


Volume 11 Number 4
In a test bed with Kafka. Introducing a mixed-method approach to digital stylistics
Abstract
In the emerging field of digital style analysis, scholars have been dwelling on a perceived irreconcilability of “distant reading” [Moretti 2000] and “close reading” [Fish 2012] [Ransom 1937]. This situation is somewhat reminiscent of the “paradigm wars” in social science, where for years, one could either adhere to a quantitative or a qualitative mindset. Taking seriously both the hermeneutic and the empirical traditions of (digital) stylistic research, the present paper proposes “a mixed-methods” coalition of approaches. To establish links between the mixed-methods paradigm from Social Sciences [Creswell and Plano Clark 2007] and stylistic practices within Digital Humanities (DH), the present article discusses common methods of distant, close, and ‘scalable reading’ as well as a flexibly adjustable definition of style [Herrmann et al. 2015]. In the practical part of the paper, I report a ‘mixed-methods digital stylistics’ study on Franz Kafka’s prose. Scaling the degree of abstraction and contextuality of the data according to particular research questions, I combine (1) “quantitative hypothesis testing” (examining Kafka’s stylistic “uniqueness” by means of a stylometric measure); (2) “quantitative exploration” (analyzing the first hundred statistically overrepresented words in Kafka); and (3) “qualitative text analysis” (KWIC and close reading to investigate the functions of a particular style marker in the context of Kafka’s The Judgment [Das Urteil]). Generally, for digital stylistics, I propose (a) raising epistemological and methodological awareness within the field, and (b) framing the research within the mixed-method paradigm that in fact seems very well suited to DH.
Introduction
“Quantitative”, “qualitative”, and “mixed-methods”
With this general rationale at its core, mixed-methods research has been established as a third empirical paradigm[4], with its own range of research design types (cf. [Creswell 2014] [Creswell and Plano Clark 2007] [Johnson and Onwuegbuzie 2004] [Tashakkori and Teddlie 2010].[c]ombine the methods in a way that achieves complementary strengths and non-overlapping weaknesses. [Johnson and Onwuegbuzie 2004, 18]
Mixed-methods Digital Style Analysis
A quantitative, variable-driven approach may be interested in extracting formal features from a large data set devoid of context, for example gauging the “similarity” of authors by looking at the most frequently used words (the dominant stylometric measure), whereas a “case-driven” approach may be interested in aspects of the holistic gestalt of single texts, or the function of previously extracted featured within that context. A third kind of approach may use a quantitative measure for exploring possible new variables (and thus, as a quantitative-heuristic approach may not fit the simplified quantitative-qualitative dichotomy).Style is a property of texts constituted by an ensemble of formal features which can be observed quantitatively or qualitatively. [Herrmann et al. 2015, 44]
The Method of the Art
Making the test bed
- Hypothesis Generation from Literary Criticism. I distilled from literary criticism converging evidence for a relatively broad assumption about Kafka’s style, the “solitariness”-hypothesis (see below). Finding convincing observations and arguments from the existing literature is thus a necessary step in hypothesis generation. This view has been put forward on the basis of qualitative, hermeneutic interpretations of separate texts (involving the description of linguistic features and literary effects). The kind of evidence given so far offers no firm ground for generalization.
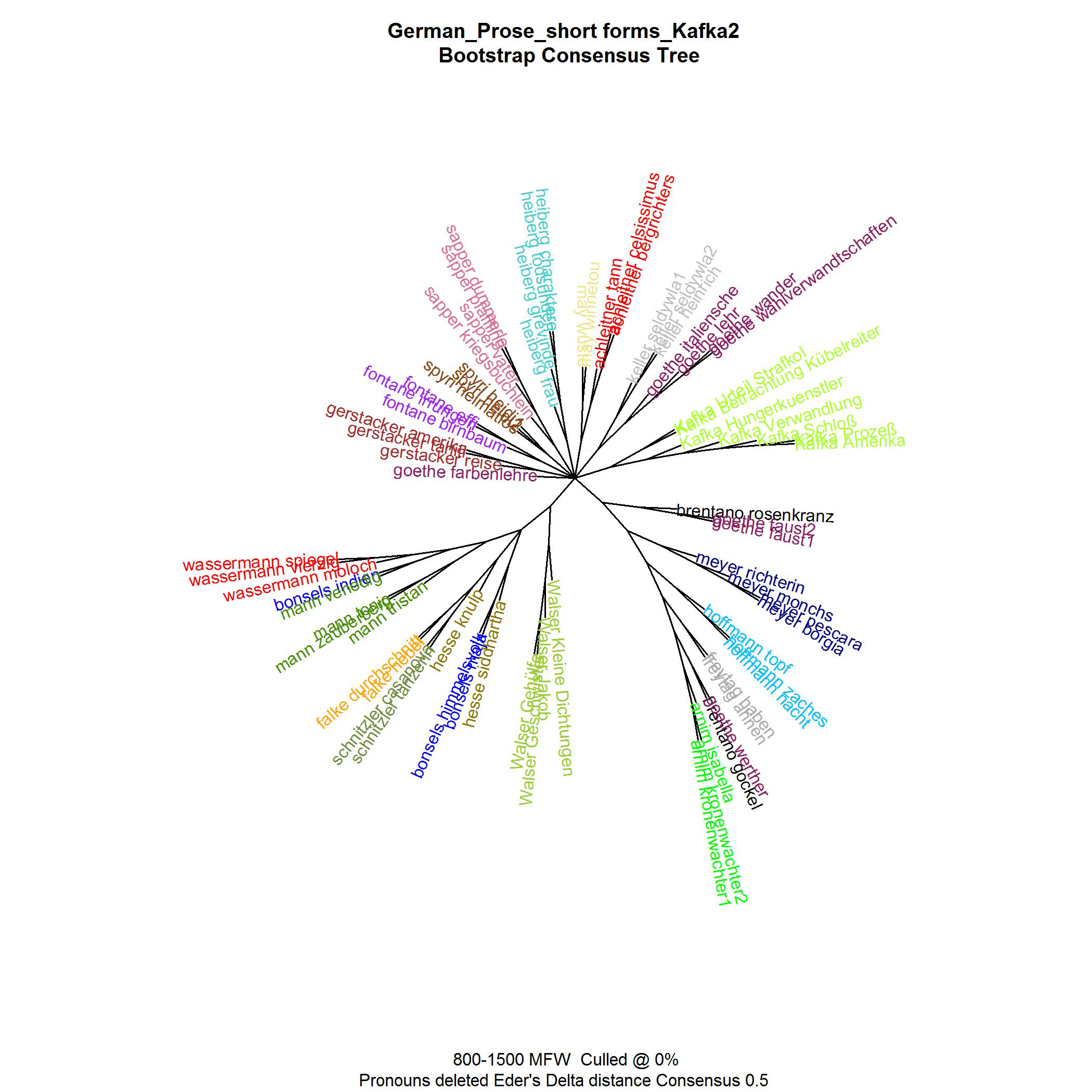
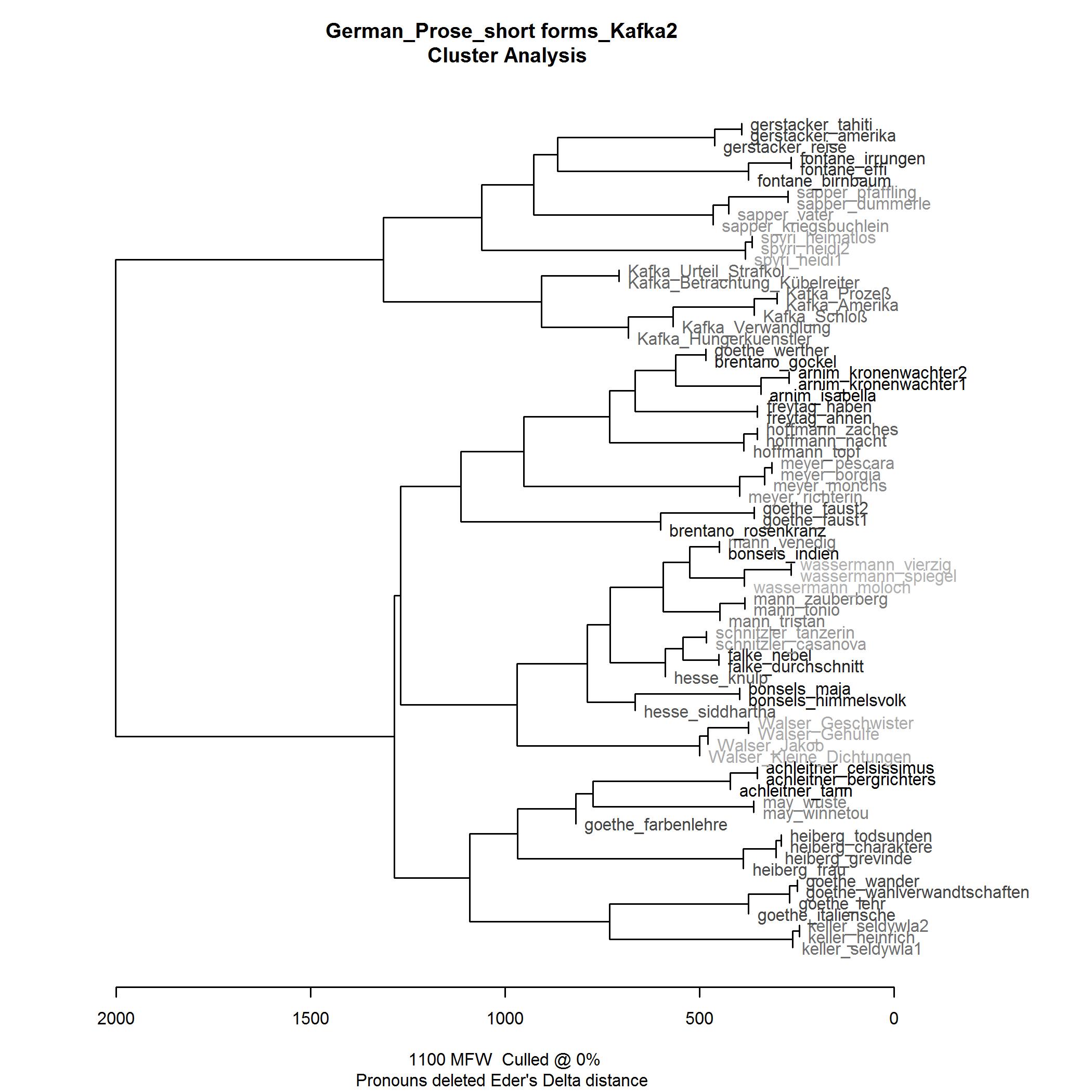
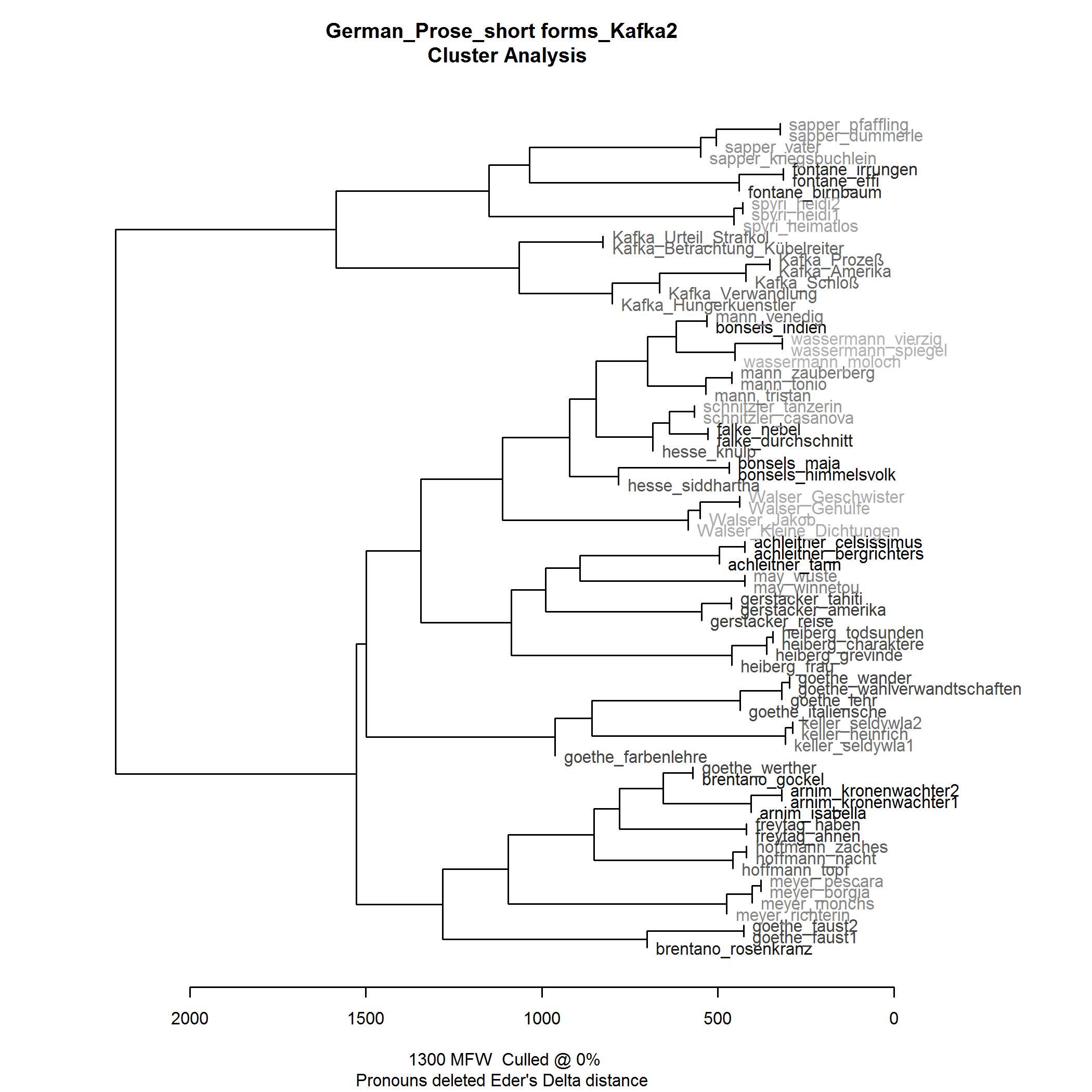
- Quantitative Hypothesis Testing. My first empirical step was quantitative hypothesis testing. Extending on prior research [Herrmann 2013a], I examined the “solitariness”-hypothesis on a wider data basis (comparing Kafka’s texts to texts by more than 20 other German authors across time).[10] For the sake of quantitative breadth, I relinquished the rich complexity of case-driven analysis, using as an indicator of “style” a standardized aggregate measure of most frequent words, Delta (see below) and cluster analysis. A problem with this type of analysis is that it does not provide insights into the particular features that may be responsible for Kafka’s (assumedly) distinctive style.
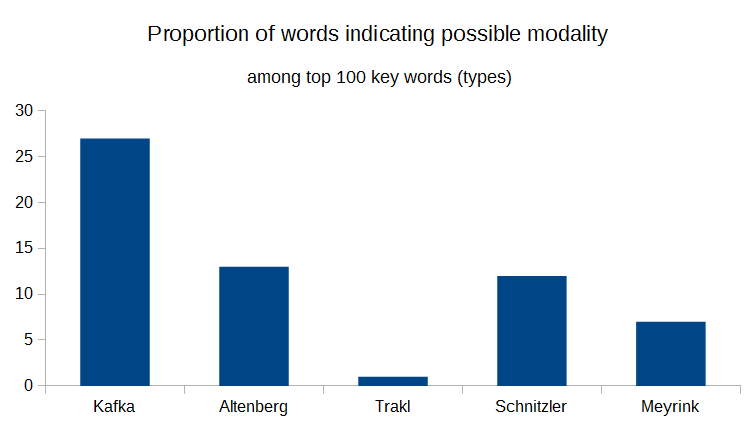
- Quantitative Exploration. The second analysis applied another frequency-based measure, keyness, to explore the stylistic patterns possibly underlying the results from the cluster analysis. Keeping the time signal relatively constant, I compared Kafka’s word use to four authors belonging to the same literary epoch, Modernism. Style was here identified as a statistically defined “norm” (the numerical reference being the same corpus used in the first analysis), treating word forms that are significantly more frequent than that norm as “stylistically marked”. Building on prior research [Herrmann 2013b], I manually grouped the top 100 overrepresented word forms into (potential) word classes. A category of word forms emerged as particular to the Kafka sample that may be used for subtly managing modality. However, even though this analysis tackles style at the feature level, it is still strongly decontextualized. More context was needed to add value and insight to my observations.
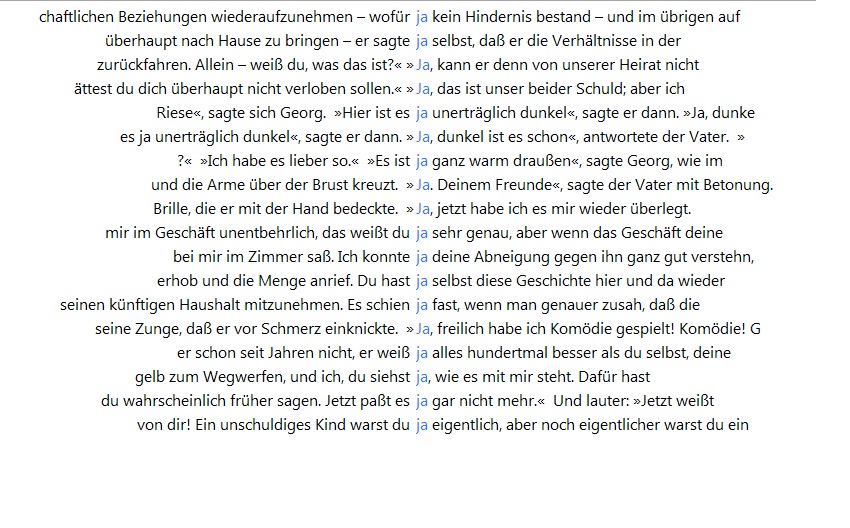
- Qualitative Text Analysis. In a qualitative close reading of one of Kafka’s stories (The Judgment) taken from the same corpus as before, I focused on just two potential modal particles derived from the previous step. Using KWIC (Key Word in Context) to systematically analyze their local usage, taking into account the context of Kafka’s story (including the plot), I examined their use and potential functions throughout the unfolding story [Herrmann 2016]. From here, further analysis may take up several possible leads given by the results. These may involve a larger data set and increased statistical rigor – as well as the qualitative detail of other texts and features (modal particles, negations, and adverbs).
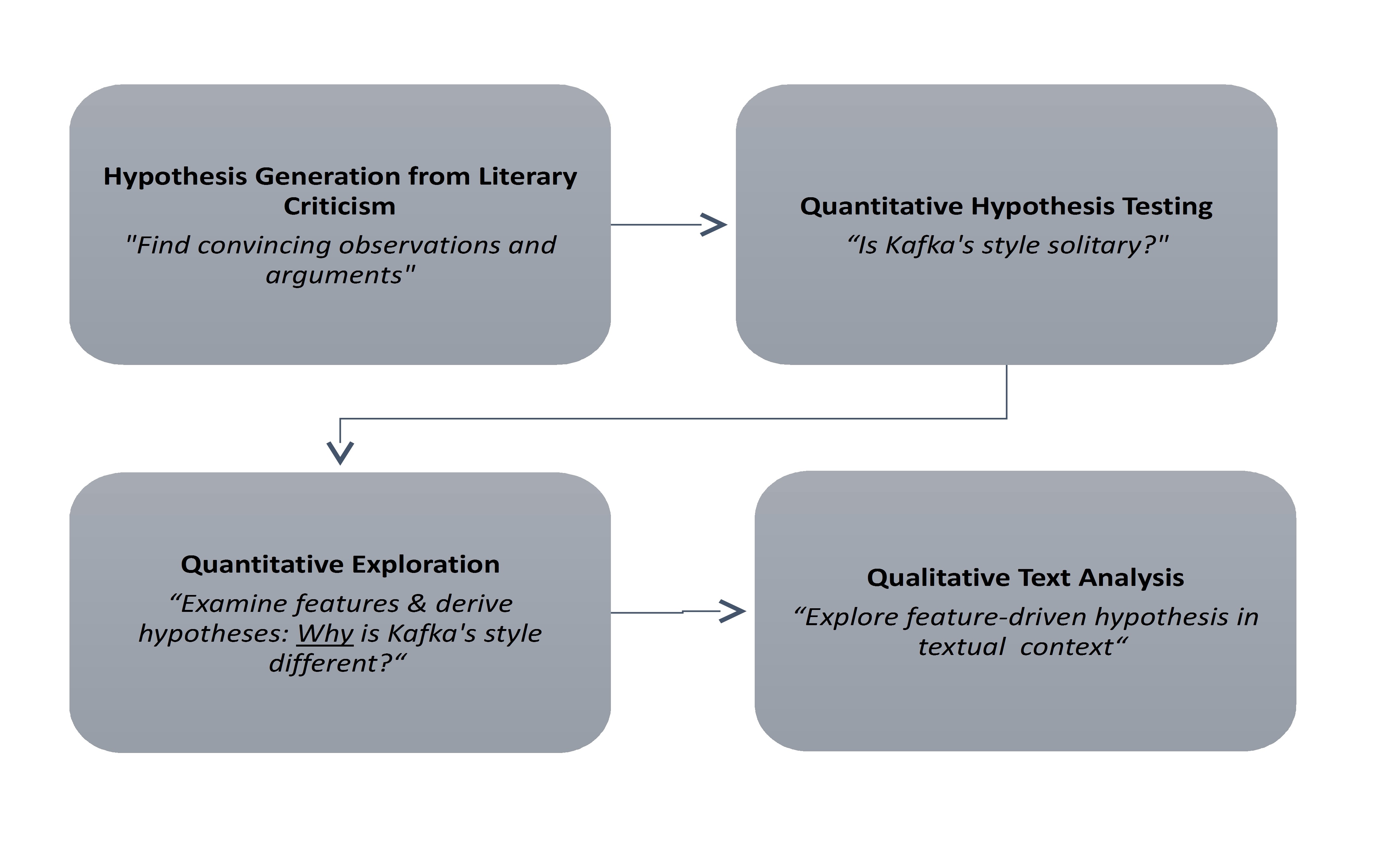
Applying Mixed-Methods to Kafka
Hypothesis Generation from Literary Criticism
Study 1: Quantitative Hypothesis Testing
- H1: Kafka’s texts are more similar to each other than they are to other texts, and, as a group, are by comparison more dissimilar from other (groups of) texts. For the cluster analysis, this means two things: (a) a similarity-cluster can be observed for Kafka’s texts; (b) the observed Kafka-cluster shows distances from other (potential) clusters that are greater than any other distances observed.
- H0: Kafka’s texts do not show a greater similarity to each other than to any other text. In the cluster analysis, Kafka’s texts do not cluster with each other. However, as authorship is a strong predictor of style, clustering by author is generally expected.[14] Therefore, H0 may be reformulated: Kafka’s texts as a potential group of texts related by similarity do not show greater dissimilarity to other groups of texts by comparison. In the cluster analysis, any Kafka-cluster of texts thus has a similar distance to other potentially observed author-clusters as these have from each other.
Study 2: Quantitative Exploration
| Epoch | Author | No. of words |
| Modernism | Kafka | ~308,400 |
| Altenberg | ~245,200 | |
| Trakl | ~21,300 | |
| Meyrink | ~156,500 | |
| Schnitzler | ~1,037,000 | |
| Newer German Literature | 22 authors | ~5,873,100 |
- What differences between the five authors are striking among the top 100 keywords?
- Which word classes are particularly common in Kafka when compared to the other authors?
Study 3: Qualitative Text Analysis
Conclusions
My point in this paper has been to embrace distant reading's variable-driven principle, but to complement it by a paradigm that is case-driven, looks at smaller samples, and may indulge in open-ended interpretation about connections between different variables. Both general approaches have their merit, and tapping into the methodological flexibility offered by a mixed-methods paradigm will allow for the interaction of different mindsets in a structured way.If we want to understand the system in its entirety, we must accept losing something. We always pay a price for theoretical knowledge: reality is infinitely rich; concepts are abstract, are poor. But it’s precisely this ‘poverty’ that makes it possible to handle them, and therefore to know. This is why less is actually more. [Moretti 2000, 578–8]
Author’s Note
Notes
Works Cited

Comments: dhqinfo@digitalhumanities.org
Published by: The Alliance of Digital Humanities Organizations and The Association for Computers and the Humanities
Affiliated with: Digital Scholarship in the Humanities
DHQ has been made possible in part by the National Endowment for the Humanities.
Copyright © 2005 -

Unless otherwise noted, the DHQ web site and all DHQ published content are published under a Creative Commons Attribution-NoDerivatives 4.0 International License. Individual articles may carry a more permissive license, as described in the footer for the individual article, and in the article’s metadata.
