


Volume 12 Number 1
Les Sganarelle de Molière : un nom, des syntaxes ?
Molière's Sganarelles: one name, several syntaxes?
Abstract
Les études quantitatives consacrées à la syntaxe dans le théâtre de Molière sont rares. Cet article propose une analyse syntaxique du discours des personnages de Molière qui repose sur l’extraction de séquences de catégories grammaticales (ou parties du discours) et leur tri et filtrage grâce à l’analyse des correspondances. Il s’agit ici d’étudier l’évolution du personnage de Sganarelle, qui apparaît dans plusieurs pièces de Molière, en vers et en prose, et qui représente souvent le « bourgeois de Paris », dont les valeurs vont à l’encontre de celles que partagent les mondains. L’analyse des résultats est menée du point de vue de ce que D. Biber et S. Conrad appellent la register perspective, afin d’identifier les séquences syntaxiques qui caractérisent les différents Sganarelle en fonction de la situation de communication dans laquelle s’inscrit leur discours. Les résultats montrent les différentes façons dont Molière exploite le personnage à mesure que s’affirme le nouveau comique qu’il met en œuvre, un comique fondé sur le jeu avec les valeurs de la société mondaine.
Introduction
Résultats quantitatifs
- Étiquetage des textes ;
- Extraction des séquences syntaxiques ;
- Filtrage des séquences syntaxiques ;
- Analyse des correspondances ;
- Analyse des occurrences.
| TAG | DESCRIPTION |
| ABR | Abréviation |
| ADJ | Adjectif |
| ADV | Adverbe |
| DET | Déterminant |
| INT | Interjection |
| KON | Conjonction |
| NAM | Nom propre |
| NUM | Chiffre |
| PRO | Pronom |
| PRP | Préposition |
| PUN | Ponctuation |
| SENT | Ponctuation de fin de phrase |
| VER | Verbe |
- – (<DET><NOM>) : deux occurrences, « Le livre » et « la table » ;
- – (<DET><NOM><VER>) : une occurrence, « Le livre est » ;
- – (<DET><NOM><VER><PRP) : une occurrence, « livre est sur la », etc.
| Titre de la pièce et son abréviation | Année de représentation / année de publication | Forme de la pièce | Nombre de tokens dans l’ensemble des répliques de Sganarelle | Nombre de séquences extraites[15] |
| Sganarelle, ou le Cocu imaginaire (CI) | 1660/1662 | Comédie en 1 acte, en vers | 2589 | 251 |
| L’École des maris (EM) | 1661/1661 | Comédie en 3 actes, en vers | 5224 | 553 |
| Le Mariage forcé (MF) | 1664/1668 | Comédie-ballet en 1 acte, en prose | 2986 | 294 |
| Le Médecin volant (MV) | 1664/1819 | Comédie en 1 acte, en prose | 2243 | 232 |
| Le Festin de Pierre (DJ) | 1665/1683 | Comédie en 5 actes, en prose | 4856 | 500 |
| L’Amour médecin (AM) | 1665/1666 | Comédie-ballet en 3 actes, en prose | 1942 | 173 |
| Le Médecin malgré lui (MML) | 1666/1667 | Comédie en 3 actes, en prose | 4607 | 461 |

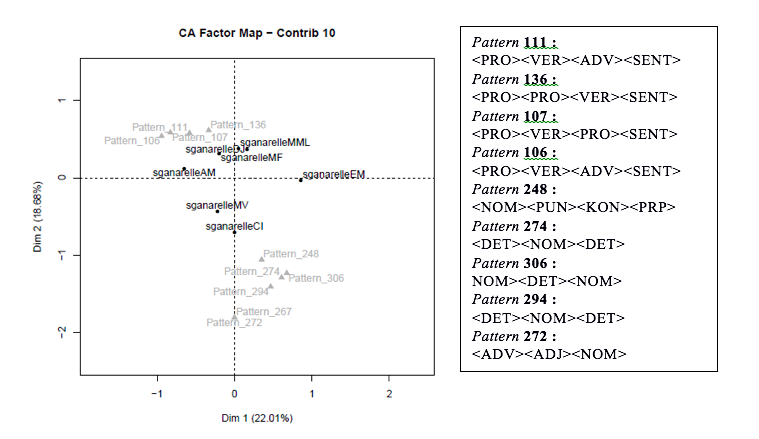
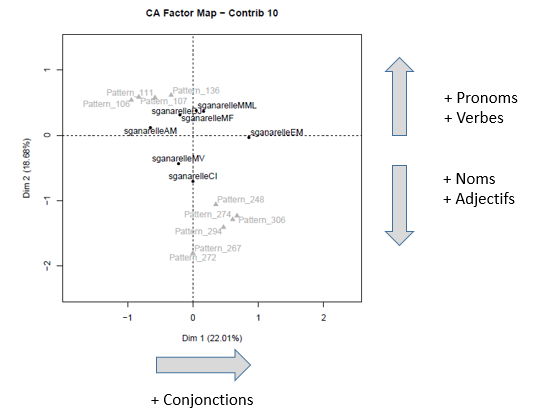
Les deux comédies en vers : Sganarelle ou le Cocu imaginaire et L’École des maris
| Identifiant de la séquence | Séquence | |
| 1 | Pattern 306 | <NOM><DET><NOM> |
| 2 | Pattern 294 | <DET><NOM><DET> |
| 3 | Pattern 267 | <PRP><DET><NOM><DET> |
| 4 | Pattern 272 | <ADV><ADJ><NOM> |
| 5 | Pattern 274 | <KON><DET><NOM><PRP> |
| Titre de la pièce | Réplique moyenne (taille moyenne en lignes : 1 l. = 60 signes) |
| Le Médecin volant | 2,7 l. |
| Sganarelle ou le Cocu imaginaire | 2,5 l. |
| Le Festin de Pierre (Don Juan) | 2,3 l. |
| L’École des maris | 2,2 l. |
| L’Amour médecin | 1,9 l. |
| Le Mariage forcé | 1,4 l. |
| Le Médecin malgré lui | 1,4 l. |
- Pattern 306[22] : <NOM><DET><NOM> (total de 14 occurrences)
- Tu ne m’entends que trop, madame la carogne
- Nous l’avons, et je puis voir à l’aise la trogne
Du malheureux pendard qui cause ma vergogne.
- Nous savons Dieu merci le souci qui vous tient
- Je ne sais pas si j’ai dans sa galanterie
L’honneur d’être connu de votre seigneurie ;
- C’est-à-dire qu’il faut toucher au doigt la chose.
- Voici ma foi la chose en propre original.
- Je hais de tout mon cœur les Esprits colériques,
- Et mettons sous nos pieds les soupirs et les larmes ;
- Courage mon enfant, soit un peu vigoureux,
- L’on ne demandait pas carogne ta venue,
- Accepte sans façon le
marché qu’on propose. Pattern 294 : <DET><NOM><DET> (total de 10 occurrences)
- La chose est avérée, et je tiens dans mes mains
Un bon certificat du mal dont je me plains.
- Doucement s’il vous plaît cet homme a bien la mine D’avoir le sang bouillant et l’âme un peu mutine,
- Et d’attacher l’honneur de l’homme le plus
sage Aux choses que peut faire une femme volage ;
- Vous croyez qu’en ce fait la plus forte apparence Peut jeter dans l’esprit une fausse créance
- Pattern 267 : <PRP><DET><NOM><DET> (total de 7 occurrences)
- Aucune nouvelle occurrence, puisque la séquence 3 est enchâssée dans la séquence 2.
| Identifiant de la séquence | Séquence | |
| 1 | Pattern 502 | <KON><PRP><NOM> |
| 2 | Pattern 744 | <ADJ><NOM><PUN><PRO> |
| 3 | Pattern 747 | <PRO><PUN><PRO><VER> |
| 4 | Pattern 438 | <NOM><PUN><KON><DET> |
| 5 | Pattern 269 | <PUN><KON><DET><NOM> |
- Pattern 502 : <KON><PRP><NOM> (total de 17 occurrences)
- De ces manches qu’à table on voit tâter les sauces
- Et de père, et d’époux donner pleine puissance,
- Et de père, et d’époux donner pleine puissance,
- Qu’aux discours des muguets, elle ferme l’oreille,
- Son cœur qu’avec excès, votre poursuite outrage,
- Que du don de ta foi je ne suis pas jaloux,
- Pattern 274 : <KON><DET><NOM><PRP> (total de 6 occurrences)
- Doux objet de mes vœux j’ai grand tort de crier, Et mon front de vos dons vous doit remercier.
- Et songez que les nœuds du sacré mariage
- […]. Peut-être sans raison, Me suis-je mis en tête ces visions cornues,Et les sueurs au front m’en sont trop tôt venues.
- Mais c’est peu que
l’honneur dans mon affliction, L’on me dérobe encor la réputation,
- Quand j’aurai fait le brave, et qu’un fer pour ma peine M’aura d’un vilain coup transpercé la bedaine,
- Elles font la sottise, et nous sommes les sots : C’est un vilain abus, et les gens de policeNous devraient bien régler une telle injustice.
- Pattern 438 : <NOM><PUN><KON><DET> (total de 17 occurrences)
- [à Ariste] À lui souffrir en cervelle troublée,De courir tous les bals, et les lieux d’assemblée ?
- [à Valère] Je vous l’apprends donc, et qu’il est à propos,
Que vos feux, s’il vous plaît, la laissent en repos. - [à Valère] N’a que trop de vos yeux entendu le langage ;
Que vos secrets désirs, lui sont assez connus, - [à Valère] Elle vous eût plutôt fait savoir sa pensée,
Si son cœur avait eu dans son émotion,
À qui pouvoir donner cette commission ; - [aparté] Appelons Isabelle, elle montre le fruit,
Que l’éducation dans une âme produit,
La vertu fait ses soins, et son cœur s’y consomme, - [à Isabelle] Un plein effetA suivi tes discours, et ton homme a son fait ;
- [à Valère] Qu’elle vous a fait voir assez quel est son choix,
Que son cœur tout à moi d’un tel projet s’offense, - [à Isabelle] Tous ses désirs étaient de t’obtenir pour femme,
Si les destins en moi qui captive ton cœur, - [à Ariste] On gagne les esprits par beaucoup de douceur ;
Et les soins défiants, les verrous et les grilles,
Ne font pas la vertu des femmes, ni des filles, - [à Ariste] Nous les portons au mal par tant d’austérité,
Et leur sexe demande un peu de liberté. - [à Ariste] On voit ce qu’en deux sœurs nos leçons ont produit,
L’une fuit ce galant, et l’autre le poursuit.
- – des répliques adressées à Ariste, dont les valeurs sont radicalement opposées à celles de son frère Sganarelle. La confrontation des deux personnages débouche systématiquement sur une dispute concernant l’éducation des filles, le mariage, la mode, etc. L’opposition entre les noms correspondant à la séquence (<NOM><PUN><KON><DET>), « douceur » et « austérité » (9 et 10), illustre les manières radicalement opposées dont les deux frères élèvent leur pupille.
- – des répliques adressées aux amoureux, Valère et Isabelle. Sganarelle tente de dissuader Valère de faire la cour à Isabelle en rapportant les refus de celle-ci et il se félicite ensuite de la réussite de sa démarche auprès d’Isabelle en lui rapportant les propos de Valère. Le discours de Sganarelle « entremetteur malgré lui[25] » a donc un caractère argumentatif et contient, de surcroît, des propos rapportés, ce qui explique la présence des conjonctions.
- Pattern 744 : <ADJ><NOM><PUN><PRO> (total de 12 occurrences)
- M’obliger à porter de ces petits
chapeaux,
Qui laissent éventer leurs débiles cerveaux, - Peste soit du gros bœuf,
qui pour me faire choir,
Se vient devant mes pas planter comme une perche. - Que vos secrets désirs,
lui sont assez connus,
Et que c’est vous donner des soucis superflus, - Ne t’afflige point tant, va ma petite femme,
Je m’en vais le trouver, et lui chanter sa gamme. - Voilà comme il faut que les femmes soient faites,
Et non comme j’en sais, de ces franches coquettes,
Qui s’en laissent conter […] - Hé, hé, mon petit nez, pauvre petit
bouchon,
Tu ne languiras pas longtemps, je t’en réponds, - Venez beau directeur, suranné
damoiseau,
On veut vous faire voir quelque chose de beau. - Vous l’avez bien stylée ;
Il n’est pas bon de vivre en sévère censeur,
On gagne les esprits par beaucoup de douceur ; - Pauvre esprit, je vous dis, et vous redis encor,
Les comédies-ballets : L’Amour médecin et Le Mariage forcé
| Identifiant de la séquence | Séquence | |
| 1 | Pattern 136 | <PRO><PRO><VER><SENT> |
| 2 | Pattern 107 | <PRO><VER><PRO><SENT> |
| 3 | Pattern 106 | <PRO><VER><ADV><SENT> |
| 4 | Pattern 111 | <VER><PRO><SENT> |
| 5 | Pattern 144 | <VER><VER><SENT> |
- Pattern 107 : <PRO><VER><PRO><SENT> (total de 8 occurrences)
- Hé bien, qu’est-ce ?
- Que sera-ce ?
- Qu’est-ce ?
- Qu’y a-t-il ?
- Qu’est-ce ?
- Pattern 106 : <PRO><VER><ADV><SENT> (total de 8 occurrences)
- Non, ne m’en parlez point.
- Ne m’en parlez point.
- Ne m’en parlez point.
- Pattern 144 : <VER><VER><SENT> (total de 14 occurrences)
- Je n’avais qu’une seule femme qui est morte.
- je vous prie de me conseiller tous ce que je dois faire.
- Aimerais-tu quelqu’un, et souhaiterais-tu d’être mariée ?
- Ce n’est pas la récompense de t’avoir élevée comme j’ai fait.
- Je suis perdu.
- Elle s’est jetée.
- Est-ce que les médecins font mourir ?
- je vous prie de me dire vite ce que vous avez résolu.
- Et vous suis infiniment obligé de la peine que vous avez prise.
- Il faut que j’aille chercher de l’orviétan, et que je lui fasse prendre.
- Ma fille est guérie.
- Voilà qui est fait.
| Identifiant de la séquence | Séquence | |
| 1 | Pattern 149 | <PRO><VER><SENT> |
| 2 | Pattern 34 | <NOM><PUN><KON><PRO><VER> |
| 3 | Pattern 337 | <PRP><PRO><VER><SENT> |
| 4 | Pattern 530 | <PRO><PRO><VER><PUN><KON> |
| 5 | Pattern 533 | <ADV><VER><PRO> |
- Pattern 533 : <ADV><VER><PRO> (total de 9 occurrences)
- N’ai-je pas tous les mouvements de mon corps aussi bons que jamais ?
- N’ai-je pas encore toutes mes dents les meilleures du monde ?
- Ne fais-je pas vigoureusement mes quatre repas par jour ?
- N’ai-je pas raison, d’avoir fait ce choix ?
- N’êtes-vous pas bien aise de ce mariage, mon aimable pouponne ?
- Pattern 337 : <PRP><PRO><VER><SENT> (total de 11 occurrences)
- C’est que je veux savoir de vous, si je ferai bien de me marier.
- Peut-il y avoir un homme, qui n’ait, en la voyant, des démangeaisons de se marier ?
- j’ai quelque chose à vous communiquer.
- je vous prie de m’écouter.
- elle me plaît beaucoup, et est ravie de m’épouser.
- et prenez la peine de m’écouter.
- Je viens vous dire que j’ai envie de me marier.
- Ferai-je bien, ou mal, de l’épouser ?
De faux médecins : les Sganarelle du Médecin malgré lui et du Médecin volant
| Identifiant de la séquence | Séquence | |
| 1 | Pattern 144 | <VER><KON><DET> |
| 2 | Pattern 405 | <DET><NOM><PUN><VER> |
| 3 | Pattern 194 | <PRP><VER><PUN> |
| 4 | Pattern 455 | <VER><KON><DET><NOM> |
| 5 | Pattern 730 | <PRO><VER><PUN><PRP> |
- Pattern 455 : <VER><KON><DET><NOM> (total de 11 occurrences)
- je tiens qu’un homme bien sain s’en accommoderait assez.
- je vous apprends que votre fille est muette.
- il se trouve que le poumon
- on voit que l’inégalité de leurs opinions
- vous voyez que l’ardeur
- Pattern 405 : <DET><NOM><PUN><VER> (total de 13 occurrences)
- je tiens que cet empêchement de l’action de sa langue, est causé par de certaines humeurs qu’entre nous, savants, nous appelons humeurs peccantes, peccantes, c’est-à-dire … humeurs peccantes
- on voit que l’inégalité de leurs opinions, dépend du mouvement oblique, du cercle de la lune
- et comme le soleil qui darde ses rayons sur la concavité de la terre, trouve …
| Identifiant de la séquence | Séquence | |
| 1 | Pattern 248 | <NOM><PUN><KON><PRP> |
| 2 | Pattern 212 | <NOM><PRO><VER><PRP |
| 3 | Pattern 843 | <PUN><NOM><NAM> |
| 4 | Pattern 842 | <NOM><NAM><PUN> |
| 5 | Pattern 280 | <PRP><DET><NOM><PRO> |
- Pattern 280 : <PRP><DET><NOM><PRO> (9 occurrences)
- Voilà de l’urine qui marque grande chaleur.
- parce qu’avec le goût je discerne bien mieux la cause et les suites de la maladie
- et que la bile qui se répand par le corps nous fait devenir jaunes
Le valet d’un impie : le Sganarelle du Festin de Pierre
| Identifiant de la séquence | Séquence | |
| 1 | Pattern 543 | <KON><DET><NOM><VER |
| 2 | Pattern 548 | <PUN><KON><ADV> |
| 3 | Pattern 552 | <VER><ADV><PRP><NOM> |
| 4 | Pattern 542 | <ADV><PRP><NOM><PUN> |
| 5 | Pattern 519 | <PRP><PRO><PRO> |
- Pattern 548 : <PUN><KON><ADV> (total de 14 occurrences)
- non seulement il réjouit et purge les cerveaux humains, mais encore il instruit les âmes à la vertu, et leur apprend avec lui à demeurer honnête homme.
- Je pourrais peut-être me tromper, mais enfin sur de tels sujets l’expérience m’a donné quelque lumière.
- Vous tournez les choses d’une manière qu’il semble que vous ayez raison, et cependant il est vrai que vous ne l’avez pas ;
- Osez-vous bien ainsi vous jouer du Ciel, et ne tremblez-vous point de vous moquer comme vous faites des choses les plus saintes ;
- et je leur disais que si quelqu’un leur venait dire du mal de vous, elles se gardassent bien de le croire, et ne manquassent pas de lui dire qu’il en avait menti.
- car il n’y a rien de plus vrai que le Moine bourru ; et je me ferais pendre pour celui-là ; mais encore faut-il croire quelque chose dans le monde
- Est-ce que vous vous êtes fait tout seul, et n’a-t-il pas fallu que votre père ait engrossé votre mère pour vous faire ?
- Après cela, si ne vous rendez, tant pis pour vous.
- Pattern 552 : <VER><ADV><PRP><NOM> (17 occurrences)
- vous ne croyez pas au séné […] ?
- est-il possible que vous ne croyez point du tout au Ciel ?
- vous ne croyez rien du tout
- qui n’a point de loi vit en bête brute
Conclusion
Abstract
Quantitative studies in the syntax of Molière are not very frequent. The present paper proposes a syntactic analysis of Molière’s characters that relies on the extraction of part of speech sequences and their filtering using correspondence analysis. In particular, the methodology is applied to the study of the evolution of the character of Sganarelle, appearing in several of Molière’s plays in prose and verse, and often reflecting the prototype of the “bourgeois de Paris”, who isn’t attuned to the new society of the young reign of Louis XIV, the “mondains”. The analysis of the results is carried out with a register perspective, with the aim of identifying syntactic patterns that characterize the different Sganarelles with respect to the type of context in which they find themselves in the different plays. The results show how the evolution of the character can be traced from his first appearance to his later uses by Molière.
Note on Translation
Notes
Works Cited

Comments: dhqinfo@digitalhumanities.org
Published by: The Alliance of Digital Humanities Organizations and The Association for Computers and the Humanities
Affiliated with: Digital Scholarship in the Humanities
DHQ has been made possible in part by the National Endowment for the Humanities.
Copyright © 2005 -

Unless otherwise noted, the DHQ web site and all DHQ published content are published under a Creative Commons Attribution-NoDerivatives 4.0 International License. Individual articles may carry a more permissive license, as described in the footer for the individual article, and in the article’s metadata.
