


Volume 12 Number 2
Manuscript Study in Digital Spaces: The State of the Field and New Ways Forward
Abstract
In the last decade tremendous advances have been made in the tools and platforms available for the digital study of manuscripts. Much work, however, remains to be done in order to address the wide range of pedagogical, cataloging, preservation, scholarly (individual and collaborative), and citizen science (crowdsourcing) workflows and use cases in a user-friendly manner. This study (1) summarizes the feedback of dozens of technologists, manuscript experts, and curators obtained through survey data and workshop focus groups; (2) provides a “state of the field” report which assesses the current tools available and their limitations; and, (3) outlines principles to help guide future development. The authors in particular emphasize the importance of producing tool-independent data, fostering intellectual “trading zones” between technologists, scholars, librarians, and curators, utilizing a code base with an active community of users, and re-conceptualizing tool-creation as a collaborative form of humanistic intellectual labor.
I. Introduction
- to assess the current state of tools, services and infrastructure for the creation and preservation of digital editions and annotation of manuscripts, images, and related data objects;
- to determine the extent to which those tools, services and infrastructure that come closest to meeting the needs of our respective projects can be reused and linked together;
- to identify any apparent obstacles to their reuse and gaps in the functionality that they provide;
- to create a “trading zone”[1] to foster dialogue between researchers, technologists, and librarians in the university, gallery, library, archive, and museum (GLAM) contexts regarding the functionality they would ideally like to see in an integrated image workspace.
II. Problems and Desiderata
General Overview
| Tool/Platform | Type |
| oXygen | Desktop software application |
| Microsoft Access | Desktop software application |
| PDFExpert | Desktop software application |
| XMLMind | Desktop software application |
| Kitodo | Software platform |
| IIIF (International Image Interoperability Framework) | API Specifications |
| Mirador | Web application |
| Omeka | Web application (hosted or local installation) |
| e-ktobe | Online dataset/collection |
| OPenn | Online dataset/collection |
| The Vatican Library Platform | Online dataset/collection |
| Pinakes | Online dataset/collection |
| Perdita Project | Online dataset/collection |
| Brotherton Manuscripts | Online dataset/collection |
| DEx: A Database of Dramatic Extracts | Online dataset/collection |
| Shelley-Godwin Archive | Online dataset/collection |
| Blake Archive | Online dataset/collection |
| CELM: Catalogue of English Literary Manuscripts | Online dataset/collection |
| Camena | Online dataset/collection |
| British Literary Manuscripts Online | Online dataset/collection and tools |
| Gallica (Bibliothèque Nationale de France) | Online dataset/collection and tools |
| The New Testament Virtual Manuscript Room | Online dataset/collection and tools |
| Coptic Old Testament Virtual Manuscript Room | Online dataset/collection and tools |
| vHMML | Online dataset/collection and tools |
| Coptic Scriptorium | Online dataset/collection and tools |
| TAPAS | Online platform, repository and tools |
| Transkribus | Online platform plus installable tools |
| Papyri.info | Online platform, dataset/collection and tools |
| Perseids | Online platform and tools |
Requirements of Scholars, Curators, Librarians, and Technologists
Requirements of scholars:
- A tool/workspace that aggregates previous scholarly comments on manuscripts of particular texts and authors;
- A collaborative space to draw on expertise of catalogers and content specialists of different areas (e.g., manuscript experts, textual scholars, art historians). As we heard repeatedly at the workshop, “no one can do it alone”;
- Collaborative scholarly workflows (e.g., functionality and workflows that enable in digital space the scholarly workshop model of multiple scholars working together on one manuscript) and similar workflows for citizen science, knowledge-sourcing, or crowd-sourcing initiatives;
- Pedagogical workflows for use with students and “citizen scientists”;
- Ability to access manuscript images from multiple digital repositories and use digital tools on them (i.e., a client application model);
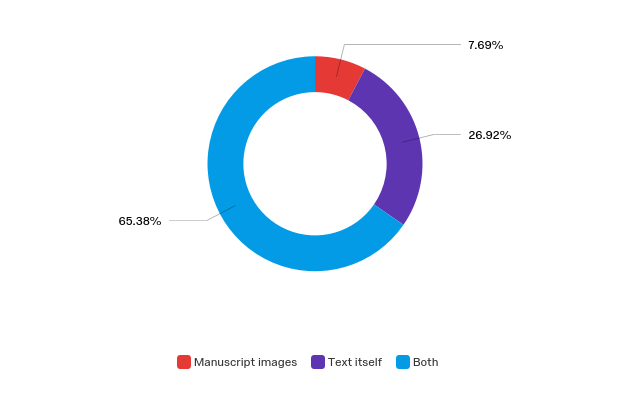
- Integration of text and image data — as one can see in Figure 3, over 65 percent of respondents indicated they need to be able to work with both manuscript text and image data in their work;
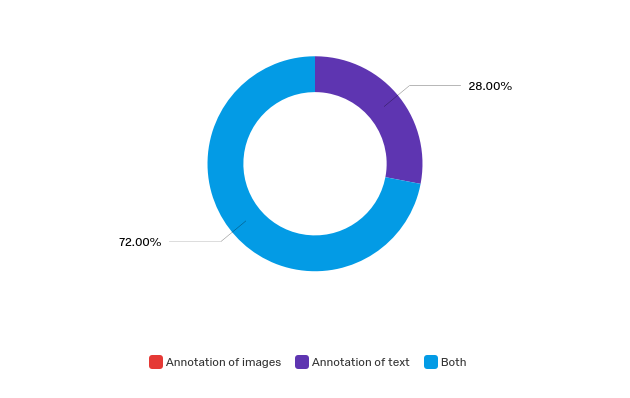
- Ability to annotate text and image data. The ability to annotate both types of data was reported as a requirement by 72 percent of respondents (see Figure 4);
- Educational materials/tutorials on how to setup and use new digital tools and workspaces;
- Institutional mechanisms and support for creating joint projects with digital librarians and technologists;
- A common gateway (because there are too many separate digital manuscript collections with unconnected repositories that cannot be universally searched), linking of similar texts in multiple repositories, and information about the differences between those copies;
- Tools and workflows to create and publish digital scholarly editions of works (e.g., digital critical editions, multi-text editions), including peer-review mechanisms;
- Better non-Latin script/right-to-left language support;
- Support for multimedia archives;
- Geographic tagging (for images of architecture, for example) to enable visualizations of diachronic transformations of place, buildings, etc.;
- Linking of sound recordings to geographic spaces;
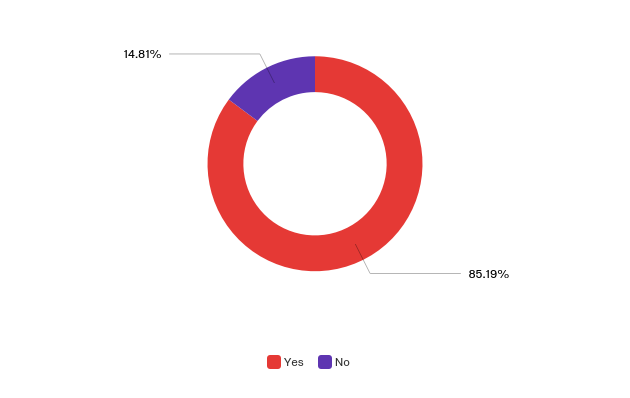
- Ability to work, side by side, with multiple versions of the same manuscript — a requirement reported by over 85 percent of survey respondents (Figure 5) — and ability to annotate text variants and compare and classify large collections of manuscripts into manuscript families.
Requirements of curators and librarians:
- Cataloging workflows (both for lone cataloger and collaborative cataloging projects);
- User-friendly sharing;
- Inclusion of conservation reports;
- More attention to materiality of the object and structure of books (e.g., bindings), including metadata on the whole object;
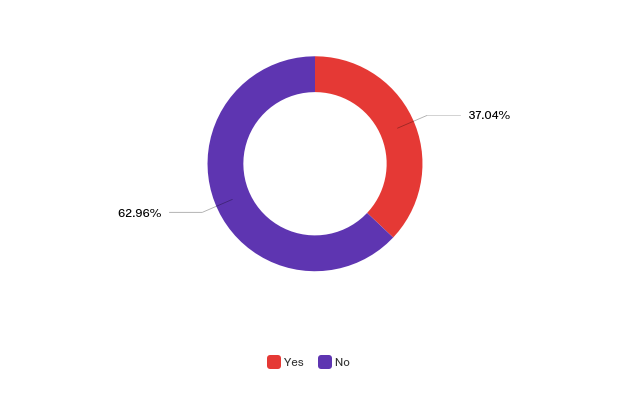
- Mechanisms that allow for restricted user access (although many collections are moving to open-access models, not all collections are willing to make images completely open access: in the survey results a sizable minority (37 percent) still reported that they need to restrict access to their image or textual data due to licensing/copyright reasons — see Figure 6);
- Tools that can be used by local teams (especially in poor or conflict areas) that are computationally light and standards-compliant (thus helping to facilitate collaboration with wider scholarly communities);
- Standards for dealing with multiple manuscripts in a single codex;
- Digital reunification of dispersed codices;
- Digital repatriation of objects removed from their country of origin;
- Expanded metadata for features such as type of paper, color of ink, type of leather;
- Inclusion of preservation metadata;
- Better support for dealing with alternative (i.e., non-traditional manuscript) image data, such as wedding certificates, audio visual materials, textiles, and 3D objects.
Requirements of technologists:
- Interoperability;
- Standards compliance;
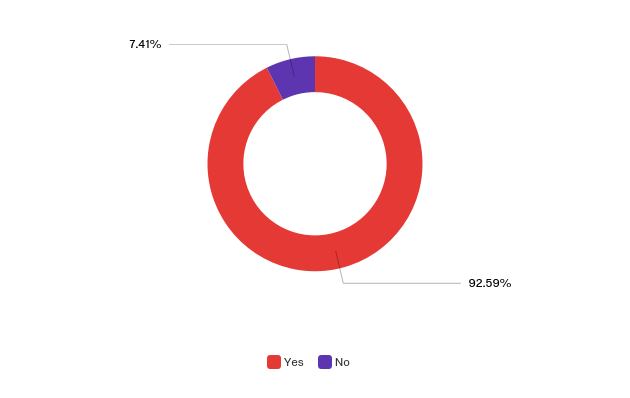
- Persistent identifiers and permanent citation of manuscript data — a critical need, which over 92 percent of survey respondents indicated was required for their work (see Figure 7);
- Named entity recognition;
- Ability to display documents together with known metadata;
- Ability to add and correct existing metadata;
- Stable edition numbers for texts published online (i.e., versioning);
- Version control (i.e., detailed tracking of textual changes through time);
- Citation via tag or git commit hash;
- Support for reading in multiple directions;
- Usability of tools/platforms in low bandwidth locations;
- Rejection of digital repository silo models;
- Controlled vocabularies that are built into cataloging/metadata;
- Ability to export data in multiple standard formats, especially TEI XML;
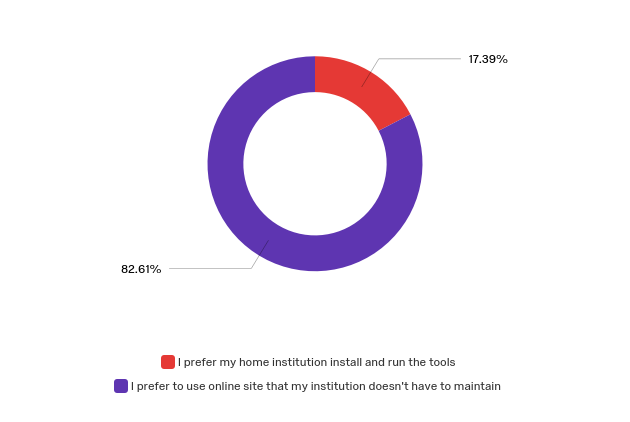
- Online hosted solution (preferable) or downloadable out-of-the-box program, since most users report that they do not have the requisite technical knowledge to setup tools/platforms and they do not have in house support from technologists to do it for them (see Figure 2).
Tool-Specific Issues
- What use cases and workflows is it intended to support?
- What additional use cases and workflows is it capable of supporting?
- Could gaps in functionality be filled by combining it with another tool?
- Could gaps in functionality be filled by extending it with new development?
- What skills are necessary to be able to use it effectively?
- What skills are necessary to be able to extend it with new functionality?
- How well does it support data management best practices?
|
Platform/
Tool |
Main functionality | Curation and preservation workflows | Support external IIIF manifests | Metadata extensibility | Collaborative workspace features | Code base and framework for development |
| Scriptorium | Annotation and transcription of manuscripts | No | Yes | No; Idiosyncratic schema | Yes | JavaScript; Meteor Framework |
| Omeka | Display and publication of digital collections | Some functionalities | In development | Good | No | PHP and JavaScript |
| Getty Scholar’s Workspace | Research environment for art historian | No | No (but a Drupal plugin exists) | Only Dublin Core | Yes | Developed as extensions to Drupal; PHP |
| vHMML | Virtual reading room and cataloging environment | No | Yes | No; Idiosyncratic schema | No | Java |
| Collective Access | Physical and digital collection management | Some functionalities | In development | Good | No | PHP |
| Mirador | Client-side image viewer | No | Yes | NA | NA | JavaScript |
|
Platform/ Tool |
User Experience for working on manuscripts | Quality of documentation | Open source | Development community | Extensibility | Manuscript annotation support |
| Scriptorium | Good | Poor | Small team; limited to the project | NA | Yes | |
| Omeka | NA | Good | Yes | Large active community | Yes | No |
| Getty Scholar’s Workspace | Limited | Good | Yes | Small team; Not active | Yes | Yes (some features implemented) |
| vHMML | NA | Poor | Yes | Small team; limited to the project | Somewhat | Yes |
| Collective Access | Limited | Good | Yes | Active community | Yes | Only for single images |
| Mirador | NA | Good | Yes | Active community | Yes | Yes |
III. Observations and Recommendations for the Field
Insights
- There is a diversity of workflows that need to be addressed.
- There are different workflows needed for pedagogical, cataloging, preservation, individual scholarly, collaborative scholarly, and citizen science (crowdsourcing) work. Therefore, some tools may use a shared base platform (e.g., Omeka or Drupal) and add different workflows as modules or plugins for the base platform. This approach makes it easier to reuse and repurpose existing platforms.
- The tool’s code base and level of community involvement is
critical for sustainability and expansion.
- The code base significantly impacts future usability of tool. For example, high quality code base reduces the overall cost of recruiting new contributors.
- An active community of users and developers is critical in sustaining a tool. It is worth studying the best practices on this point.
- Following development best practices, such as producing comprehensive unit tests and developer documentation, is essential to reuse.
- There are no developer-free, end-to-end solutions for scholars and
students of manuscripts.
- There are no end-to-end solutions that are developer-free.
- The field still lacks basic infrastructure, guidance and sustainable solutions for individual scholars and small institutions to manage and preserve their manuscript images and data.
- Iteration is inescapable.
- There is no one tool or platform that is going to be the panacea, so we need to think in terms of iterative development and collaborative development building upon existing tools and platforms.
- Tool/platform creation is a collaborative form of intellectual
labor.
- We need to bring scholars, curators, and librarians together with technologists to create new tools and platforms and work to reconceptualize this collaborative work as a form of intellectual labor that is recognized by university administration as such in existing hiring, promotion, and tenure review processes.
Recommendations
- Data curation and tool creation should be treated as separate
projects.
- We need to think about and plan for data separately from its manifestation in a particular tool. For example, high resolution images can be stored and preserved in an image repository while tools that aim to facilitate collaborative work on manuscripts can use IIIF manifestation of those images without the need to store and preserve original images.
- We need to plan for enabling persistent identification and citations, in order to have clearly defined connection points and use APIs that can outlast the tools.
- Data must be easy to export and transform.
- We need to create more “trading zones”
[Galison 1997] for technologists, librarians,
curators, and scholars of manuscripts.
- We need to establish communities and spaces (i.e., “trading zones”) composed of technologists, librarians, and scholars and develop “interlanguages” that facilitate collaboration. In the course of our workshop round tables with users, for example, it became clear that there are a number of types of functionality that users want but are unable to find in existing solutions and have not even been thought about before. Developers of such platforms will benefit from such trading zones through learning about the needs of their intended community of users, and thereby improve the overall design and functionality of the platform.
- We need to better document the workflows and use cases our tools
are meant to address.
- Workflows and ideal use cases need to be identified and documented for each tool (in the workshop it became clear that even experts in the field were not always able to easily ascertain the workflows and use cases that a particular tool aimed to support). Well-documented workflows and use cases make extension and repurposing of the tools easier.
- Avoid starting from scratch.
- Since there is no platform which satisfies the wide-ranges of needs and workflows, it might be tempting to think about building a platform from scratch. We believe it is better to resist such temptations. There are many platforms (e.g., Omeka and Drupal) which can serve as the base infrastructure for development of tools. Designers and developers can use those platforms and add modules and plugins to extend their functionalities to serve particular workflows and use cases.
Appendix I: Survey Information
- Q1 - If you currently study manuscripts, do you employ any digital tools or platforms?
- Q2 - If you currently study manuscripts, but do not employ any digital tools or platforms, why do you not make use of any of the existing tools and platforms?
- Q3 - If you currently do use platforms or tools when studying manuscripts, which ones do you use?
- Q4 - Why do you use the platform you mentioned in the question above?
- Q5 - Which tools or platforms would you point to as the best in the field currently?
- Q6 - What features and functionality of these tools or platforms are most important to you?
- Q7 - What features and functionality of these tools and platforms would you like to see improved and how?
- Q8 - What features or functionality would you like to see in a manuscript workspace that you do not currently see in any of the existing tools platforms?
- Q9 - What are the approximate sizes of the collections of manuscripts that
you typically work with in your capacity as a scholar or curator?
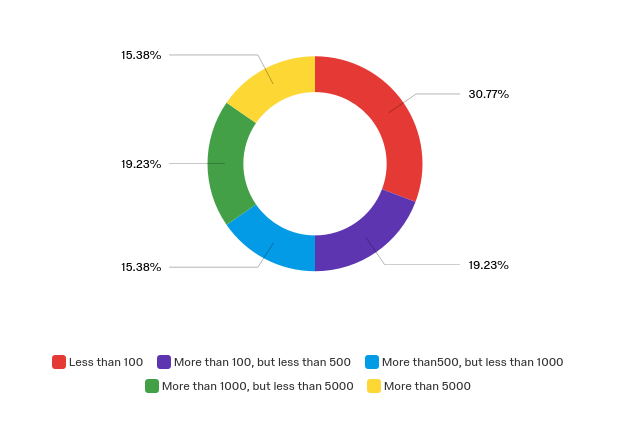
- Less than 100
- More than 100, but less than 500
- More than 500, but less than 1000
- More than 1000, but less than 5000
- More than 5000
- Q10 - Which of the following options are the primary focus of your
digitization effort?
- Manuscript images
- Text itself
- Both
- Q11 - Do you need to support annotation?
- Annotation of images
- Annotation of text
- Both
- Q12 - Are you working with multiple manuscripts of the same text?
- Q13 - Is enabling citation of your manuscript data (text or image) important for you?
- Q14 - Do you need to restrict access to images or textual content for licensing/copyright reasons?
- Q15 - Are there particular file formats (for example, TEI XML) that are required for storing the output of your research? Please provide the file formats.
- Q17 - Do you have technical staff or services at your home institution
that could install and run the tools for you, or do you prefer to use an
online site that your institution does not have to maintain?
- I prefer my home institution install and run the tools
- I prefer to use an online site that my institution does not have to maintain
- ArabicLitScholars (arabiclitscholars_at_utlists_dot_utexas_dot_edu)
- Adabiyat (adabiyat_at_lists_dot_uchicago_dot_edu)
- IslamAAR (islamaar_at_lists_dot_psu_dot_edu)
- Digital Classicist (digitalclassicist_at_jiscmail_dot_ac_dot_uk)
- French DH (dh_at_groupes_dot_renater_dot_fr)
- The Digital Humanities Summer Institute (institute_at_lists_dot_uvic_dot_ca)
- Dublin Core Metadata Data Initiative - Cultural Heritage Task Group (DC-CULTURAL-TG_at_jiscmail_dot_ac_dot_uk)
- Association for Iranian Studies (listserv_at_societyforiranianstudies_dot_org)
Appendix II: Goals for Tool Evaluations
Primary Objectives
- What use cases and workflows is it intended to support?
- What additional use cases and workflows is it capable of supporting?
- Could gaps in functionality be filled by combining it with another tool?
- Could gaps in functionality be filled by extending it with new development?
- What skills are necessary to be able to use it effectively?
- What skills are necessary to be able to extend it with new functionality?
- How well does it support data management best practices? (Consider features such as persistent identification of resources, versioning, data import/export, data transformations, standard data formats, ontologies, etc.)
- Which of these high-level use cases does it support with regard to
digital manuscript content:
- a. Creation
- b. Curation
- c. Publication
- d. Preservation
- e. Collaboration
- f. Pedagogy
- g. Analysis
- h. Other
- Which of these content types does it support:
- a. Metadata
- b. Text
- c. Images
- d. Annotations
- e. Other
-
Persistent Identifiers
- Does it provide stable identifiers to your data objects?
- What type? (URLs, DOIs, Handles, ARKs, Database Identifiers, etc.)
- Are they globally unique or unique only to the instance of the tool/platform?
- What means does it provide to make these identifiers persistent and resolvable outside the context of the tool/platform?
- At what level of granularity are they available? (The object, a fragment of an object, annotations on an object, etc.)
- Can you supply your own PIDs for your data objects in addition to or instead of those assigned by the platform?
- Does it support versioning of identifiers?
- Are there any restrictions on what is considered a data object?
- Does it offer a means to provide formalized, machine-actionable descriptions of the data objects?
- Does it support versioning of data?
- Can you export your data?
- Does it provide an API for access to its data?
- What data type formats does it support?
- Can you add/define your own data types and formats?
- What support does it provide for publishing your data as linked data?
- What support does it provide for ingesting or referencing external linked data sources?
- Can you group your data into collections?
- Can you have multiple collections of different data types?
- Can you define relationships between items across collections?
- What cataloging functionality does it provide?
- Does it support OAI/PMH?
- a. For export?
- b. For ingest/harvesting?
- What metadata vocabularies does it support?
- a. Can you define or supply your own vocabulary?
- What text formats does it support?
- a. Plain Text, HTML, HOCR, Markdown, XML, PDF, etc.?
- Is there an interface to upload textual content?
- a. From the file system?
- b. From urls?
- c. Does it support batch mode?
- Does it provide support for linking text to other objects (images, external sites, annotations, etc.)?
- What image formats does it support?
- a. JPG, PNG, TIFF, etc.
- Does it support a IIIF API endpoint?
- Is there an interface to upload images?
- a. From the file system?
- b. From urls?
- c. Does it support batch mode?
- d. Does it support 3D visualization features?
- Does it provide support for linking images to other objects (texts, external sites, annotations, etc.)?
- Can you create annotations?
- a. On text?
- b. On images?
- c. On pdfs?
- d. On other?
- How are annotations stored?
- a. Are they assigned identifiers distinct from the items they are attached to?
- Does it support collaboration on a shared object?
- Does it support real time collaboration (multiple users working on the same object at the same time)?
- Does it provide a user model?
- What authentication options are offered?
- a. OAuth2 and Social Identity Providers?
- b. Shibboleth?
- c. Username/password?
- d. Other?
- Does it support group features?
- Does it support user roles?
- a. At what level of granularity?
- Individual objects?
- Application wide?
- Project?
- a. At what level of granularity?
- Does it support plugins for new functionality?
- Does it provide documentation for how to extend?
- Does it provide APIs for application integration?
- What programming language(s) are required to extend it?
- a. What skill level is required to extend it?
- Does it support custom themes/stylesheets for presentation?
- Does it support mobile devices?
- Is there an active developer community?
- Is the code documented?
- How easy is to use?
- Is there user help/documentation?
- Are there tutorials?
Notes
Works Cited

Comments: dhqinfo@digitalhumanities.org
Published by: The Alliance of Digital Humanities Organizations and The Association for Computers and the Humanities
Affiliated with: Digital Scholarship in the Humanities
DHQ has been made possible in part by the National Endowment for the Humanities.
Copyright © 2005 -

Unless otherwise noted, the DHQ web site and all DHQ published content are published under a Creative Commons Attribution-NoDerivatives 4.0 International License. Individual articles may carry a more permissive license, as described in the footer for the individual article, and in the article’s metadata.
