



Volume 12 Number 1
La conquista de Jerusalén ¿de Cervantes? Análisis estilométrico sobre autoría en el teatro del Siglo de Oro español
The Conquest of Jerusalem: by Cervantes? Stylometric analysis on authorship in the Golden Age Spanish theater
Abstract
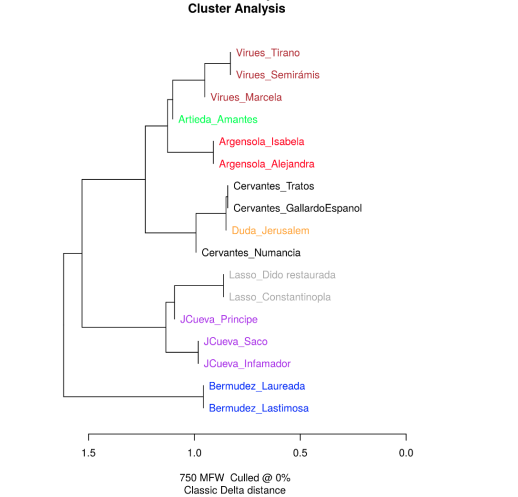
En este artículo aplicamos métodos estilométricos para abordar el problema de autoría de la comedia La conquista de Jerusalén, atribuida desde su descubrimiento a Miguel de Cervantes. Para ello hemos realizado numerosos análisis con diferentes rangos de palabras, en un total de diecisiete textos teatrales escritos, todos ellos, por los siete autores que conforman la generación teatral de 1580 y cuya actividad dramática coincide en el tiempo con la composición de La conquista. Hemos utilizado la unidad de distancia textual Delta para agrupar (cluster) los textos.
1. Introducción
2. Discusión sobre la autoría de La conquista de Jerusalén
3. Preparación del corpus y metodología
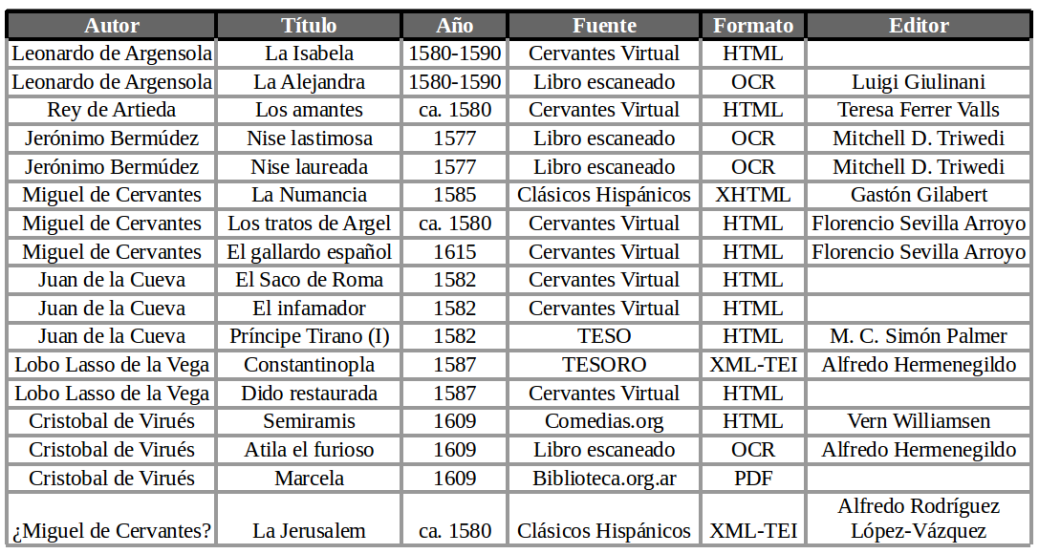
3.1. Diseño y preparación del corpus de textos
- Tres textos por autor: cada autor señalado como posible autor de la obra analizada esté representado por tres textos[6]
- Subgénero: al ser La conquista de Jerusalén una comedia, hemos dado preferencia a aquellas obras que pertenezcan a este mismo subgénero
- Datación: hemos dado prioridad a aquellas obras que se presupone que fueron escritas en la misma época que la obra analizada, es decir, alrededor de 1580
- Digitalización: comprensiblemente hemos utilizado aquellos textos que encontramos digitalizados a aquellos que no[7]
- Se han actualizado todos los grupos consonánticos cultos, tales como –ct– (auctor), –sc– (esclarescer), –pr– (propia), –ch– (christianos), –ph– (esphera), –pt– (captivo).
- Se ha corregido según norma actual el uso vacilante de –b– y –v–. De la misma forma, se ha actualizado el uso indiscriminado tanto de –u– con valor consonántico (tuuieren), como de –v– con valor vocálico (avto).
- Simplificación de reduplicaciones gráficas que no respondan a necesidades ortográficas actuales, tales como –ss– (tuviesse), –cc– (succeso) y –rr– (honrra).
- Sustitución de la grafía –ç– por –c– o –z– según norma ortográfica actual (coraçón).
- Se ha sustituido –q– por –c– según precisa la norma ortográfica actual (quanto).
- Se ha sustituido –x– por –j– según precisa la norma ortográfica actual (lexos).
- Actualización gráfica de nombres propios (Ynés, Portogal, Galiçia, etc.).
- Se han corregido todas las interjecciones exclamativas (O - Oh; Ai - Ay).
- Se han respetado las formas contraídas dello, desto y aquesto con el fin de no afectar al comportamiento métrico de la obra.
- Asimismo se ha respetado la forma antigua infinitivo+pronombre (decilla, matallo).
3.2. Discusión sobre el método y los parámetros
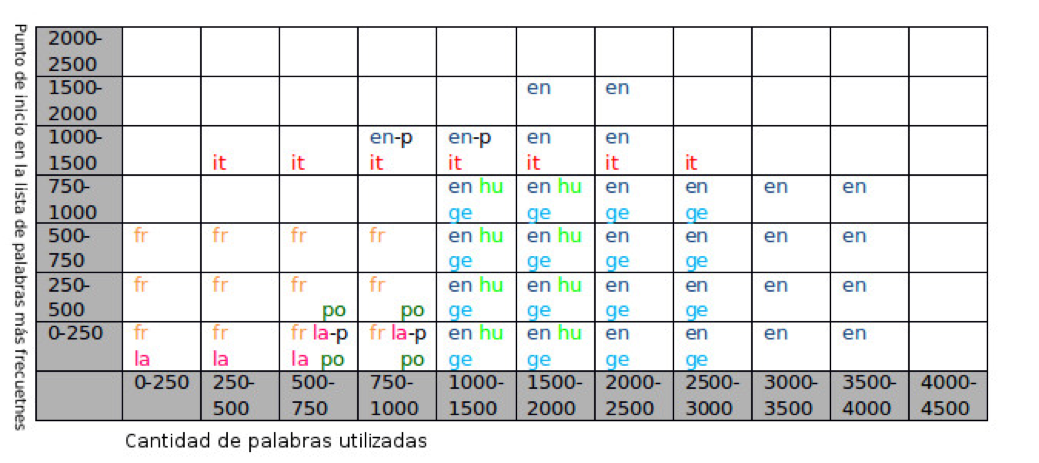
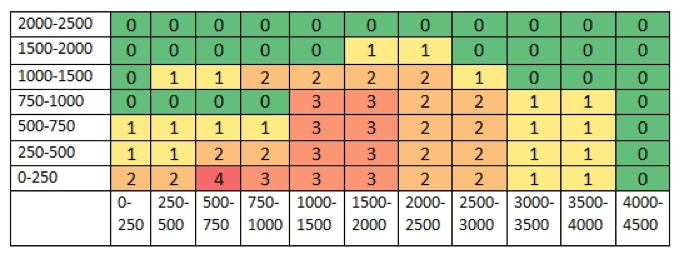
4. Resultados y comparación de resultados
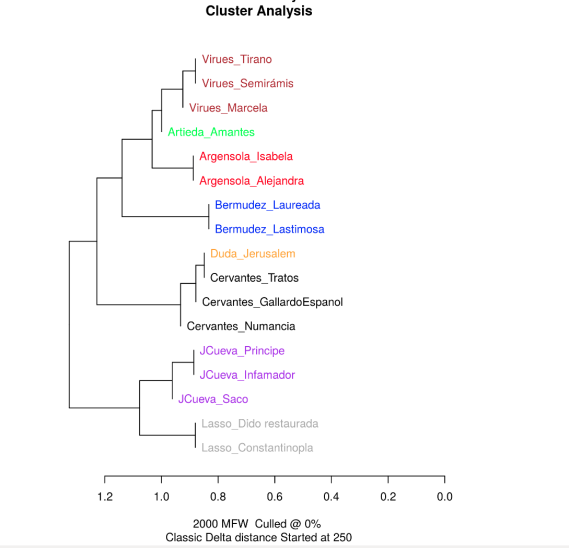
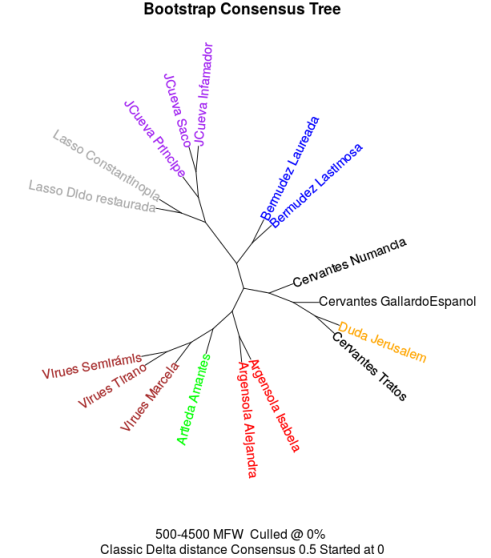
- ¿Cuántos de los rangos organizan La conquista de Jerusalén con los textos cervantinos?
- Ignorando el texto de La conquista de Jerusalén, ¿cuántos autores son correctamente reconocidos en cada rango?
- 3: los textos de Cervantes y el discutido aparecen en una rama juntos y aislados
- 2: los textos de Cervantes y el discutido aparecen en una rama juntos pero otro texto de otro autor aparece en la rama
- 1: algunos textos de Cervantes y el discutido aparecen en una rama (aislados de otros autores o no)
- 0: el texto discutido aparece relacionado con un autor diferente a Cervantes
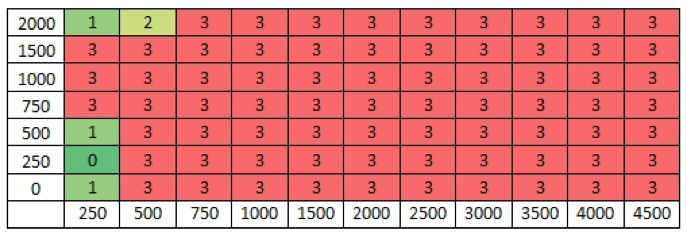
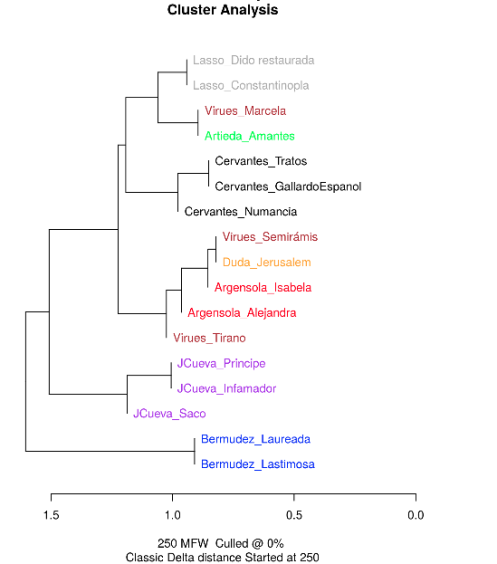
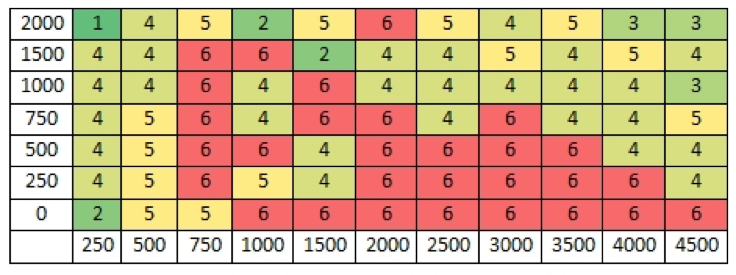
- Se observan resultados pobres al eliminar las 2000 palabras más frecuentes.
- Los rangos hasta 250 y 500 palabras (eliminando o no algunas de las palabras más frecuentes) no parecen suficientes para analizar autoría.
- Se observan rangos óptimos utilizando las palabras más frecuentes sin eliminar ninguna.
- También aparecen rangos óptimos entre 1500 y 4000 palabras, eliminando hasta 500 palabras más frecuentes.
5. Conclusión y futuro trabajo
Abstract
In this article we apply stylometric methods to approach the authorship problem of the comedy La conquista de Jerusalén, attributed since its discovery to Miguel de Cervantes. For this purpose we have performed numerous analyses with different range of most frequent words in a total of seventeen theater plays, all of them written by the seven authors that define the generación teatral de 1580 and who wrote plays actively when La conquista was composed. We have used the distant measure Delta to cluster the text.
Note on Translation
Notes
Works Cited
Recommendations
DHQ is testing out three new article recommendation methods! Please explore the links below to find articles that are related in different ways to the one you just read. We are interested in how these methods work for readers—if you would like to share feedback with us, please complete our short evaluation survey. You can also visit our documentation for these recommendation methods to learn more.
SPECTER Recommendations
Below are article recommendations generated by the SPECTER model:
- Introduction, 2011, Mauro Carassai, University of Florida; Elisabet Takehana, Fitchburg State University
- J. M. Coetzee's Work in Stylostatistics, 2014, Peter Johnston, Royal Holloway, University of London
- Geografías digitales: Iluminando las relaciones espaciales en una colección de blogs literarios, 2018, Cecily Raynor, McGill University
- Apresentação - Edição especial da DHQ em português, 2020, Luis Ferla, Universidade Federal de São Paulo; Cecily Raynor, Universidade McGill
- The Voices of Doctor Who – How Stylometry Can be Useful in Revealing New Information About TV Series, 2020, Joanna Byszuk, Institute of Polish Language, Polish Academy of Sciences
DHQ Keyword Recommendations
Below are article recommendations generated by DHQ Keywords:
- Retorno a trazos de mil historias, 2018, Suzana Sukovic, HETI (Health Education and Training Institute); Peter Read, Australian National University
- Les Sganarelle de Molière : un nom, des syntaxes ?, 2018, Élodie Bénard, Université Paris-Sorbonne; Francesca Frontini, Université Paul Valéry Montpellier
- DH for History Students: A Case Study at the Facultad de Filosofía y Letras (National Autonomous University of Mexico), 2017, Adriana Álvarez Sánchez, National Autonomous University of Mexico; Miriam Peña Pimentel, National Autonomous University of Mexico
- Modeling Amerindian Sea Travel in the Early Colonial Caribbean, 2020, Emma Slayton, Carnegie Mellon University
- Mining Embodied Emotions: A Comparative Analysis of Sentiment and Emotion in Dutch Texts, 1600-1800., 2018, Inger Leemans, Faculty of Humanities, Vrije Universiteit Amsterdam, The Netherlands; Janneke M. van der Zwaan, Netherlands eScience Center, Amsterdam, The Netherlands; Isa Maks, Faculty of Humanities, Vrije Universiteit Amsterdam, The Netherlands; Erika Kuijpers, Faculty of Humanities, Vrije Universiteit, Amsterdam, The Netherlands; Kristine Steenbergh, Faculty of Humanities, Vrije Universiteit, Amsterdam, The Netherlands
TF-IDF Recommendations
Below are article recommendations generated by the TF-IDF Model:
- Geografías digitales: Iluminando las relaciones espaciales en una colección de blogs literarios, 2018, Cecily Raynor, McGill University
- El Catálogo Colectivo de Marcas de Fuego. Avatares para conformar su canon de autoridades, 2020, Mercedes I. Salomón Salazar, México - Biblioteca Histórica José María Lafragua; Benemérita Universidad Autónoma de Puebla
- Retorno a trazos de mil historias, 2018, Suzana Sukovic, HETI (Health Education and Training Institute); Peter Read, Australian National University
- Introducción de los editores, 2018, Ernesto Priani Saiso, Universidad Nacional Autónoma de México (UNAM); Elena Gonzalez-Blanco García, Universidad Nacional de Educación a Distancia (UNED)
- Cartografías de la sociedad red, 2018, Paulo Antonio Gatica Cote, Universidad de Salamanca

Comments: dhqinfo@digitalhumanities.org
Published by: The Alliance of Digital Humanities Organizations and The Association for Computers and the Humanities
Affiliated with: Digital Scholarship in the Humanities
DHQ has been made possible in part by the National Endowment for the Humanities.
Copyright © 2005 - 2025

Unless otherwise noted, the DHQ web site and all DHQ published content are published under a Creative Commons Attribution-NoDerivatives 4.0 International License. Individual articles may carry a more permissive license, as described in the footer for the individual article, and in the article’s metadata.
