Abstract
This article presents a new model for emotion mining, resulting from the research
project “Embodied Emotions”. This project aims: 1. to trace
historical changes in emotion expression and in the embodiment of emotions, and
2. to develop methods to trace these changes in sizeable corpuses of digitized
texts. Up to now, the mining of sentiments or emotions has mainly been
restricted to modern, or even very recent text corpora, such as social media.
Sentiment mining techniques are often based on relatively simple emotion models
of binary (positive/negative) oppositions, or limited sets of ‘basic’ emotions
and are not yet able to deal adequately with the complexity and the historical
contingency of emotions and their expression. To meet these challenges, we have
developed the Historic Embodied Emotion Model (HEEM), built on a test case of 29
Dutch language theatre plays written between 1600 and 1800 and annotated
manually with HEEM labels for emotions and body terms. In this article, we
present this model and compare it with other sentiment mining techniques: 1) off
the shelf linguistic analysis software LIWC (Linguistic Inquiry and Word Count),
2) a version of LIWC that has been adapted for the analysis of Dutch historical
texts, 3) a new Dutch translation of WordNetAffect. We conclude that, although
different forms of sentiment mining have their value and use, HEEM provides new
opportunities for emotion mining and analysis of embodied emotions in historical
texts.
1. Introduction: combining the affective and digital turns
Over the last decade, sentiment and opinion mining have become important fields
of research, both within academia and for companies and organizations that have
started to utilize this information for reputation management and marketing
purposes. Many techniques and resources, e.g. Sentiwordnet [
Baccianella et al. 2010], Harvard General Inquirer Database [
Stone et al. 1996], Liu’s Opinion Lexicon [
Liu 2015], focus
on single word mining of overall sentiment (thumbs up/down) or coarse-grained
opinions in contemporary language. Research conducted with these lexicons tends
to suffer from “short-termism”: the data analyzed is often
limited to recent, short time periods, with a bias towards social media.
Historians are interested in long-term developments, e.g. in opinion and emotion
expressions across time. Historians stress that the experience and expression of
emotions is subject to social and cultural changes [
Frevert 2014].
However, to date, sentiment mining techniques are not able to deal adequately
with the complexity and the historical contingency of emotions and their
expression. They focus on explicit utterances of emotions (I am angry), and
ignore the fact that the body is an important vessel for emotion communication.
Human emotions are a complex of neuro-physical, social and cultural actions and
reactions. They are expressed not only in words but also in gestures, facial
expressions and physical reactions.
Over the last years, emotions and their history have become a focus point for
research [
Rosenwein 2002]
[
Boddice 2014]
[
Frevert 2014]
[
Matt and Stearns 2013]
[
Plamper 2015]. Centers for emotion studies were founded in
Berlin, London, Australia, France, and Amsterdam, specialized journals (e.g.
Emotion Review) and discussion forums provide
platforms for emotion researchers (e.g. H-EMOTIONS, EMONET-L, HIST-EMOTION). The
cultural and historical complexity of emotions has been analyzed in a multitude
of studies, providing insight in the complex relations between mind and body, in
the constantly changing vocabularies used to address emotions, and in the
changeable appraisal of emotions. However, up to now, most of the (historical)
research in emotion studies relies mainly on traditional hermeneutical methods
of research [
Leemans 2017] (for examples of historical sentiment
mining see e.g. [
Sprugnoli et al. 2016]).
In our project, we aim to test existing sentiment mining techniques for their
capacity to analyze emotion expression in previous ages, and to develop an
enriched form of sentiment mining based on an “embodied emotions
model” that is capable of tracing historical changes in the verbal
and bodily expression of emotions over time.
To analyze the emotional practices of the past, we chose to focus on Dutch
language theater texts of the early modern period (1600-1800). Theatre texts are
rich sources for emotion research since staging emotions is one of the main
goals of this genre. Characters tend to be very explicit in indicating their
feelings, while stage directions and speech lines give us information about the
bodily enactment of emotions. Although the communication on stage seems to have
little in common with daily speech, the way emotions were described, expressed
and enacted nonetheless appealed to a very large audience that apparently
recognized and immersed itself in the tribulations and emotions of the
characters.
Theater texts offer an excellent case to explore the possibilities of historical
emotion mining over a longer period as it is one of the oldest literary genres
that remained popular over centuries. Moreover, the two hundred years between
1600 and 1800 witnessed fundamental changes in emotional culture and the
enactment of emotions on stage. During the 18th century, the classic view on
“passions” as highly embodied, strong and threatening
impulses waned and a more positive appreciation of the senses and sensibility as
source of human knowledge and morality came to the fore. New theatre forms, e.g.
the bourgeois tragedy or the “Comédie Larmoyante”, replaced
the traditional fierce passions from the tragedy – such as anger, revenge,
remorse, shame and despair with “smaller” emotions or
“sentiments” such as sadness, infatuation, bliss and
sensibility [
Leemans and Johannes 2013]. The medical conception of the humoral
system considered the condition of the blood, phlegm, yellow bile and black bile
as of great influence on emotional health [
Plamper 2015]. This
view remained dominant throughout the seventeenth and eighteenth centuries but
at the same time new medical theories came to the fore. The presumed physical
determinants of emotional wellbeing seem to have shifted gradually from the
bodily fluids to the nerves, the muscles and the skin [
Plamper 2015]
[
Frevert 2014]
[
Dixon 2003]. Although we expect that with these migrations, the
bodily expressions of emotions changed as well, systematic research into this
change is still lacking.
Within the Dutch language area, hardly any digital research has been conducted
into the history of emotions, nor into early modern theatrical or literary
culture. Current text, concept or sentiment mining projects tend to focus on
20th- and 21st-century data sets, e.g. social media, newspapers, journals, or
novels (see e.g. [
Wevers 2017]
[
Eijnatten et al. 2014]
[
Pander Maat et al. 2014]
[
Dalen-Oskam 2013]
[
Vossen et al. 2013]. For the 19th century, Dutch biographical datasets
have been sources for digital textual research that extracted biographical
information and conceptualizing “events” from these datasets
[
Braake and Fokkens 2015].
For the early modern period, the ePistolarium project is one of the few projects
researching textual culture in the Dutch language with computational tools.
ePistolarium provides a web application that allows users to browse through
20.000 digitized letters from Dutch scholars and from scientists who stayed in
the Dutch Republic during the 17th century. This letter collection has been the
base for exploratory topic modeling [
Wittek and Ravenek 2011]. So, while
digital research into Dutch language texts is developing rapidly, our work on
early modern Dutch literary texts opens up fresh territory.
One of the reasons for the delayed employment of digital research tools by
researchers of early modern history is that current text mining tools developed
for modern language texts do not work well for older texts as vocabulary,
meaning and spelling altered importantly over time. Moreover, spelling in early
modern texts is highly inconsistent. For early modern texts, lexicons or
classification schemes of emotions are not available.
2. Development of Historical Embodied Emotions Model (HEEM)
For the corpus selection of this project, we collaborated with DBNL (Digital
Library of Dutch Literature) and with Nederlab - a project that aims to provide
online access to all digitized Dutch language texts since the Middle Ages. We
selected 280 theatre texts from the period 1600-1800, representing different
periods (Renaissance 1600-1669, Classicism 1670-1749, Enlightenment 1750-1800)
and different genres (tragedies, comedies and farces). Most of the theatre texts
were xml represented according to TEI standards (
http://www.tei-c.org), so we could
differentiate between scenes, characters, speaker turns, and stage
directions.
We selected 29 texts from our corpus of 280 plays to annotate manually. The
selection ensured coverage of different theatre genres (tragedy, comedy, farce),
and different periods. We converted the TEI XML files into Folia and used the
KAF annotator for our annotation process.
[1]
This set of annotated files is employed in different ways. First of all, as it is
a representative sample of the entire HEEM-corpus, it provides preliminary
answers for our research questions concerning the changes in emotion expression
over time. Furthermore, it serves as a test and training set for the development
of machine learning methods aiming at automatically annotating the entire corpus
of 280 plays. The results of this process will be the subject of a later
publication. In this article, we present the results of the model development on
the basis of the 29-corpus. We will use this model and corpus as a test set for
comparisons with other sentiment mining methods.
2.1. HEEM annotation guidelines
In our project we distinguished emotions from related categories such as
mood, trait, cognitive state, physical state, edonic state, attitude and
sensation (cf. WordNet-Affect - [
Strapparava and Valitutti 2004]). We
decided to focus on emotions proper, although the adjacent category of
“moods” turned out to be hardly distinguishable from
emotions in some cases. Additionally, we adopted the definition of emotions
by Klaus Scherer who defines an emotion as a strong feeling deriving from
one’s circumstances or relationships with others involving cognitive
appraisal, bodily symptoms, (a readiness for) action, motoric expression
(for instance in face or voice) and subjective awareness [
Scherer 2005, 697, 703–5]. Besides emotions we are also
interested in the simultaneous occurrence of bodily reactions. In total, we
developed five annotation categories (Table 1).
In the annotation guidelines we further defined the five categories and
provided lists of examples (see HEEM-Github for more detailed information).
Starting from these definitions and after a preliminary exploration of a
subset of corpus texts, we composed a list of 37 emotions relevant for the
interpretation of early modern theatre texts (Table 2).
| CONCEPT TYPE |
EXPLANATION |
ILLUSTRATION |
| Emotion |
Strong feeling deriving from one’s circumstances or relationships
with others involving cognitive appraisal, bodily symptoms, (a
readiness for) action, motorical expression and subjective
awareness |
weerzin (aversion), haten (to loathe),
verliefd (in love), verdrietig
(sad) |
| Body part |
Internal and external parts of the body |
gezicht (face), spieren (muscles), bloed
(blood), geest (mind), ogen
(eyes) |
| Bodily process |
(uncontrollable) reactions of the body coinciding with
emotions |
huilen (cry), zuchten (sigh, moan),
blozen (blush), rillen (tremble) |
| Emotional action |
(controllable) human action triggered by an emotion |
schelden (scold), in de armen sluiten
(embrace), honen (scorn), smeken
(beg) |
| Body sensation |
Sensations and perception of temperatures, tastes, smells,
vibrations and movements in the body associated with emotional
experience |
warm (warm), koud (cold), bitter
(bitter), droog (dry), samentrekkend
(contracting) |
Table 1.
HEEM Emotional Concepts
| Anger (Woede); Annoyance (Wrevel); Acquiescence (Berusting); Awe
(Ontzag); Benevolence (Welwillendheid); Compassion (Mededogen);
Dedication (Toewijding); Desire (Verlangen); Despair (Wanhoop);
Disappointment (Teleurstelling); Disgust (Walging); Envy (Jaloezie);
Fear (Angst); Feeling of loss (Gemis); Greed (Hebzucht); Happiness
(Geluk); Hatred (Haat); Heavy-heartedness (Bedruktheid); Honor
(Eergevoel); Hope (Hoop); Joy (Blijdschap); Love (Liefde); Loyalty
(Trouw); Moved (Ontroerd); Offended (Beledigd); Pride (Trots);
Relief (Opluchting); Remorse (Wroeging); Sadness (Verdriet); Shame
(Schaamte); Spitefulness (Wrok); Suspicion (Achterdocht); Trust
(Vertrouwen); Unhappiness (Ongelukkig); Vindictiveness (Wraakzucht);
Wonder (Verwondering); Worry (Bezorgheid); |
Table 2.
HEEM emotion categories (37)
Words were annotated and interpreted in context, which means that a
polysemous word like the Dutch noun “hoop” which has two
meanings (heap and hope) will only be identified
if it is used in its second meaning. Likewise, body related concepts, i.e.
body parts, bodily processes and body sensations, are only identified if
they are involved in an emotion expressed in the text. In the case of bodily
processes, for instance, the reaction must be triggered by an emotion and
not by any other phenomenon. For example, trembling is
annotated in a sentence such as she trembles with anger, but is
not annotated in: she trembles from the cold.
Each annotated concept is classified into one of the 37 classes of the HEEM
emotion classification. Consider, for example, the following sentence and
its annotations: Ex. (1) “Ik kreeg van haar daar zulk gekyf; / Dat noch
het hart beefd in me lyf” (“She scolded at me so terribly that my
heart is still trembling in my body”). The word
“gekyf” (scolding) can be identified as
an emotional action and linked to the emotion class Anger.
“Hart” (heart) is annotated as a body
part and, in this case, linked to the emotion class Fear. Likewise, “beefd
in me lyf” (tremble in my body / breast) is
identified as Bodily Process and also linked to the emotion class Fear. In
the annotations, no distinction was made between the references to body
parts or bodily processes in a literal and a metaphorical sense. The reason
for this decision was that such a distinction is often quite difficult to
make in early modern texts, where expressions which we now consider to be
metaphorical often had a quite material basis in humoral theories of the
passions.
2.2. Inter-annotator study
The annotation was performed by a group of experienced readers of early
modern Dutch (theatre) texts. An inter-annotator study was carried out to
check the consistency and reliability of the annotations. Five annotators
annotated independently 2 documents with a total of approx. 1100 sentences.
Agreement is calculated following the metric
agr as proposed by
[
Wiebe et al. 2005] and [
Read and Carroll 2010], who calculate
agreement on similar data. This metric calculates pair-wise agreement by
first measuring precision of annotator A’s annotations on B’s annotations,
and then measuring precision of annotator B’s annotations on annotator A’s
annotations. Agreement between 2 annotators is the mean of the 2 scores. We
only report overall agreement (Table 3 and 4), which is the mean of the
pair-wise scores.
One of the problems of these kinds of annotations is that different
annotators are likely to choose different unit lengths while marking up what
is essentially the same. If we consider again example (1), we cannot know
whether an annotator identifies only the word “beefd”
(trembles) or whether he considers the whole sentence
(“het hart beefd in me lyf”) as a Bodily Process. We
took a lenient approach and considered an overlap of one word as
matching.
|
OVERALL |
| Emotion |
.73 |
| Body part |
.73 |
| Bodily process |
.47 |
| Emotional action |
.30 |
| Sensation |
.61 |
Table 3.
Overall agreement on HEEM concepts in percentages
We first measured agreement on the identification of the different concept
types in text. Table 3 shows that the concept types Emotion, Body Part and
to a lesser extent Sensation are reliably identifiable, with overall scores
of 73, 73 and 61%, respectively. Bodily Processes and Emotional Actions,
however, have low agreement scores, which do not allow for definite
conclusions. On the basis of these results we decided to drop the categories
Emotional Action and Bodily Process for our model development. The lack of
agreement in these two categories is caused by the fact that some annotators
tended to include more expressions than others. Plays are literary texts
that artistically play with words and that are larded with metaphors. In the
following sentence body part and emotion are easy to identify: “Wat
nevel van verdriet bezwalkte uw blinckende ogen” (What
haze of sorrow drapes your gleaming eyes). There is sorrow
connected to the eyes, but what exactly happens to the eyes? And should that
be taken literally? We agreed to take metaphors and expressions literally
even though it could be a literary construction and thus that a phrase like
this should be tagged as the description of a bodily process. Nonetheless
this type of “bodily processes” could be easily
overlooked.
We also measured agreement on the classifications of emotions into one of the
specific HEEM emotion categories. On this task the annotators achieved an
agreement of 85%. The numbers show that the identification of emotions
(0.73) is harder than their classification into subcategories once the
expressions are identified (0.85).
3. Adapting LIWC and WordNetAffect for historical emotion mining
3.1. LIWC
While we were developing HEEM, we also started experimenting with
off-the-shelf sentiment mining tools. We chose Linguistic Inquiry and Word
Count (LIWC) as the most promising sentiment and embodiment mining technique
for further exploration. LIWC is a text analysis software program, which
provides a simple but effective way of measuring tendency and strength of
emotions (and other psychological properties) in text [
Pennebaker et al. 2001]
[
Pennebaker et al. 2015]. The LIWC dictionary was translated into
Dutch and tested by Dutch social scientists [
Zijlstra et al. 2004].
[2]
The LIWC software processes each word of a text by searching for matches with
a categorized dictionary, including around 4,500 words and word stems. As
the software is developed by and for psychologists, it provides lists of
words on wellbeing, affect, cognition, biological processes, social
practices, and some specific emotions, e.g. anger, anxiety, sadness [
Tausczik and Pennebaker 2010]
[
Kahn et al. 2007].
[3] The categories Posemo and Negemo
cover a broad range of terms that express positive and negative
appreciations and sentiments including adjectives and adverbs like
nice or
edgy, as well as states or situations
that could allude to moods or indicate positive or negative appraisal such
as
alone or
gloomy. See Table 4 for an example of
some of the calculations of LIWC on an early modern Dutch theatre text:
Achilles by Balthazar Huydecoper (1719). We
will analyze the results of this table later in this paper. But first, we
need to discuss the reliability of LIWC for researching early modern
texts.
|
LIWC |
|
HD-LIWC |
|
| Category |
% |
Freq. |
% |
Freq. |
| We |
0.56 |
98 |
0.91 |
161 |
| You |
2.55 |
449 |
2.98 |
525 |
| I |
1.64 |
290 |
4.86 |
856 |
| Negemo |
2.67 |
470 |
4.78 |
843 |
| Posemo |
2.23 |
394 |
3.51 |
618 |
| Posfeel |
0.39 |
69 |
0.59 |
104 |
| Anger |
0.75 |
132 |
1.93 |
341 |
| Anxiety |
0.64 |
113 |
0.90 |
159 |
| Sad |
0.90 |
159 |
1.36 |
240 |
| Physical |
1,33 |
235 |
3,05 |
538 |
| Body |
1.33 |
235 |
2.38 |
420 |
| Death |
0.38 |
67 |
0.48 |
84 |
| Social |
6.17 |
1087 |
10.00 |
1763 |
| Sports |
0.01 |
1 |
0.01 |
2 |
| Swear |
0.00 |
0 |
0.00 |
0 |
| TV |
0.01 |
2 |
0.02 |
4 |
Table 4.
Examples of LIWC weighted categories of B. Huydecoper,
Achilles (1719). Total # of words =
17,631
LIWC has been previously applied on historical data sets, without an
evaluation of the performance of the software [
Borowiecki 2013]
[
Leemans and Johannes 2013]. As LIWC is designed for modern texts, it
underperforms in historical texts. To diminish this problem, we extended the
Dutch LIWC dictionary with historical data by linking it to GiGaNT, a
lexicon service provided by the INL (INL Lexicon Service). GiGaNT offers
spelling and word variants of Dutch language, from the 15th to the 20th
century. We used a subset covering the period from 1600-1800. The
“historical Dutch LIWC” (HD-LIWC) was created by
adding spelling variants for all words to the original Dutch LIWC (cf. the
spelling normalization procedure applied in [
Zwaan et al. 2015]). The
original Dutch LIWC dictionary contains 6,512 terms, while the HD-LIWC
contains 8,757 terms. Table 5 shows that most historical terms map
unambiguously to a single modern variant (96%). For historical terms that
mapped to multiple modern variants, a single variant was selected randomly.
| #Mappings |
#Historical terms |
Percentage |
| 1 |
8021 |
96,08 |
| 2 |
706 |
3,76 |
| 3 |
27 |
0,14 |
| 4 |
3 |
0,02 |
Table 5.
The number of mappings to modern term in the historical Dutch LIWC
dictionary.
Applying the “historical Dutch LIWC” (HD-LIWC) to our
corpus resulted in higher coverage as more words were labeled with one or
more LIWC categories. Table 4 shows percentages of words found for the
positive emotions (Posemo), Negative emotions (Negemo), and Body categories
using the original Dutch LIWC and HD-LIWC in one selected play: Achilles by Balthasar Huydecoper (1719). However,
the higher percentages achieved by HD-LIWC must be interpreted with care,
because our method of developing HD-LIWC introduced noise into the list. We
identified three types of noise that were introduced. First, for historical
words that map to multiple modern alternatives, one alternative was selected
at random. For example, the historical term “vreed” is a
spelling variant of both “vrede” (peace) and
“wreed” (cruel). In the historical LIWC,
“vreed” only maps to “vrede”, the
meaning of “vreed” as “wreed” is
missed. The second source of noise is caused by the way in which the
LexiconService returns spelling variants for verbs. Regardless of the tense
of the verb entered, the LexiconService returns spelling variants in all
tenses. This means that LIWC categories Present and Past are unreliable and
should not be used. The third source of noise is introduced by
inconsistencies in GiGaNT/the LexiconService. For example, the term
“gehoond” (mocked) is retrieved as a
spelling variant of “gezond” (healthy) and
counted in the LIWC category Body, where it obviously does not belong.
3.2. WordNetAffect
As an experiment, we also compiled another emotion wordlist for Dutch based
on the English resource WordNetAffect [
Strapparava and Valitutti 2004].
WordNetAffect is built as an extra layer on the Princeton WordNet [
Fellbaum 1998] semi-automatically labeling each set of
synonyms with a so-called affect type (such as mood, trait, emotion,
behavior, etc.). Part of these synsets is additionally labeled with a set of
fine-grained emotion classes such as anger, fear, disgust, etc. We
transferred these labels from the Princeton WordNet to the Dutch WordNet
[
Vossen et al. 2008] using the equivalent links between the two
WordNets. We then selected the words labeled with the affect type
“emotion” and expanded the set with historic variants
adopting the same strategy as followed for the historical version of LIWC.
For the tests presented in this paper we did not take into consideration the
fine-grained emotion classification.
The result in numbers are presented in Table 6. As this resource is
automatically generated it includes also incorrect labels or omissions
mainly due to erroneous or missing equivalent links or even to the fact that
the original English resource has been built also in a partly automatic way.
| Dutch WNAffect |
Flectional variants |
Historical variants |
| 2315 |
5215 |
15618 |
Table 6.
The number entries Dutch D-WNaffect (modern and historical)
4. Comparing HEEM with D-LIWC and D-WNAffect
In this section, we will present a quantitative comparison between HEEM
annotations and the four wordlists: the Dutch version of LIWC (D-LIWC), the
historical Dutch version of LIWC (HD-LIWC), the Dutch version of WordNetAffect
(D-WNAffect) and the historical Dutch version of WordNetAffet (HD-WNAffect). To
be able to perform the comparisons, we merged the LIWC classes ‘posemo’ and
‘negemo’ into one single class ‘emotion’ and compared the result with the HEEM
emotion classes. Additionally, we compared the LIWC class ‘Body’ with the HEEM
class ‘Lichaamsdeel’ (Emotion related Body part).
The results in absolute numbers can be seen in Table 7. The numbers of HEEM
entities differ considerably from the numbers identified by both D-LIWC and
HD-LIWC, which is caused by the broad definition of the LIWC categories of
emotions and body related terms compared to the corresponding HEEM classes. We
also see that HD-LIWC has higher coverage than LIWC.
|
HEEM |
D-LIWC |
HD-LIWC |
D-WNAffect |
HD-WNAffect |
| Emotions |
3730 |
11550 |
22349 |
9694 |
17948 |
| Body parts |
826 |
3369 |
6714 |
- |
- |
Table 7.
Number of entities found in the 29 HEEM texts
|
|
LIWC |
HD-LIWC |
D-WNAffect |
HD-WNAffect |
| Emotions |
precision |
0.13 |
0.10 |
0.19 |
0.13 |
|
recall |
0.41 |
0.60 |
0.49 |
0.64 |
|
F-measure |
0.20 |
0.17 |
0.27 |
0.22 |
| Body parts |
precision |
0.11 |
0.74 |
- |
- |
|
recall |
0.44 |
0.60 |
- |
- |
|
F-measure |
|
|
|
|
Table 8.
Precision and recall of HD-LIWC and D-LIWC on HEEM
We established the precision of D-LIWC in finding emotions and body parts when
compared to the manual annotations of HEEM. Here precision indicates how many
entities found by D-LIWC and HD-LIWC are also identified as emotions or body
parts by HEEM. Table 8 shows that only 13,5% and 10.1% of the words identified
as emotions by D-LIWC and HD-LIWC, respectively, are labeled as emotions by
HEEM. Likewise, only 10.9% and 7.4% of the body terms identified by D-LIWC and
HD-LIWC are listed by HEEM as emotion related body parts.
The low precision score is illustrative for the difference between sentiment
mining (LIWC), which returns a wide variety of opinions and affective
expressions and the manual expert annotations according to the model developed
for HEEM, which is very precise and more restrictive in its identification of
emotion words and terms for body parts involved in the embodiment and expression
of emotions.
Recall scores measure how many words have not been found by D-LIWC and HD-LIWC
when compared to HEEM. The score of 60,2% for the recall on emotions implies
that still 40% of the emotion words in the 29 plays were not found by the
historicized LIWC. HD-LIWC gives higher recall than the D-LIWC but its lower
precision scores uncover that the noise introduced by the extra words is
substantial.
4.1. Emotions or sentiments
The tables 9, 10 and 11 present correctly found, and missed emotion words,
and words that HD-LIWC counts, but HEEM ignores. These lists provide insight
into the way HEEM works in comparison to D-LIWC and HD-LIWC. Table 9 shows
the most frequent words correctly found by HD-LIWC. The words in bold such
as “vreezen” (fear),
“vreugd” (joy) and
“spyt” (reget) are historical variants
of emotion words that are correctly found by HD-LIWC, and that are missed by
D-LIWC. Table 10 shows the most frequent words that are still missed by
HD-LIWC. Many words such as “gramschap”
(anger), “toorn” (anger)
“min” (love),
“minnen” (to love), and
“mededogen” (compassion) are archaic
emotion words that are no longer in everyday use or even obsolete. These
words are not included in the HD-LIWC as they are not variants of
contemporaneous words with an affective meaning. It also shows that some
historical form variants are still lacking in HD-LIWC (e.g.
“jalouzij” (envy),
“lijefd” (love),
“liefd” (love),
“haaten” (hate) etc.) although their
modern counterparts (i.e. “jaloezie”,
“liefde” and “haten”) are present
in D-LIWC.
| liefde |
love |
160 |
| vrees |
fear |
128 |
| haat |
hate |
94 |
| hoop |
hope |
91 |
| wraak |
revenge |
72 |
| vreugd |
joy |
71 |
| verdriet |
sadness |
58 |
| schrik |
fear/shock |
56 |
| vreezen |
fear |
52 |
| wanhoop |
despair |
45 |
| eer |
honour |
42 |
| geluk |
happiness |
39 |
| vreugde |
joy |
37 |
| spyt |
remorse |
36 |
| droefheid |
sadness |
31 |
| wraeck |
revenge |
30 |
| vreest |
fears |
26 |
| woede |
anger |
26 |
| trouw |
fidelity |
25 |
| angst |
fear |
23 |
| lust |
desire |
22 |
| bemint |
loves |
21 |
| haet |
hate |
21 |
| bang |
afraid/fear |
19 |
| vreugt |
joy |
18 |
| vreesen |
fear |
18 |
| verlangen |
desire/longing |
18 |
| beminnen |
love |
18 |
| schrick |
fear |
17 |
| gelukkig |
happiness |
17 |
| rouw |
grief/feeling of loss |
16 |
| blydschap |
joy |
15 |
| wrock |
spitefulness |
14 |
| genoegen |
satisfaction/happiness |
13 |
| vermaak |
joy |
12 |
| spijt |
regret |
12 |
| wraakzucht |
revengefulness |
11 |
| vreeze |
fear |
11 |
Table 9.
Words correctly found by HD-LIWC. Words in bold are historical
variants of emotion words that are missed by D-LIWC, but that are
correctly found by HD-LIWC.
| min |
love |
128 |
| smart |
grief |
98 |
| gramschap |
anger |
60 |
| toorn |
anger |
30 |
| minnen |
love |
27 |
| liefd |
love |
26 |
| mint |
love |
24 |
| minne |
love |
21 |
| droeve |
grief |
19 |
| mededoogen |
compassion |
15 |
| smert |
grief |
14 |
| tooren |
anger |
14 |
| begeert |
desire |
11 |
| haaten |
hate |
11 |
| jalouzy |
envy |
11 |
| verbaast |
wonder |
10 |
| achterdocht |
fear |
9 |
| bevreest |
fear |
9 |
| schroomen |
shame |
9 |
| verschrikt |
fear |
9 |
| begeeren |
desire |
8 |
| lijefd |
love |
8 |
| smarte |
grief |
8 |
| verblyd |
joy |
7 |
Table 10.
Words missed by HD-LIWC
| moet |
must/courage |
767 |
| eer |
before/honour |
568 |
| alleen |
alone |
381 |
| groot |
large |
241 |
| vry |
free |
218 |
| goed |
good |
195 |
| ernst |
seriousness |
160 |
| wij |
we |
160 |
| deugd |
virtue |
152 |
| gaet |
to go |
150 |
| lieve |
dear |
147 |
| hoop |
hope |
146 |
| ryk |
rich |
141 |
| hemel |
heaven |
134 |
| nood |
need |
134 |
| gunst |
grace/goodwill |
131 |
| beter |
better |
129 |
| moed |
courage |
129 |
| lief |
dear |
128 |
| held |
heroe |
125 |
| best |
best |
124 |
| straf |
punishment |
123 |
| vyand |
enemy |
123 |
| lust |
lust |
119 |
| trouw |
faithful |
115 |
Table 11.
Words found by HD-LIWC, ignored by HEEM
Table 11 constains the words that are found by HD-LIWC, but are ignored by
HEEM. It includes words such as “goed”
(good), “ryk” (rich),
“held” (hero) which are appraisals and
judgments rather than emotions in the stricter sense. In HEEM only
descriptions of emotions as defined by Scherer (see paragraph IV) are
annotated while LIWC includes all kinds of sentiment words including
emotions, attitudes, appraisals and beliefs as well as concepts that are
strongly associated with positive or negative feelings such as
“hemel” (heaven) or
“straf” (punishment).
A second set of highly frequent errors comes from incorrectly found form
variants. The verb form “moet” (must) and
the adverb “eer” (before) are wrongly
considered as historic form variants of the noun “moed”
(courage) and the noun “eer”
(honor), respectively. It seems worth trying to solve these
confusions by filtering on part-of-speech, but this is currently not an
option as well-performing NLP tools are not yet available for historical
Dutch.
Finally, LIWC does not take into account polysemy or context. LIWC
overestimates the sentiment value of texts since it classifies ambiguous
words like “alleen” (alone) and
“vry” (free) as negemo and posemo, and
lists “social” pronouns such as “we”
as positive sentiments. The polysemous noun “hoop” has an
affective meaning (hope) and a non-affective meaning
(heap). The theater texts include both usages as in
“van alle hoop ontbloot” (deprived from all
hope) and “een hoop geboeyde slaven” (a
lot of chained slaves). In HEEM the former usage is annotated as
an emotion and the latter is not, whereas LIWC is not able to distinguish
between them. Likewise, we can see that a word like
“lust” (desire) appears both on the list
of correctly found words (cf. Table 9) and on that of the incorrectly found
words (cf. Table 11). It will therefore be difficult to achieve high scores
with a word counting method like LIWC on an early modern literary corpus.
4.2. Bodies and physical states
The LIWC category “Physical” will return body parts such
as hands, eyes, womb or
ears, and bodily processes or reactions such as
trembling, bleeding or blushing,
but also general physical states such as awake,
sleepy, wounded, or illnesses
(anorexia, angina, AIDS), and
even loosely related body words such as alcohol,
bathroom, bathrobe, cook,
kitchen and dishes. HD-LIWC even broadens this
category including words like “schoon”, which can mean
clean and beautiful, but in early modern Dutch
is in many cases used for however
(“(of)schoon”). Also, the indicated problem that
HD-LIWC introduces noise in spelling variants in verb tenses, is visible in
the returns HD-LIWC gives on the historical corpus. One of the words with
the highest recall rates in the category physical is was. This
past tense of the verb to be, is indicated as physical since LexiconService
has was listed as a verbal conjugation of
“washing”. The broad range of the LIWC category
Physical, and the noise created by HD-LIWC therefore renders this category
as not very indicative for research into physical states or reactions to
emotions.
The LIWC category Body is more precise and concise (400 words) than Physical
(648 words). But again, noise is introduced by HD-LIWC.
“zich” (
his) is indicated as a body
term, as a spelling variant of
sight
(“zicht”), just as “vry”
(
free), as a conjugation of “vrijen”
(
making love), “tien” as a variant of
“teen” (
toe), and
“arme” (
poor) as spelling variant of
“arm” (
arm). Altogether 25% of the
indicated body terms is incorrect. Although this is a high percentage, it is
quite easy to correct, since the same noise words keep coming back and their
percentage is quite high (of the 25% of noise 75% is caused by the word
“zich”).
[4] For future use HD-LIWC
could be cleared of these easily traceable mistakes. Apart from these
apparent over-interpretations, HD-LIWC indicated many words as body terms
that are ambiguous. “Vryen” can mean
to make
love, but in most instances it is an inflection of
“vrij” (
free). As long as LIWC only
counts single words, without taking context in consideration, this will
remain a problem.
5. The performance of heem and hd-liwc in a few practical examples
In the last section of this article, we will dive deeper into the texts and
provide some examples as to how applying LIWC and HEEM can help us to analyze
early modern texts. In Table 4 we presented the (HD)-LIWC analysis of an
18th-century Dutch tragedy by Balthazar Huydecoper. Table 12 draws a comparison
between this tragedy and a comedy from around the same period by Jacob Campo
Weyerman.
| Category |
D-LIWC % |
D-LIWC Freq. |
HD-LIWC % |
HD-LIWC Freq. |
D-LIWC % |
D-LIWC Freq. |
HD-LIWC % |
HD-LIWC Freq. |
| We |
0.56 |
98 |
0.91 |
161 |
0,30 |
29 |
0,10 |
45 |
| I |
1.64 |
290 |
4.86 |
856 |
1,93 |
186 |
3,58 |
345 |
| Negemo |
2.67 |
470 |
4.78 |
843 |
1,01 |
97 |
1,97 |
190 |
| Posemo |
2.23 |
394 |
3.51 |
618 |
0,90 |
87 |
2,06 |
199 |
| Posfeel |
0.39 |
69 |
0.59 |
104 |
0,29 |
28 |
0,66 |
64 |
| Anger |
0.75 |
132 |
1.93 |
341 |
0,27 |
26 |
0,52 |
50 |
| Anxiety |
0.64 |
113 |
0.90 |
159 |
0,16 |
15 |
0,32 |
31 |
| Sad |
0.90 |
159 |
1.36 |
240 |
0,19 |
18 |
0,36 |
35 |
| Physical |
1,33 |
235 |
3,05 |
538 |
1,37 |
132 |
2,73 |
263 |
| Body |
1.33 |
235 |
2.38 |
420 |
0,70 |
68 |
1,39 |
134 |
| Death |
0.38 |
67 |
0.48 |
84 |
0,23 |
22 |
0,34 |
33 |
| Social |
6.17 |
1087 |
10.00 |
1763 |
4,18 |
403 |
4,21 |
406 |
| Sports |
0.01 |
1 |
0.01 |
2 |
0,04 |
4 |
0,08 |
8 |
| Swear |
0.00 |
0 |
0.00 |
0 |
0 |
0 |
0 |
0 |
| TV |
0.01 |
2 |
0.02 |
4 |
0,18 |
17 |
0,19 |
18 |
Table 12.
Comparison of D-LIWC and HD-LIWC analysis of a tragedy (
Achilles by B. Huydecoper, 1719) and a comedy
(
De Hollandsche sinnelykheid by J.W.
Weyerman (1713). Total # words: Huydecoper–17,631; Weyerman-9,647.
The comparison leads to some interesting observations. Firstly, the comedy seems
to be far less joyful than the tragedy as the relative frequency of positive
emotions (Posemo) is lower (0.90 / 2.06%) in Weyerman than in Huydecoper (2.23 /
3.51%). Secondly, the tragedy seems to be more emotional over all, whereas the
comedy seems to stage less emotional scenes. As expected, emotions like sadness,
anger and anxiety are far more dominant in Huydecoper’s tragedy. Also, death is
addressed more often in the tragedy. Body terms are used less in the comedy - a
fact that may be connected to the lower degree of emotional expressions.
However, since LIWC does not interconnect these categories (as HEEM does), we
cannot verify this hypothesis.
What puzzled us at first is that exclusive modern-day categories such as TV also
returned results in the early modern texts. A check of the dictionary showed us
that this is due to the fact that this category also includes words like
“vermaak” (
entertainment), which is a rather
common description of being amused in early modern Dutch. We can conclude that
(HD)-LIWC shows interesting results when comparing individual texts. Comparing
these two texts with the overall results of (HD)-LIWC analysis of 29 Dutch
theatre texts, taught us that they follow main trends. Overall, modern
categories such as Sports, School and TV return low results (between 0,03 and
0,2% - and most of the 0,2% depended upon the word
“vermaak”). The category Swearing is even almost completely
absent (0,01%). This can be due to the civilizing zeal of the playhouse
(swearing was hardly tolerated on Dutch stages), and to the fact that swear
words are cultural and time sensitive. The Dutch are famous for swearing with
diseases [
Sanders 1998]. As the most threatening diseases change
over time, so do the swear words. Religious swear words (e.g. devil, holy) have
gone out of fashion.
Religion does show up as a category of interest for Dutch plays (around 0,70%).
This is striking since the Amsterdam theatre did not admit biblical plays on
stage, and frankly discouraged play writers from addressing matters religious on
stage [
Leemans and Johannes 2013, 267–8]. That early modern plays were
meant to arouse and temper the passions is quite clear from the data: both
tragedies and comedies show high results for physical and emotional categories:
Early modern Dutch comedies present a posemo percentage of 2,7% and a negemo of
1,75%, and tragedies 3,30% posemo and 3,54% negemo. This is overall
significantly higher than the average pos/negemo percentages of English language
novels (2.67% posemo, 2.09% negemo), or of the New York Times (2.32% posemo,
1.35% negemo). Current social media, however score much higher on the sentiment
scale than early modern Dutch drama (LIWC 2015).
To compare the performance of (HD)-LIWC and HEEM we can also check the results in
distinguishing between different genres over 29 Dutch theatre plays. Figure 1
shows that HEEM seems to be better in distinguishing comedies and tragedies.
Quite astonishing is the fact that LIWC hardly seems to be able to distinguish
between tragedy and comedy on the basis of their sentiments: positive and
negative sentiments in both genres score around 50%. HD-LIWC has similar results
for tragedies, but finds comedies more positive than negative. According to HEEM
tragedies are far more negative than positive, and although HEEM does not seem
to find comedies significantly more positive, it does show that in percentage,
comedies are much merrier than tragedies.
[5]
|
D-LIWC total# words |
|
HD-LIWC |
|
HEEM |
|
|
Total # words |
% |
Total # words |
% |
Total # words |
% |
| Comedy Neg |
1988 |
46 |
3377 |
39 |
1788 |
54 |
| Comedy Pos |
2368 |
54 |
5201 |
61 |
1552 |
46 |
| Tragedy Neg |
3811 |
54 |
6967 |
52 |
3702 |
68 |
| Tragedy Pos |
3244 |
46 |
6496 |
48 |
1758 |
32 |
Table 13.
Comparison of sentiment analysis of 13 comedies and 14 tragedies between
D-LIWC, HD-LIWC and HEEM. First columns give total amount of words in texts,
second columns % of total for that genre.
For scholars who work on historical texts HEEM is an interesting tool not only
for its preciseness in measuring positive and negative emotions, but even more
for its ability to trace the relative dominance of certain emotions in a
specific period of time, and the chronological development of “emotions lost and found”
[
Frevert 2011]. Moreover, HEEM can analyze where in the body emotions such as wrath are
located and how that changes over time (Figure 1). In general, HEEM can trace
trends in the locations of emotions in the body, finding for instance the rise
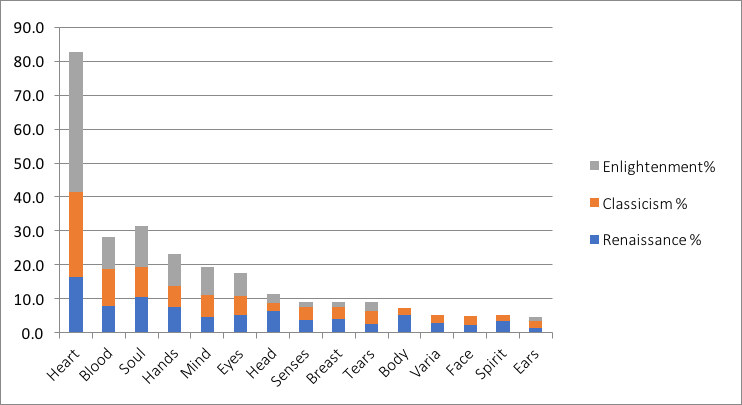
of the heart as an important seat for emotions over the early modern period
(Figure 2). The data presented in these graphs are the results of the machine
learning process that we carried out on the basis of the HEEM model we discussed
so far in this article (see for a discussion of the development of the machine
learning: [
Zwaan et al. 2015]). We have used the HEEM model to analyze a
significant larger set of theatre texts (N = 280). The results of this analysis
will be presented in a following publication. In the meantime, the HEEM tool is
already made available in open access (HEEM-Github).
HEEM and HD-LIWC can also be applied on single plays in order to explore
sentiment dynamics over time. Figure 3 presents a visualization of positive and
negative sentiments in the course of one Dutch theater play. The ‘sentimental’
development can be visualized per character and per speaker turn. The
visualization shows that the two main male characters (Achilles and Patroclus -
blue and red lines) are overall in despair, although Achilles seems to
temporarily brighten up by the presence of Brizeïs (orange line).
These single play analysis and visualizations can be of interest for literary
historians, e.g. to study the narrative structure of texts, or to compare the
plot-sentiment development in different genres. In a follow-up project, we are
developing new narrative-driven visualization tools for HEEM [
Zwaan et al. 2016].
6. Conclusion
This article presents a new model for historical emotion mining in Dutch language
texts: HEEM. We have described why and how we developed HEEM for the mining of
embodied emotions in historical Dutch language texts. We have presented our
evaluation data of HEEM development, and compared HEEM performance with the off
the shelf sentiment mining tool LIWC, and with a historicized version of Dutch
language LIWC.
We conclude that especially a historicized version of Dutch language LIWC
(HD-LIWC) could be apt for sentiment mining in historical texts. Some of the
“non-emotion” categories LIWC registers also seem
relevant for historical texts (topics such as “death” or
“religion”, usage of we/I/you), whereas some categories
are too time specific to be of any use (TV, sports, school, swearing).
Overall, LIWC is a text analysis program based on single word recall. Although
LIWC offers some classifications of specific emotions, these are biased towards
negative emotions (sadness, anger, anxiety). Researchers interested in emotions,
as opposed to a larger category of sentiments, seem to be better off with HEEM.
HEEM also has a more fine-grained vocabulary for the detection of body terms in
historical texts and relating those to emotions. It allows us to map changes in
the embodiment of emotions on the Dutch Stage over a long period of time. For
the future, improvements could be made to HD-LIWC by developing stricter
spelling variants and including part of speech tags, to diminish noise. Together
with the Dutch LIWC team, we are exploring possibilities to improve HD-LIWC, and
apply it on the Dutch translation of LIWC2015.
Combining LIWC and HEEM could bring new perspectives to future research: it could
give an indication of the physicality of a text (how many body terms are used in
general?) and of the percentage of emotional physicality: what percentage of the
physical terms is indicated as emotionally charged?
Acknowledgments and Correspondence
This article is based upon the research project “Embodied
Emotions”, conducted at Vrije Universiteit Amsterdam, Netherlands
Escience Centre (Amsterdam), and Meertens Institute (Royal Netherlands Academy
of Arts, Amsterdam). The project was set up by ACCESS (Amsterdam Centre for
Cross-disciplinary Emotion and Sensory Studies) and funded by the Netherlands
Escience Centre, with additional funding by the Nederlab project. The digitized
corpus was provided by DBNL (the Digital Library of Dutch Literature).
Correspondence to:
- Author Name: Inger Leemans
- Affiliation: Vrije Universiteit Amsterdam, Faculty of Humanities
- Address: De Boelelaan 1105, 1081 HV Amsterdam
- Tel: 00-31-20-5987800
- Email: i.b.leemans@vu.nl
Works Cited
Baccianella et al. 2010 Baccianella, S.,
Esuli, A., Sebastiani, F. 2010. “SentiWordNet 3.0: An
Enhanced Lexical Resource for Sentiment Analysis and Opinion Mining”,
LREC.
Boddice 2014 Boddice, Rob. 2014. “The Affective Turn: Historicising the Emotions.” In: C.
Tileaga & J. Byford (eds.), Psychology and History:
Interdisciplinary Explorations. New York: Cambridge UP,
147–65.
Borowiecki 2013 Borowiecki, Karol Jan. 2013.
“How Are You, My Dearest Mozart? Well-Being and
Creativity of Three Famous Composers Based on Their Letters.”
Discussion Papers of Business and Economics 20.
Univ. Southern Denmark.
https://ideas.repec.org/p/hhs/sdueko/2013_020.html.
Braake and Fokkens 2015 Braake, S. ter, & A.
Fokkens, 2015. “How to Make it in History. Working Towards a
Methodology of Canon Research with Digital Methods”, Proceedings of the first Conference on Biographical Data in a
Digital World 2015.
Dalen-Oskam 2013 Dalen-Oskam K.H. van 2013.
“Names in novels: an experiment in computational
stylistics”. LLC: The journal of digital
scholarship in the Humanities 28, 2 (June), 359-370.
Dixon 2003 Dixon, T. 2003. From Passions to Emotions : The Creation of a Secular Psychological
Category. Cambridge etc: Cambridge University Press.
Eijnatten et al. 2014 Eijnatten, J. van,
Verheul, J. & Pieters, T. 2014. “TS Tools: Using
Texcavator to Map Public Discourse”. TS:
Tijdschrift voor Tijdschriftstudies (35), 59-65.
Fellbaum 1998 Fellbaum, Chr. 1998 WordNet: An Electronic Lexical Database. Cambridge:
MIT press.
Frevert 2011 Frevert, U. 2011. Emotions in History: Lost and Found. Central European
University Press.
Frevert 2014 Frevert, U. 2014. “Emotional Knowledge: Modern Developments.” In Emotional Lexicons: Continuity and Change in the Vocabulary of
Feeling 1700-2000, edited by Ute Frevert and Monique Scheer, 230–59.
Oxford: Oxford University Press.
Frevert et al. 2014 Frevert, Ute, Monique
Scheer, Anne Schmidt, Pascal Eitler, Bettina Hitzer, Nina Verheyen, Benno
Gammerl, Christian Bailey, and Margrit Pernau. 2014. Emotional Lexicons: Continuity and Change in the Vocabulary of Feeling
1700-2000. Oxford: Oxford University Press.
Kahn et al. 2007 Kahn, J. H., Tobin, R.M., Massey,
A. E., & Anderson, J. A. 2007. “Measuring emotional
expression with the linguistic inquire and word count”. American Journal of Psychology, 120: 263–86.
Leemans 2017 Leemans, I., 2017. “Large data set mining”, in: S. Broomhall (ed.), Early Modern Emotions: An Introduction. NY/ Abingdon:
Routledge, 27-30.
Leemans and Johannes 2013 Leemans, I. &
Johannes, G.-J. 2013. Worm En Donder. Geschiedenis van de
Nederlandse Literatuur 1700-1800: De Republiek. Amsterdam:
Uitgeverij Bert Bakker.
Liu 2015 Liu, B. 2015. Sentiment
Analysis: mining sentiments, opinions, and emotions. Cambridge
UP
Matt and Stearns 2013 Matt, S.J & Stearns, P.
(eds.). 2013. Doing Emotions History. University of
Illinois Press.
Pander Maat et al. 2014 Pander Maat, H., R.
Kraf, A. van den Bosch, et al. 2014. “T-Scan: a new tool for
analyzing Dutch text”, Computational Linguistics
in the Netherlands Journal 4 53-74
Pennebaker et al. 2001 Pennebaker, J.W.,
Francis, M.E., & Booth, R.J. 2001. Linguistic Inquiry
and Word Count: LIWC2001. Mahwah, NJ: Erlbaum Publishers.
Pennebaker et al. 2015 Pennebaker, J.W., Boyd,
R.L., Jordan, K., & Blackburn, K. 2015. The
development and psychometric properties of LIWC2015.Austin, TX:
Univ. of Texas. DOI: 10.15781/T29G6Z
Plamper 2015 Plamper, J. 2015. The History of Emotions: An Introduction. Oxford
UP.
Read and Carroll 2010 Read, J., and Carroll, J.
2010. “Annotating Expressions of Appraisal in
English.”
Language Resources and Evaluation 46 (3): 421–47.
doi:10.1007/s10579-010-9135-7.
Rosenwein 2002 Rosenwein, B. 2002. “Worrying about Emotions in History.”
The American Historical Review 107 (3): 821–45.
doi:10.1086/532498.
Sanders 1998 Sanders, E. & Tempelaars, R.
1998. Krijg de vinkentering! 1001 hedendaagse Vlaamse en
Nederlandse verwensingen. Amsterdam: Contact.
Scherer 2005 Scherer, K.R. 2005. “What Are Emotions? And How Can They Be Measured?”
Information Sur Les Sciences Sociales 4:
695–730.
Sprugnoli et al. 2016 Sprugnoli, R., Tonelli,
S., Marchetti, A. & Moretti, G. 2016. “Towards sentiment
analysis for historical texts”, Digital
Scholarship in the Humanities 31: 762–772.
https://doi-org.vu-nl.idm.oclc.org/10.1093/llc/fqv027
Stone et al. 1996 Stone, P.J., Dunphy, D.C., Smith,
M.S., et al., 1996. The General Inquirer: A Computer
Approach to Content Analysis (MIT Press, 1966).
Strapparava and Valitutti 2004 Strapparava,
C. and A. Valitutti. 2004. “WordNet-Affect: an Affective
Extension of WordNet”
Proceedings of LREC-2004, Lisbon Portugal.
Tausczik and Pennebaker 2010 Tausczik, Yla R.,
and James W. Pennebaker. 2010. “The Psychological Meaning of
Words: LIWC and Computerized Text Analysis Methods.”
Journal of Language and Social Psychology 29 (1):
24–54.
Vossen et al. 2008 Vossen P., Maks I., Segers R.,
Van der Vliet H. 2008. “Integrating lexical units, synsets
and ontology in the Cornetto Database”, in: Proceedings of LREC 2008, Marrakech, Morocco, May 28-30 May 2008,
Ed. European Language Resources Association (ELRA).
Vossen et al. 2013 Vossen P., Maks I., Segers R.,
Van der Vliet H. et al. 2013. “Cornetto: A Combinatorial
Lexical Semantic Database for Dutch”. Chapter 10 in: Spyns, Peter;
Odijk, Jan (Eds.) Essential Speech and Language Technology
for Dutch. Results by the STEVIN-programme Series: Theory and
Applications of Natural Language XVII.
Wevers 2017 Wevers, M. 2017, Consuming America. A Data-driven Analysis of the United States as a
Reference Culture in Dutch Public Discourse on Consumer Goods
1890-1990. Creative Commons
Wiebe et al. 2005 Wiebe, J., Wilson, T. &
Cardie, C.. 2005. “Annotating Expressions of Opinions and
Emotions in Language,” 2: 165–210.
Wittek and Ravenek 2011 Wittek, P., & Ravenek,
W. 2011. “Supporting the Exploration of a Corpus of
17th-Century Scholarly Correspondences by Topic Modeling.,””
November.
http://bada.hb.se:80/handle/2320/9689.
Zijlstra et al. 2004 Zijlstra, H., Meerveld, T.
van, Middendorp, H. van, Pennebaker, J.W. & Geenen, R. 2004. “De Nederlandse Versie van de ’Linguistic Inquiry and Word
Count (LIWC), Een Gecomputeriseerd Tekstanalyseprogramma (Dutch Version of
the Linguistic Inquiry and Word Count (LIWC), a Computerized Text Analysis
Program).”
Gedrag & Gezondheid: Tijdschrift Voor Psychologie &
Gezondheid 4: 271–81.
Zwaan et al. 2015 Zwaan, J.M. van der, I. Leemans,
E. Kuijpers, & I. Maks. 2015, “HEEM, a Complex Model for
Mining Emotions in Historical Text”, 11th IEEE
International Conference on eScience.
Zwaan et al. 2016 Zwaan, J. M. van der,
Meersbergen, M. A. J. van, Fokkens, A. S., ter Braake, S., Leemans, I. B.,
Kuijpers, H. M. E. P., Vossen, P. T. J. M. & Maks, I. 2016. “Storyteller: Visualizing Perspectives in Digital Humanities
Projects”, Computational History and Data-driven
Humanities. Dublin.