, and then feed it other random images and ask it to output
whether or not they feature stop signs). Unsupervised machine learning,
conversely, tends to model the distribution or configuration of input data
(e.g. providing a large, unsorted data set of road sign images and some
metric of sorting them might provide correlations, groupings, or trends to
help identify or separate those images). For further reading on this
difference, and for the other variations of these methods, see
Shalev-Shwartz and Ben-David (2014), 4-6.
[23] Our stylistic
analysis was done entirely through Eder et al.’s Stylo package in the statistical computing program, R [Eder et al. 2016]. Although we’ve chosen a supervised analysis, its
methodological limitations are significant. The benefit of unsupervised
learning (e.g. PCA) is that the machine doesn’t know how many groups of data
we think we’re studying, so we can’t privilege a group split just because we
think there is one; the difficulty becomes identifying what features,
exactly, constitute the groupings output by the machine. Inversely, the
downside of a supervised analysis is that we organize the data in two
pre-conceived groups and ask that each text be assigned to one group or the
other. The benefit is that we at least think we have an idea of where
machine-located differences are coming from — i.e. in this case, we isolate
our groups based on gender. Both methods put us in an at least somewhat
compromised position when drawing conclusions about gender and its stylistic
features. [24] One digital interpretation of the stylistic
distinctiveness between the genders in modernism has been advanced elsewhere
[Weidman and O'Sullivan 2018] . Again, as Mandell notes, this measure of
“textual gender” alone is not terribly interesting;
traditional social and cultural gender signaling is perfectly expected in
literary work and, in this case, we also constructed our data to produce a
split along that line of pre-sorted difference [Mandell 2019].
[25] We forced the machine, for
example, to cull words that didn’t appear in most or all of the texts (to
prevent particularly uncommon themes, narrative locations, or character
names to artificially amplify differences); we used different MFW counts
(50, 100, 200, … 1000) to see if a more robust set of word frequencies would
change our findings; we employed a variety of sampling methods, from
analyzing each text in its entirety to including only one or two random,
bag-of-word samples; and we even swapped between statistical distance
measures, seeing similar results from Burrows’s Delta and the Wurzburg
Cosine — though we talk more in footnotes 28 and 34 about why we limited
this particular adjustment.
[26] This finding
about Hall is especially intriguing; though we haven’t space to discuss the
novel here, Hall’s protagonist, the “sexual invert” Stephen
Gordon, is narrated through much of the same language as Woolf’s in Orlando, a comparison that certainly warrants
further study.
[27] Many of the studies from Jockers and Underwood, for example,
discern as much in their 19th-century and contemporary corpuses, and
alongside at least one other aforementioned piece [Cheng 2020], one of our prior essays confirms those findings in modernist fiction
[Weidman and O'Sullivan 2018]. [28] For a detailed explanation of the nearest shrunken
centroid (NSC) method of classification, see Jockers and Witten
(2010). For a specific description of the technical features of NSC as
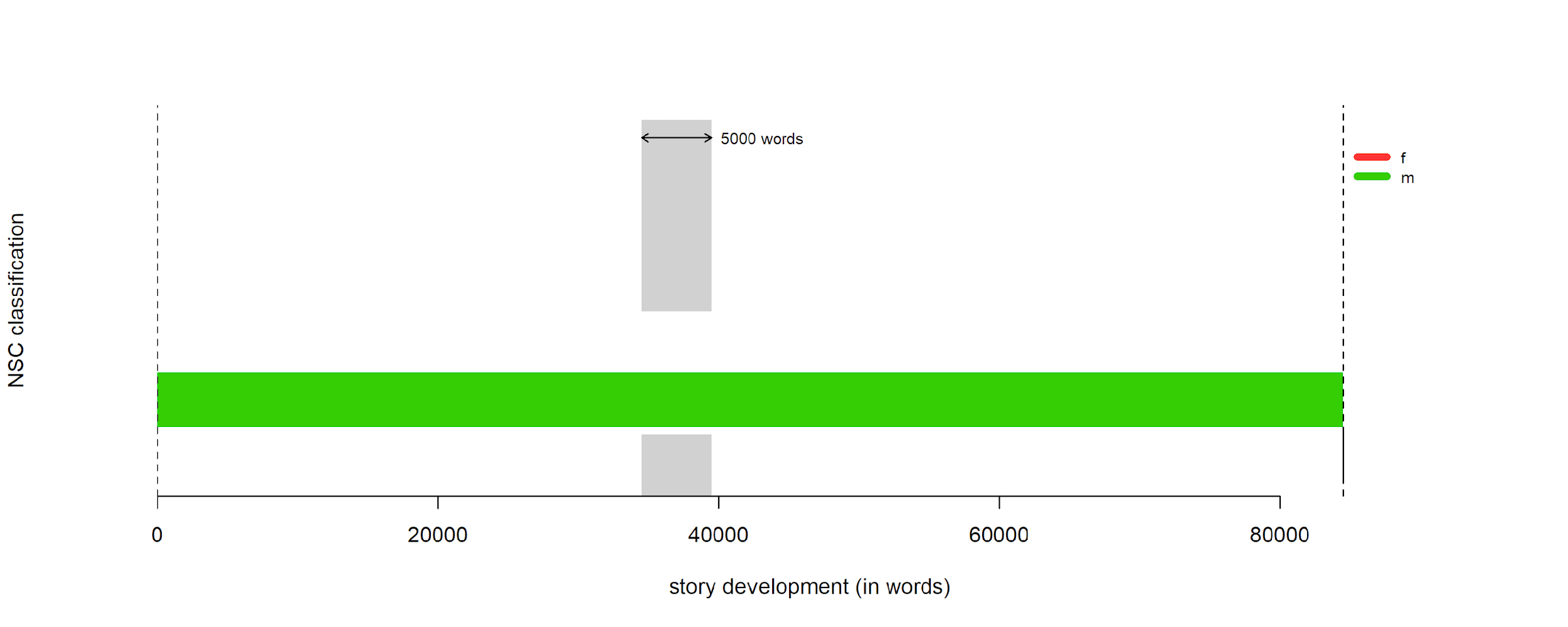
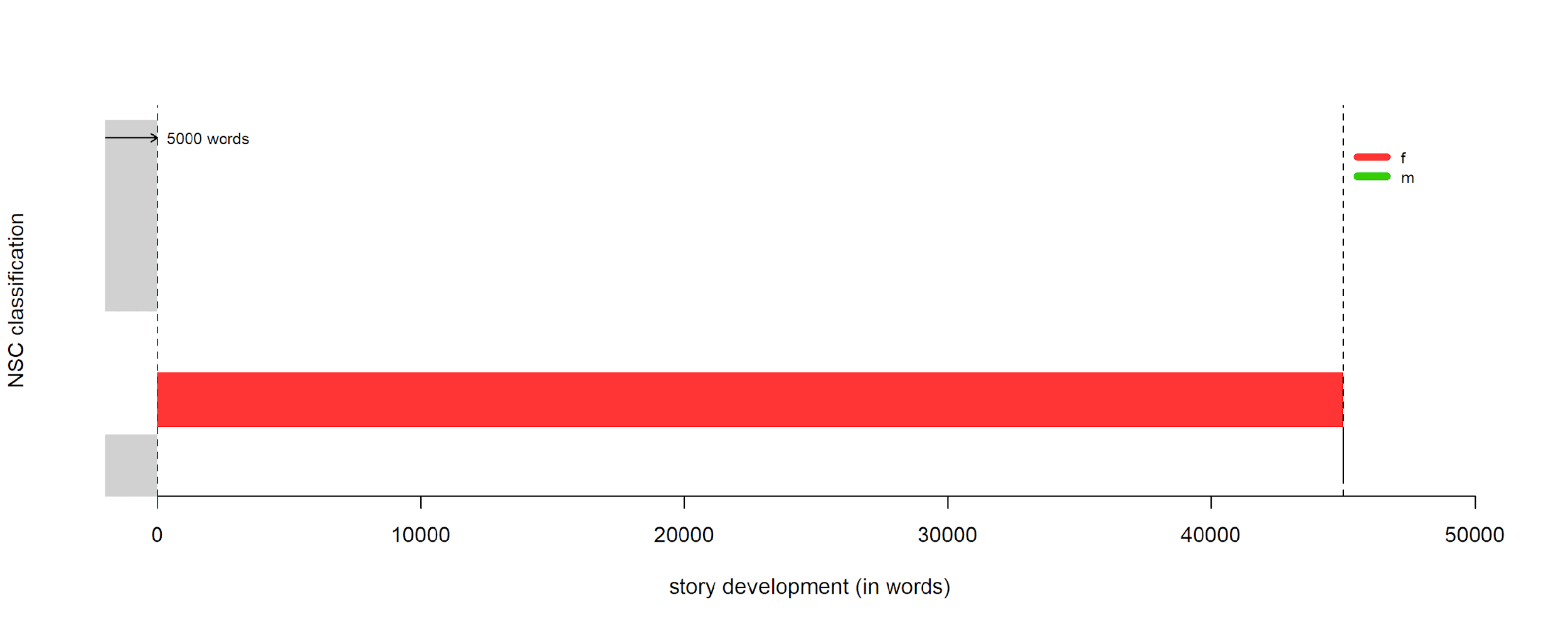
applied in Stylo, see Eder (2016). As a
stylometric classifier that finds an averaged stylistic profile, NSC
provides certain benefits over a standard variant like Burrows’s Delta in
Eder’s rolling method, which tries to pinpoint moments of stylistic
“takeover” in a single text after being trained on one more groups
of texts [Eder 2016, 459–63]. With Delta, each text in
each training group is treated distinctly and is not consolidated into a
stylistic profile (i.e. Orlando is measured
against each training sample/text, ranking the
“styles” that are closest to the test text); NSC,
however, produces composites against which we can compare our test text
(i.e. Orlando against the averaged style of
all female texts or all male texts). For our study, where we want to isolate
the gender binary as a two-class problem, NSC is a natural fit. [29] This control turned out to matter little — when we
reintroduced her remaining texts to the training set and re-ran the
analysis, the results were nearly identical.
[30]
Although we analyzed each text at 50-1000 MFWs with culling from 0-50% and
received remarkably negligible variation in our results, for exact
reproducibility’s sake, each NSC classification image we included here was
produced at 500 MFWs and 0% culling.
[31] Burrows’s aforementioned 1986 study, among other
contemporary versions — e.g. Pennebaker’s The Secret
Life of Pronouns (2011) — was among the first to explore just
how important function words were to the close analysis of literary style.
Remarkable, then, that Woolf seems to have divined and manipulated this
reality half-a-century earlier and without the benefit of computational
analysis.
[32] Several related essays warrant a
brief mention here: Brenda Helt’s “Passionate Debates on
‘Odious Subjects’: Bisexuality and Woolf’s Opposition to Theories of
Androgyny and Sexual Identity” (2010) provides an argument for
using bisexuality to describe Woolf’s depictions of desire; Jessica Berman’s
“Is the Trans in Transnational the Trans in
Transgender” (2017) offers a discussion of how Orlando’s
transnational roaming contributes to Woolf’s critique of imperial
masculinity via Orlando’s seamless gender transition; and Madelyn Detloff’s
“Camp Orlando (or) Orlando” (2016) provides
an account of the camp sensibilities and reparative work of Orlando.
[33] We steal both examples directly from
Emma Heaney’s magnificent book, The New Woman: Literary
Modernism, Queer Theory, and the Trans Feminine Allegory (2017).
In fact, Heaney’s exploration of the history and production of trans
femininity provides an important clarification to our study’s finding,
detaching Woolf from a legacy of modernist trans feminism [Heaney 2017, 302 (note 11)]. [34] We understand, of course, that we still depend on
averaged literary styles (via a bag-of-word list of most frequent terms) in
this study, and we do not call that essential stylometric practice into
question. What we’re after here, rather, is a reimagining of how eschewing
the inexact close-readings that tend to follow computational measures of
style can actually help us accomplish something critically important.
Deciphering averaged stylistic differences — or, what’s more probable,
incidentally lodging our pre-held assumptions into stylistic peculiarities —
does not expand or contextualize our conclusions as much as it forecloses
their messiness in almost-assuredly biased explainers. By restraining that
stylometric impulse, we hope to let the text’s relation to the corpus
(rather than specific terminological connections/disparities) do the
critical work for us. We want to venture an observation here, one helped
along by Adam Kilgarriff’s influential essay, “Language
is never, ever, ever, random” (2005) and its adjacent, clarifying
distinction between “randomness” and
“arbitrariness” in interpretations of linguistic
phenomena in literary corpora. That linguistic structures appear nonrandom
or predictable in their relation does not make that relation meaningful —
just as syntax can colonize meaning, narrative structures can demand certain
forms, patterns, and distributions of linguistic content, which detaches
judgments about their meaning from their possible literary-historical or
sociocultural arbitrariness. Having used a specific corpus organization and
specific modeling tools, all of which were designed to treat gender as a
bimodal stylistic question, we think finding in Orlando
a nonrandom and narratively nonarbitrary gender flip is more than a
linguistic oddity.
[35] Following Rachael
Scarborough King’s delineation of form and genre, we might even call the
literary style of gender a genre, an organizing metanarrative,
“a collection whose members are assembled and whose
boundaries are always permeable”
[King 2021, 262]. [36] This is a problem Piper (2020) has recently aimed to
tackle at much greater length and with much greater care than we do
here.
[37] As
Pryor notes elsewhere, “the category of modernism was
developed through attention to exemplars”
[Pryor 2011, 37]. [38] Etherington and Pryor also clarify this point: “because exemplarity conditions the production of
knowledge, helping to construct the very object of inquiry, it is also a
political problem”
[Etherington and Pryor 2019, 5]. [39] This is a claim that has long since entered modernist criticism's common
vocabulary, but see, among other examples: Maud Ellman, Nets of Modernism: Henry James, Virginia Woolf, James Joyce, and
Sigmund Freud (2010); Matt Ffytch, “The
Modernist Road to the Unconscious” (2012); and, for a classic
account of this impact on modern culture generally, Michael North, Reading 1922: A Return to the Scene of the Modern
(1999).
Works Cited
Adwetewa 2020 Adwetewa-Badu, Ama Bemma.
“Poetry from Afar: Distant Reading, Global Poetics, and
the Digital Humanities.”
Modernism/modernity Print Plus 5, no. 1
(2020).
Algee-Hewitt 2015 Algee-Hewitt, Mark.
“The Performance of Character: Digital Models for
Gendered Speech in Romantic period Literature.” Lecture at Simon
Fraser University, 2015.
Algee-Hewitt and McGurl 2015 Algee-Hewitt,
Mark and Mark McGurl. “Between Canon and Corpus: Six
Perspectives on 20th-Century Novels.”
Literary Lab: Pamphlet 8 (2015): 1-27.
Battershill et al. 2017 Battershill, Claire,
Helen Southworth, Alice Staveley, Michael Widner, Elizabeth Willson Gordon, and
Nicola Wilson. Scholarly Adventures in Digital Humanities:
Making The Modernist Archives Publishing Project. Routledge,
2017.
Bode 2017 Bode, Katherine. “The
Equivalence of ‘Close’ and “Distant’ Reading; or, Toward a New Object for
Data-Rich Literary History.”
Modern Language Quarterly 78, no. 1 (2017):
77-106.
Bode 2018 Bode, Katherine. A
World of Fiction: Digital Collections and the Future of Literary
History. U of Michigan P, 2018.
Brown and Mandell 2018 Brown, Susan, and Laura
Mandell. “The Identity Issue: An Introduction.”
Cultural Analytics (Feb. 2018).
Burns 1994 Burns, Christy L. “Re-Dressing Feminist Identities: Tensions between Essential and Constructed
Selves in Virginia Woolf’s Orlando.”
Twentieth Century Literature 40, no. 3 (1994): 342-
64.
Burrows 1986 Burrows, John F. Computation into Criticism: A Study of Jane Austen’s Novels
and an Experiment in Method. Oxford: Clarendon Press, 1986.
Butler 1990 Butler, Judith.Gender Trouble: Feminism and the Subversion of Identity. Routledge,
1990.
Butler 1993 Butler, Judith. Bodies That Matter: On the Discursive Limits of “Sex. Routledge,
1993.
Caughie 2013 Caughie, Pamela L. “The Temporality of Modernist Life Writing in the Era of
Transsexualism: Virginia Woolf’s Orlando and
Einar Wegener’s Man Into Woman.”
Modern Fiction Studies 59, no. 3 (2013):
501-25.
Caughie et al. 2018 Caughie, Pamela L., Emily
Datskou,& Rebecca Parker. “Storm clouds on the horizon:
feminist ontologies and the problem of gender.”
Feminist Modernist Studies 1, no. 3 (2018):
230-42.
Cheng 2020 Cheng, Jonathan Y. “Fleshing Out Models of Gender in English-Language Novels
(1850-2000).”
Cultural Analytics (Jan. 2020).
Christie et al. 2014 Christie, Alex, et al.
“Manifesto of Modernist Digital Humanities.”
Humanities Commons, 2014.
Churchill et al. 2018 Churchill, Suzanne W.,
Linda A. Kinnahan, and Susan Rosenbaum. “Feminist designs:
modernist digital humanities andMina Loy: Navigating
the Avant-Garde.”
Feminist Modernist Studies 1, no. 3 (2018):
243-56.
D'Ignazio and Klein 2016 D’Ignazio, Catherine,
and Lauren F. Klein. “Feminist Data Visualization.”
IEEE VIS4DH Conference, 2016.
Da 2019 Da, Nan Z. “The
Computational Case against Computational Literary Studies.”
Critical Inquiry 45, no. 3 (2019): 601-39.
Delaplace 2011 Delaplace, Anne. “Transcending Gender: Virginia Woolf and Marcel Proust, Orlando
and Albertine.”
Virginia Woolf Bulletin 37 (2011): 37-41.
Drouin 2014 Drouin, Jeffrey. “Close- And Distant-Reading Modernism: Network Analysis, Text Mining, and
Teaching The Little Review.”
The Journal of Modern Periodical Studies 5, no. 1
(2014): 110-35.
Drucker 2017 Drucker, Johanna. “Why Distant Reading Isn’t.”
PMLA 132, no. 3 (2017): 628-35.
Earhart et al. 2020 Earhart, Amy E., Roopika
Risam, and Matthew Bruno. “Citational politics: Quantifying
the influence of gender on citation in Digital
Scholarship in the Humanities.”
Digital Scholarship in the Humanities. Preprint, 3
August 2020.
Eder 2016 Eder, Maciej. “Rolling stylometry.”
Digital Scholarship in the Humanities 31, no. 3
(2016): 457- 69.
Eder et al. 2016 Eder, Maciej, Jan Rybicki, and
Mike Kestemont. “Stylometry with R: A Package for
Computational Text Analysis.”
R Journal 8, no. 1 (2016): 107-21.
Etherington and Pryor 2019 Etherington, Ben,
and Sean Pryor. “Historical poetics and the problem of
exemplarity.”
Critical Quarterly61, no. 1 (2019): 3-17.
Evan and Wilkens 2018 Evans, Elizabeth F., and
Matthew Wilkens. “Nation, Ethnicity, and the Geography of
British Fiction, 1880-1940.”
Cultural Analytics (Jul. 2018).
Golden and Laity 2018 Golden, Amanda, and
Cassandra Laity, “Feminist Modernist Digital
Humanities”, Feminist Modernist Studies
1, no. 3 (2018), 205-210.
Gonzalez et al. 2019 González, José Eduardo,
Montserrat-Fuente Camacho, and Marcus Barbosa. “Detecting
Modernismo’s Fingerprint: A Digital Humanities Approach to the Turn of the
Century Spanish American Novel.”
Review: Literature and Arts of the Americas 51, no.
2 (2019): 195-204.
Hankins 2018 a Hankins, Gabriel. “The Weak Powers of Digital Modernist Studies.”
Modernism/Modernity 25, no. 3 (2018):
569-585.
Hankins 2018 b Hankins, Gabriel. “We Are All Digital Modernists Now.”
Modernism/Modernity Print Plus 3, no. 2
(2018).
Hayot and Walkowitz 2016 Hayot, Eric, and Rebecca
L. Walkowitz, eds. “A New Vocabulary for Global
Modernism”. Columbia UP, 2016.
Heaney 2017 Heaney, Emma. The New Woman: Literary Modernism, Queer Theory, and the Trans Feminine
Allegory. Northwestern UP, 2017.
Herrmann et al. 2015 Herrmann, J. Berenike,
Karina van Dalen-Oskam, Christof Schöch. “Revisiting Style,
a Key Concept in Literary Studies,”
Journal of Literary Theory 9, no. 1 (2015):
25-52.
Hirtle 2012 Hirtle, Peter B. “When Is 1923 Going to Arrive and Other Complications of the U.S. Public
Domain.”
Searcher 20, no. 6 (2012): 22-8.
Hirtle 2018 Hirtle, Peter B. “Coypright Information Center.”
Cornell University Library. Jan. 10, 2018.
Hoover 2016 Hoover, David L. “Argument, Evidence, and the Limits of Digital Literary Studies.”
In Debates in the Digital Humanities 2016, edited
by Lauren F. Klein and Matthew K. Gold. U of Minnesota P, 2016, 230-50.
Huculak 2018 Huculak,J. Matthew. “What Is a Modernist Archive?,”
Modernism/Modernity Print Plus (2018).
Högberg and Bromley 2018 Högberg, Elsa and Amy
Bromley. “Introduction: Sentencing Orlando.”
Sentencing Orlando: Virginia Woolf and the Morphology of
the Modernist Sentence, edited by Elsa Högberg and Amy Bromley.
Edinburgh UP, 2018, 1-14.
James and Seshagiri 2014 James, David, and Urmila
Seshagiri. “Metamodernism: Narratives of Continuity and
Revolution,”
PMLA 129, no. 1 (2014): 87-100.
Jockers 2013 Jockers, Matthew. Macroanalysis: Digital Methods and Literary History. U
of Illinois Press, 2013.
Jockers and Kirilloff 2016 Jockers, Matthew, and
Gabi Kirilloff. “ “Understanding Gender and Character Agency
in the 19th Century Novel.”
Cultural Analytics (Dec. 2016).
Jockers and Witten 2010 Jockers, Matthew L. and
Daniela M. Witten. “A Comparative Study of Machine Learning
Methods for Authorship Attribution.”
Literary and Linguistic Computing 25, no. 2 (2010):
215-23.
Kilgarriff 2005 Kilgarriff, Adam. “Language is never, ever, ever, random.”
Corpus Linguistics and Linguistic Theory 1, no. 2
(2005): 263-76.
King 2021 King, Rachael Scarborough. “The Scale of Genre.”
New Literary History, vol. 52, no. 2 (2021):
261-84.
Kirilloff et al. 2018 Kirilloff, Gabi, Peter
J. Capuano, Julius Fredrick, and Matthew L. Jockers. “From a
distance ‘You might mistake her for a man’: A closer reading of gender and
character action in Jane Eyre, The Law and the
Lady,and A Brilliant Woman.”
Digital Scholarship in the Humanities 33, no. 4
(2018): 821-44.
Kraicer and Piper 2019 Kraicer, Eve, and Andrew
Piper. “Social Characters: The Hierarchy of Gender in Contemporary
English-Language Fiction,” Cultural Analytics (Jan. 2019).
Lavin 2020 Lavin, Matthew J. “Gender Dynamics and Critical Reception: A Study of Early 20th-century Book
Reviews from The New York Times.”
Cultural Analytics (Jan. 2020).
Long and So 2013 Long, Hoyt, and Richard Jean So.
“Network Analysis and the Sociology of
Modernism,” boundary 2 40, no. 2 (2013).
Long and So 2016 a Long, Hoyt, and Richard Jean
So. “Literary Pattern Recognition: Modernism between Close
Reading and Machine Learning.”
Critical Inquiry 42, no. 2 (2016): 235-67.
Long and So 2016 b Long, Hoyt, and Richard Jean
So. “Turbulent Flow: A Computational Model of World
Literature.”
Modern Language Quarterly 77, no. 3 (2016):
345-67.
Losh et al. 2016 Losh, Elizabeth, Jacqueline
Wernimont, Laura Wexler, and Hong-An Wu. “Putting the Human
Back into the Digital Humanities: Feminism, Generosity, and Mess.” In
Debates in the Digital Humanities 2016, edited
by Lauren F. Klein and Matthew K. Gold. U of Minnesota P, 2016, 92-103.
Mandell 2016 Mandell, Laura C. “Gendering Digital Literary History: What Counts for Digital
Humanities.” In A New Companion to Digital
Humanities, 2nd ed, edited by Susan Schreibman, Ray Siemens, and John
Unsworth. Wiley-Blackwell, 2016, 511-23.
Mandell 2019 Mandell, Laura C. “Gender and Cultural Analytics: Finding or Making
Stereotypes?”
Debates in the Digital Humanities2019, edited by
Matthew K. Gold and Lauren F. Klein. UP of Minnesota, 2019.
Mao and Walkowitz 2008 Mao, Douglas, and Rebecca
Walkowitz. “The New Modernist Studies,”
PMLA 123, no. 3 (2008): 737-48.
McGrath et al. 2018 McGrath, Laura B., Devin
Higgins, and Arend Hintze. “Measuring Modernist
Novelty.”
Cultural Analytics(Nov. 2018).
Nelson 1986 Nelson, Cary. Repression and Recovery: Modern American Poetry and the Politics of
Cultural Memory, 1910-1945. U of Wisconsin P, 1989.
North 1999 North, Michael. Reading 1922: A Return to the Scene of the Modern. Oxford UP,
1999.
Piper 2016 Piper, Andrew.“There Will Be Numbers.”
Cultural Analytics (May 2016).
Piper 2017 Piper, Andrew.“Think Small: On Literary Modeling.”
PMLA 132, no. 3 (2017): 651-8.
Piper 2020 Piper, Andrew. Can
We Be Wrong? The Problem of Textual Evidence in a Time of Data.
Elements in Digital Literary Studies, edited by Katherine Bode, Adam
Hammond, and Gabriel Hankins. Cambridge UP, 2020.
Piper and So 2016 Piper, Andrew, and Richard
Jean So. “Women Write About Family, Men Write About
War.”
New Republic, Apr. 8, 2016.
Posner et al. 2017 Posner, Miriam and Lauren F.
Klein. “Editor’s Introduction: Data as Media.”
Feminist Media Histories 3, no. 3 (2017):
1-8.
Pressman 2014 Pressman, Jessica. Digital Modernism: Making It New in New Media. Oxford
UP, 2014.
Pryor 2011 Pryor, Sean. “A
poetics of occasion in Hope Mirrlees’s Paris.”
Critical Quarterly 61, no. 1 (2019): 37-53.
Ramsay 2011 Ramsay, Stephen. Reading Machines: Toward an Algorithmic Criticism. U of Illinois P,
2011.
Riddell and Barrett 2020 Riddell, Allen and Troy
J. Barrett. “What Library Digitization Leaves Out:
Predicting the Availability of Digital Surrogates of English Novels.”
arXiv:2009.00513 [cs.DL]. Preprint, 1 September
2020.
Risam 2016 Risam, Roopika. “Navigating the Global Digital Humanities: Insights from Black
Feminism.” In Debates in the Digital
Humanities 2016, edited by Lauren F. Klein and Matthew K. Gold. U of
Minnesota P, 2016, 359-67.
Ross and O'Sullivan 2016 Ross, Shawna, and James
O’Sullivan, eds. Reading Modernism with Machines: Digital
Humanities and Modernist Literature.Palgrave Macmillan, 2016.
Ross and Sayers 2014 Ross, Stephen, and Jentery
Sayers. “Modernism Meets Digital Humanities.”
Literature Compass 11, no. 9 (2014):
625-633.
Rubin 1975 Rubin, Gayle. “The
Traffic in Women: Notes on the ‘Political Economy’ of Sex.” In Toward an Anthropology of Women, edited by Rayna R.
Reiter. Monthly Review Press, 1975, 157-210.
Rybicki 2016 Rybicki, Jan. “Vive la différence: Tracing the
(authorial) gender signal by multivariate analysis of word
frequencies.”
Digital Scholarship in the Humanities 31, no. 4
(2016): 746-61.
Shalev-Schwartz and Ben-David 2014 Shalev-Shwartz, Shai, and Shai Ben-David. Understanding
Machine Learning: From Theory to Algorithms. Cambridge UP,
2014.
So 2017 So, Richard Jean. “All
Models Are Wrong.”
PMLA 132, no. 3 (2017): 668-73.
Stanford 2015 Stanford Friedman, Susan. Planetary Modernisms: Provocations on Modernity Across Time.
Columbia UP, 2015.
Underwood 2019 Underwood, Ted. Distant Horizons: Digital Evidence and Literary
Change. U Chicago P, 2019.
Underwood 2020 Underwood, Ted. “Machine Learning and Human Perspective.”
PMLA 135, no. 1 (2020): 92-109.
Underwood and So 2021 Underwood, Ted and Richard Jean So, “Can We Map Culture?” Cultural Analytics (June 2021).
Underwood et al. 2018 Underwood, Ted, David
Bamman, and Sabrina Lee. “The Transformation of Gender in
English-Language Fiction.”
Cultural Analytics (Feb. 2018).
Weidman and O'Sullivan 2018 Weidman, Sean G.,
and James O’Sullivan. “The limits of distinctive words:
Re-evaluating literature’s gender marker debate,”
Digital Scholarship in the Humanities 33, no. 2
(2018): 374-90.
Wollaeger 2012 Wollaeger, Mark, and Matt
Eatough, eds. The Oxford Handbook of Global
Modernisms. Oxford UP, 2012.
Woolf 1992 Woolf, Virginia. Orlando: A Biography. (1928). Vintage, 1992.
Woolf 2009 Woolf, Virginia. “Poetry, Fiction and the Future.”
Selected Essays. Oxford UP, 2009, 74-84.