Abstract
In this paper we intend to present a tool we developed for translation studies
and diachronically compare various French translations of the Odyssey.
This field of study is part of the more general “Classical Receptions”
studies that try to analyse the influence and adaptation of classical texts in
modern and contemporary literature, theatre, cinema, and many other artistic
fields. While Greek texts have been analysed by scholars for more than two
thousand years, research about classical translations is not yet a most renown
subject. In recent years this theme has raised a growing interest in the
academic community.
We developed a program that can align textual sequences (defined as groups of
words delimited by a specified grammatical pivot, in our case proper nouns),
without need of previous training. We obtained alignments for many different
kinds of translations[1]. While
other programs have an upper bound for one-to-many alignments (for example with
a maximum of four translated elements aligned to the same original element) this
algorithm allows an indefinite number of alignments, both for the source
sequences and the target ones. The aligner is based on an implementation of
Needleman-Wunsch algorithm and on a string-based similarity approach to textual
segments. The aligner needs to establish proper names as anchor words, as they
are a relatively stable feature through different translations and tend to be
similar in several languages.
Thanks to the alignments obtained using the program, we can explore translations
in a number of ways. We will illustrate the creation of a graphical interface to
visualize French Homeric translations.
With our tool, it is possible to highlight aligned portions of texts and show
their immediate differences or similarities, both in meaning and in syntactic
distribution.
We will show some resulting syntactic analyses carried out on a small sample of
texts, taken from a corpus of twenty-seven unabridged French translations of the
Odyssey and explore how the study of diachronic translations through algorithms
of computational linguistics can produce interesting results for literary and
linguistic studies.
Background
The Odyssey can be considered as one of the major
pillars of modern literature. It has been translated in all major Indo-European
languages for many centuries. We created a digital corpus of fifty French
translations from the 16th century to the 20th for a total of 207 translations
and reprints. In this paper we shall try to demonstrate how trends and literary
movements could be analysed using the immediate statistic results and
visualizations that we obtained with our tool. This paper will focus on a sample
of the whole corpus.
This paper focuses on the XIth book. This book is a very well known episode of
the Odyssey, often called the nekuia, containing a dialog with the dead (slightly
different, for example, from the katabasis, an
actual descent into Hell). It is also a key episode for translators. In France,
from the 16th to the 20th century, the three most translated books were the Ist,
the VIth and the XIth. Throughout our research, we have identified three kinds
of translations: translations made for scholastic readers who specialize in
Ancient Literature, translations made for school use, for students who need to
learn about Greek Literature and translations that appear as a kind of stylistic
exercise, and often an echo or an announcement of future works. The XIth book is
also interesting because every translator who chose to translate it went on to
translate the whole of the Odyssey. It often seems
to be a trial book, a book to test and improve literary skills and style. As a
result, we could sketch the translator’s virtual portrait: every single
translator of the XIth book has, sooner or later, devoted himself to defending
the literary value of Ancient Literature, and more precisely, every one of them
has seen in the Ancient corpus a source for inspiration, a stylistic potential
to unravel. That is why this particular book was chosen.
Concerning the Greek pivot text, it is based on the Greek text established by
Allen and Monro [
Monro 1902], as it is the most widely used
representation of the Greek text, both before and after the 19th century. Monro
and Allen are also most familiar with the whole vulgate around Homer, and
include many variants from Eustathius, often considered as the most precious
source for reconstructing Homeric epics in Greek (since the
princeps edition of his commentaries in 1542).
To analyse trends or literary tendencies, the use of alignment and
post-processing algorithms appeared as a novelty. Many works already have been
made on aligning translations to their original texts (see for example [
Déchelotte 2007]; [
Brown 2003]; [
Gale 1991]) but they focused on synchronic, non-literary corpora.
In literary studies, on the other hand, the necessity of textual alignment
appeared for two reasons: scholars wanted to evaluate a translation by
considering its source and to create a possible alternative to that translation.
As a result, the translation itself as a work of art remained underestimated.
Aligning translations gives the art of translation its rightful place: an
authentic literary experience, considering the translation itself as an object
of art and study. We therefore decided to focus on dividing and aligning each
translation, in order to identify possible stylistic trends and possible echoes
of the literary world of the translator.
Automatic Alignment Method
Since segment alignment is widely considered a necessary step in order to proceed
toward any kind of word alignment attempt [
Allauzen 2009]; [
Gao 2008]; [
Gao 2011], using a good global aligner
is regarded as an important prerequisite for many studies about automatic
translation.
To align our translations to the original text we wrote a Java implementation of
the Needleman-Wunsch algorithm
[1]. The Needleman-Wunsch algorithm [
Needleman 1970] was originally designed to align the amino acid
sequences of two proteins. This algorithm is expensive in terms of computational
complexity and efficiency of the procedure but remains a tool of the highest
quality to perform global alignment.
There have been several attempts to adapt the Needleman-Wunsch algorithm for use
in the field of text processing and digital humanities. To cite some of the most
recent cases, it has been used to perform phonetic alignments in historical
linguistics (see [
List 2013] for an overview), to perform
character-based detection of text similarities [
Gomaa 2013], to
validate claims of structural affinity in narrative [
Reiter 2014]
and to detect similar URLs [
Germann 2016]. It is sometimes used in
tasks of monolingual text alignment in combination with other systems [
Nelken 2006]. Since the algorithm in itself is designed to
globally align sequences of any kind, its implementations are different in every
case. What changes is usually the tokenization of the sequences, (these can be
divided in letters, words, or textual blocks as we see here), and the similarity
score used to decide whether two elements should be aligned or not.
In our case, we re-purposed the Needleman-Wunsch structure to align bilingual
portions of text. Through the process described in the following pages we
globally aligned the XIth book of the Odyssey with
several translations. Such an alignment allows several types of statistical
valuations impossible to perform otherwise: these include an analysis of how far
the translations deviate from the original, quantify the cases of lacunary texts
and start building word-to-word alignments that might show the variations of
preferential translations through time. At the least, such a tool can help a
scholar finding quantitative data to support or dispute a translational claim.
Although applying this algorithm to non-biological sequences is not a novelty, to
the best of our knowledge there has been no previous application of the
Needleman-Wunsch algorithm to translation alignment and diachronic translation
study.
Simply put, the Needleman-Wunsch algorithm tries to align two sequences of
comparable length. Given that each sequence is divided into an arbitrary number
of elements, such as words or letters for a sentence, the task of the algorithm
is to optimally match the elements of the two sequences.
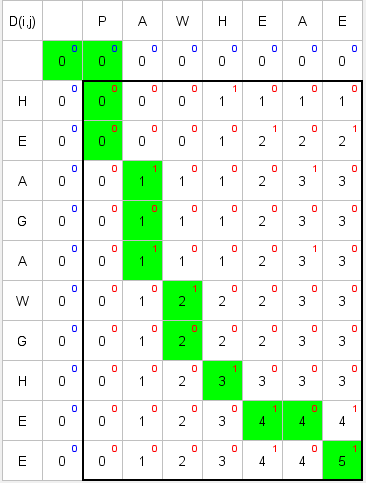
To perform this operation the algorithm records each possible match between the
elements of the two sequences in a grid-like structure, and assigns a score to
each combination. This score is usually computed through a matching rule: for
example, two identical words are a better match than two totally different
words. The cost of leaving a gap if the system doesn’t find any good matches for
a sequence’s element is also taken into consideration. Once this grid is built
and filled with scores, the algorithm is able to trace back the optimal (e.g.
least expensive) path through it, as can be seen in Figure 1.
An “ideal” path would be a perfect diagonal, and the algorithm tries to
diverge the least from such a path, given the differences between the sequences
and the similarity heuristics it uses. This process results in the optimal
global alignment of the sequences.
Figure 2 shows an example of global alignment of two strings performed through
the Needleman-Wunsch. If an element could not be aligned, the algorithm will
insert a gap.
Since we study translations of comparable length, this approach seems reasonable.
As we will detail later, we pass to the algorithm our texts divided in small
blocks and we provide it with an ad hoc similarity function. We perform the
alignment twice, so that we are able to refine the similarity function for the
second alignment through the results of the first alignment. The result is a
sequence of small, aligned blocks in one or two languages that can be used as a
basis for in-depth quantitative analysis of translation corpora.
In our case, the main problem was the necessity to align long and non-segmented
texts with translations that are often noisy, literary and inaccurate.
Furthermore, Homeric poems are not divided on a small scale: rhapsodies are
hundreds of lines long and episodes can be undetermined.
There is a variety of elements that can be used as anchors in a text. The best
anchors are high frequency words, when the original and its translation are very
similar; or low frequency words such as technical terms, if we are sure they
will always be translated in the same way or within a very reduced number of
variants. Numbers can also act as anchors if they are always translated in the
same way.
However, in the case of Homeric translations, these pivots are not reliable. We
can find many kinds translations of the Homeric text, with many types of
periphrasis, interpolation, and stylistic compromises. For example, many
translators thought that repetition was a reprehensible stylistic feature and
consistently used synonyms or periphrases where the original text had simply the
same word repeated twice: so high frequency nouns or verbs could be unreliable.
Other translators could do just the opposite, making low frequency words
unreliable.
These variations in translation style made choosing appropriate anchors
problematic as traditional approaches were difficult to apply (for more
traditional approaches see [
Gomaa 2013]; [
Ma 2006];
[
Nelken 2006]; [
Och 2003]; [
Och 1999]).
Also, we didn’t have a “training dataset”, as often happens in other cases
of translation alignment, since there was no existing corpus of aligned Homeric
Greek - French texts. Even if such a corpus existed, it would have been
unreliable due to the compromises that different authors made while translating
the text. Additionally, as this is a diachronic study on literary translations,
even a Greek - French dictionary of anchor pairs would have hardly been useful.
For these reasons, in order to segment our texts and their different translations
we chose to use proper nouns as anchor words. Proper nouns are a relatively
stable feature in Homeric translations. In fact, even the translations which
differ most from the original text tend to maintain the Greek proper nouns. It
is possible to look through many different translations and find that proper
nouns tend to remain phonetically similar with their Greek source, as can be
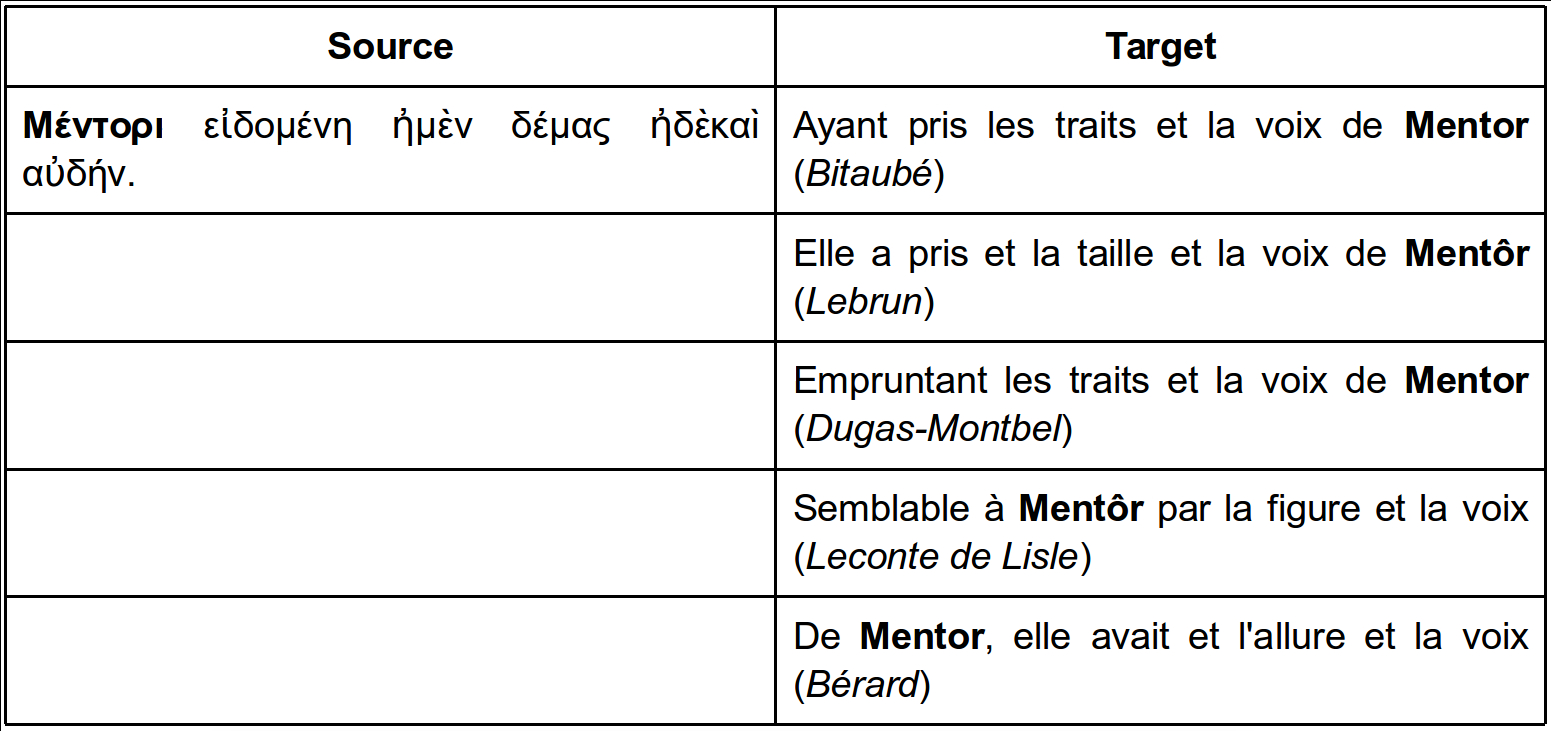
seen in Figure 3.
We decided to use proper nouns as pivot for segmenting our text. A source
sequence is defined as a list of words beginning with a Greek proper noun
stopping at index-1, index being the location of the following Greek proper
noun; a target sequence is a list of words beginning with a French (or any
target language) proper noun, stopping at index-1. However, proper nouns are not
completely reliable: duplications, interpolations, substitutions or unusual
translations happen in the onomastic field too. As a result rare proper nouns
tend to be more reliable pivots while frequent proper nouns should not be given
the same importance for the alignment. Once the sequences have been defined, the
alignment can begin.
We first create a dictionary of anchor words. The Greek nouns are transformed
according to historical linguistic rules that produced French modern proper
nouns from their source Greek ones. For example, in
Ἀχαιός,
αι is reduced to
e, and
χ transcribed as
ch[2]. Once the
Greek noun has been transformed, it is compared to its possible translation
considering the edit distance between the two. If the distance is small, the
target value is considered as a translation of the source key. A map
<String, String []> is therefore created, with a key for
the source text and a list of translations for the target texts. The dictionary
is cumulative and allows to add every possible value of every possible target
text to a single source key. A possible representation of this map could be:
Ἐρέβευς – Erèbe, Erebe
Μενελάου – Ménélas
Μέντορι – Mentor, Mentôr .…
Example 1.
To each lemmatized Greek name correspond several potential French
values.
This dictionary will allow us to increase or decrease the potential similarity
between two sequences. The alignment process can now begin.
As we briefly explained at the beginning of the paper, the first step is to
create a 2D matrix where all the sequences are stored: the source sequences are
stored in the columns (each sequence is stored in each column), the target
sequences are stored in the lines (each sequence is stored in a different line).
To align the elements of the series, it will be necessary to choose a scoring
system. A basic scoring system can be thus summed up: if a source element at
index i and a target element at index j are equal (two
identical letters, two similar numbers, etc.) the score stored in the matrix at
index ij is 1, otherwise 0.
Our way of establishing scores between sequences is similar, but more selective.
We use many similarity metrics already well known that we implemented for our
own purposes, such as the Monge Elkan distance, the Levensthein distance, the
Jaro-Winkler distance, or the Hamming distance
[3] on both the
transformed Greek and the tags associated with each word (both in French and
Greek). The sequences carry their morphological information: each verb in Greek
is associated with a VB tag, each noun with a NN tag, etc. and so is the target
sequence. It therefore possible to take into account the syntactic similarity
between the source and the target. Yet again, this is far from being the only
similarity measures we use. The similarity is also determined by the frequency
of the proper nouns used both in source and in target sequences. Since the
frequency of proper nouns, like that of words in general, follows a Zipfian
distribution, we give to proper nouns a similarity score which is inversely
proportional to their frequency. If a low-frequency noun appears in Greek, and
if its potential translation can be found in its potential matching sequence,
the similarity is much stronger. We also take into account the absolute distance
between two sequences. If a very short sequence is associated with a very long
one, the score between the two is very likely to be low. Finally, another
essential similarity measure can only be performed once a first alignment has
been produced. In a second alignment, as we will see, we can take into account
the distributional semantic similarity between words.
When this process is done, we have a list of aligned chunks, with gaps when the
Needleman-Wunsch found no possible alignment, as in the example in Figure 4. The
chunk Μέντωρ , ὅς ῥ ' hasn’t found a good
alignment and was thus paired with a gap.
Three post-processing steps are then performed. First, we remove all the gaps
from the source text. For example, if at the same index both the source sequence
and the target sequence are gap characters, the index of both lists is removed.
If the source sequence is a gap while the target one is not, the source sequence
is removed. The target sequence is then associated with either the previous or
the next sequence in the source text, based on which of these contains a
potential match for the proper noun in the target sequence
Once this first alignment and rearrangement is done, we proceed to yet another
alignment, this time taking into account the similarity between sequences
deduced from our distributional semantics method.
This step is performed through a small variation of a standard distributional
semantics model. The distribution of words in the text (both original and
translation) is modelled into a vector representing how many times a given word
occurs in each aligned original-translation block. In this way, the contextual
information which is usually taken into account in semantic spaces is removed
and the co-occurrence of bilingual couples in the aligned blocks emerges with
clarity. A French word and a Greek word occurring in the same sequence of
aligned blocks will have similar vectors. Through this method we manage to
automatically retrieve a small dictionary of word-translation pairs. Naturally,
the length of this dictionary is modifiable changing the similarity threshold
above which two elements are considered a word-translation pair. If the first
alignment was very noisy (for example with many gap and large blocks) we will
need a higher threshold to establish a meaningful correspondence, while a
cleaner first alignment will allow us to relax our acceptability constraints. It
also becomes evident if a text tends to use always the same translation for the
same set of words, or if it translates them differently in different contexts.
To this distributional dictionary, we add a specific MGiza dictionary. Once the
alignment of the corpus has been done, we use a wordtoword aligner called
MGiza++, the most recent version of Giza++. As it is multithreaded, the program
is much quicker, uses less memory, and the training process is more supple and
modifiable. The word-to-word alignment is done in two steps: first the
production of a co-occurrence tab (with the pre-implemented sent2cooc
algorithm), and an alignment based on “training models” (recursively
modifiable). MGiza++ uses IBM
[4] and HMM
[5]
[
Manmatha 2006] Models. These two models suggest that each word in
a corpus has its own non-arbitrary place, forming potential clusters with the
others, and that the position of the source and target words is highly dependent
on what surrounds them.
The result is a series of aligned pairs like in Figure 5.
It is possible to refine textual blocks by recollecting the beginning and end of
their opening and closing sentences. This final step creates meaningful blocks
that start and end with complete sentences, although this procedure requires
some precaution. Figure 6 shows an example of the alignment possibilities of the
interface.
The program was originally conceived with a Java interface. The application was
designed to be a purely local tool. However, when the time came to show our
results to a wide variety of researchers, we soon found out we needed a web
interface, to address the needs of specialists in Digital Humanities and a wider
range of literary researchers.
[6] The whole code is open-source, on
our GitHub repository, and the .jar may be compiled with the .jardesc file. The
web interface, although on a different repository, is built for this program.
The users input files, as can be seen in the open-source code, can be in several
formats, such as .doc, .txt or .xml. During the process, the program will
segment integral texts into its main components, such as chapters, parts or
books (essentially with the use of regular expressions when the scheme is basic
enough). For the
Odyssey, it is segmented in books.
The book-segmented texts are printed in xml files. We then apply our
NamesPatternMatcher to create xml files with elements segmented
by proper nouns. Each of these elements has its correspondent attribute
lemmatized and tagged. When the alignments have been done, the output is printed
in xml files with a fixed identification for each sequence, which allows us to
associate it with the source, but also with its corresponding targets.
Statistical comparison (number of occurrences of each term in the whole file,
number of occurrences for this precise identification and its correspondents,
etc.), phonetic comparison (phonetic similarities between source and target and
between different targets) and syntactical comparison (proximity with Greek in
the whole file, proximity with Greek for a precise identifier, etc.) allow us to
have a clear overview of all the translations at once. The web interface we
built for visualization allows us to visualize all the dynamically aligned text
simultaneously. One of the features that still remains to be added to the web
interface is a personal notebook for each user with the possibility of
commenting on chosen aligned sequences and hyper-linking those commentaries to
their specific identifiers.
In other words, the calculation capacity is not comparable to that of a human
being. One would not be able to measure, for example, the exact syntactical
proximity between the Greek text in regard to 50 different French translations
at once. The fact that one is able to analyse multiple translations at once
while focusing on extremely precise events in the texts also shows what the
whole process of translation studies hints at, that one does not simply read
Homer’s text, but only one singular aspect of it from a particular author.
Complete transparency of translation is not possible, and that is partly what our
tool shows. Although many sequences may convey the same general meaning, the way
each translator illustrates his perceptions in his own style shows the reader
that the
Odyssey is not just one text, but a myriad
of interpretations brought to us through translations. To fully understand this
variation, close-reading is not sufficient and may easily be faulty. One may be
able to make accurate statements on some correspondences between one source text
and one target text, but it is highly doubtful that the human brain would be
able to compare so many translations at once and get a clear view of all the
relevant information. Not only is the human process slower and riskier, but it
also does not allow the adjunction of all the metadata our program can take into
account, such as the association of unexpected expressions or words found thanks
to distributional semantics that help us visualize the evolution of different
concepts through time. Finally, some scholars, such as Noémi Hepp [
Hepp 1968], tend to present their own subjective judgements about
various translators as objective ones, while analysing the texts through
close-reading. The result is that, although Noémi Hepp might be considered as
deliberately controversial in this matter, some of her assertions about
translators that either she or translation critics of the time disliked are
clearly (both statistically and syntactically) unjustified.
We will show a set of results obtained using the method outlined above to analyse
a segment of our corpus of translations of the Odyssey. This analysis focuses on a specific portion of text,
extracted from the XIth book of the Odyssey (v.
3444). In this part of the paper, we would like to give an example of what
scholars may obtain using the program we made. We should proceed diachronically,
and see if we can spot trends and literary tendencies through the centuries.
However, every example we chose, though randomly chosen, can be compared, in our
program, to the 27 translations we digitalized. Figure 7 shows how a multiple
translation alignment looks in the interface and Figure 8 shows how a single
translation appears to the user, with different colors highlighting some
relevant elements of the text (hapax legomena, high frequency terms and so on).
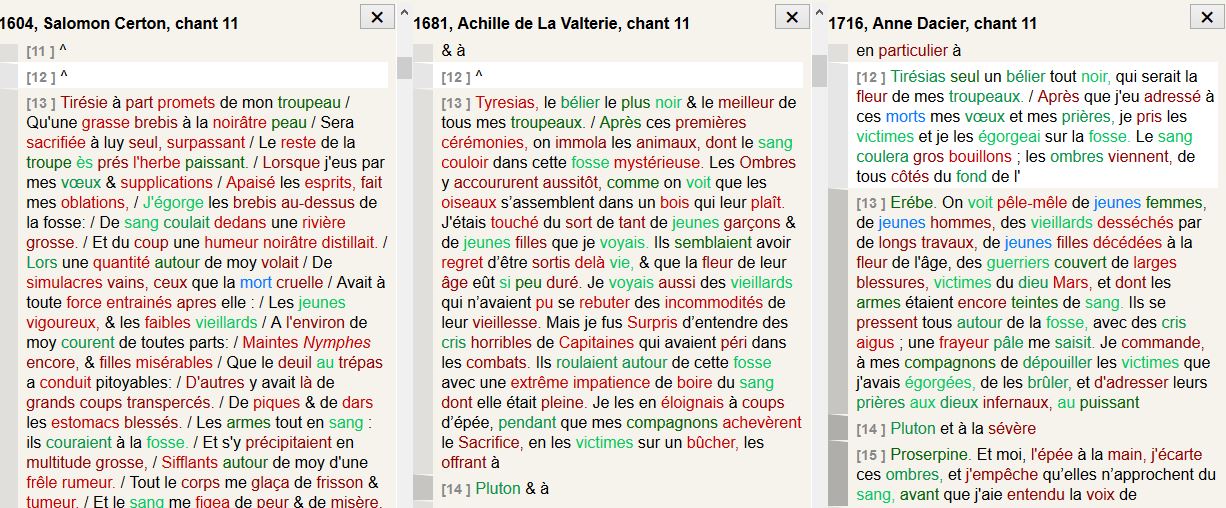
Salomon Certon
We first chose to compare Salomon Certon’s translation [
Certon 1604] with the others. The immediate post-Renaissance
period is a very rich time for Greek and Latin culture.
The idea that a cultural regeneration is deeply related to linguistic
regeneration flourishes. That is to say that French poets tend to seek their
own style within Ancient Epics. The general idea is that the skillful
translator should not slavishly imitate the author’s genius, but enrich it
by giving it his own skill and language (
translatio
studii). Translating appears therefore to be highly linked
with imitation. The same tradition is tangible in Ronsard’s followers’
works, such as in Amadis Jamyn’s
Iliad in
hexameters. The
Odyssey had only been partially
translated before Salomon Certon, and his attempt is the first ever to
translate the entire
Odyssey. Although Certon
translates the
Odyssey at the beginning of the
17th century, he is clearly inspired by the methods and traditions of the
16th century. He specializes in Latin metrics that he tends to reproduce,
and it is clearly visible that he has read Jamyn’s first three and
Peletier’s first two books [
Salel 1545], as he tends to
imitate them, or even cite them
pro verbo.
Initially he did not want to translate the whole
Odyssey, and it was Henri IV himself that asked for the
complete translation. But Certon did acknowledge his affiliation with his
predecessors, and did not count so much on innovation. Like Jamyn, he is not
such a good Hellenist, and is forced to repeatedly use Volterra’s Latin
translation, which was not even the latest and most accurate of his time. As
a result, many times, when Certon misses parts of the
Odyssey, it can be attributed to a Latin omission (while these
parts are present in his Greek version). However, his translation, as we
will see, seems to be nearer to the Greek than, for example, Jamyn’s. Certon
tends to reproduce more proper nouns than Jamyn, and is much nearer to the
Greek syntax and phonemes than his predecessor. As a result we could say
that his translation is not innovative in his translating habits, but that
being the first of its kind in terms of tackling the whole
Odyssey in French, he had to rely more heavily
than his predecessors on both Latin and Greek versions.
In this abstract we can see that the necessity of capturing Homer’s verses
causes an expansion of the text, leading to the presence of many hapaxes or
low frequency terms, that is to say words that are not present in any of the
other translations at this point of the text. For example, in “Lorsque j’eus par mes
voeux & supplications / Apaisé les esprits, fait mes
oblations”, the second line is an expansion and
cannot be justified by the Greek text. This suggests that Certon privileged
maintaining the metre over strict accuracy.
Comparing Certon’s translation with the others it is apparent that he
translates in “alexandrins”, and tends to drastically develop the Greek
text (his is one of the longest texts in our corpus). The verb “
λαβὼν” simply disappears. The word
“
κελαινεφές”, literally
“in black smoke”, becomes “
une rivière grosse et du
coup une humeur noirastre distilloit” (“an enormous river and from the neck
a black liquid ran”), which is a clarification and an
amplification. Many of Certon’s connotations cannot be deduced from the
Greek text, such as souls “
qui volent”
(“flying”), “
vaines”
(“empty”) (Christian heritage of the soul’s lightness). Death is
personified, which is quite far from the traditional pagan belief of the
souls’ peregrination. The tragic connotation is amplified. The “
Ἐρέβευς”, like in Volterra’s Latin
translation [
Maffei 1523], is absent. In fact, in his whole
translation, Certon tends to emphasize the gleam and shine of French.
Therefore, we may say that, if there is a kind of imitation of the Greek
text, it is more the imitation of a spirit rather than servile literal
imitation. Certon’s goal, when translating the
Odyssey is less a stylistic matter than a moral matter. For
Certon, the
Odyssey seems to have a moral
function much more than a purely aesthetic one.
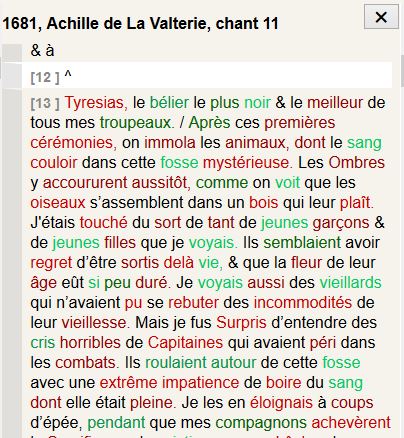
Achille de la Valterie, 1681
On the whole, we know very little about Achille de la Valterie. We know that
he was a “
jésuite”, but that he
renounced his vows later on. He is also known to have published a
translation of Juvenal’s and Perse’s
Satires,
and that he translated the
Iliad as well as the
Odyssey. His Homeric translations begin
with an “
épître”, from which we can
deduce his way of translating. First, he states that there is no need to
know about Homer’s life to translate Homer:
Quand on ne sait point
toutes ces choses, on a du moins l’avantage de n’être point obligé
de les oublier, après avoir perdu beaucoup de temps à les
apprendre.[7]
There is therefore no documentary value in Homer’s epics. And although he
states that strict proximity to the Greek text is one of his
goals
[8], he also states that Homer’s epics should not be left
unattended and may need consistent changes:
Pour prévenir (...) le
dégoût que la délicatesse du temps aurait peut-être donné de ma
traduction, j’ai rapproché les moeurs des Anciens autant qu’il m’a
été permis (...) [et] je n’ai osé faire paraître Achille, Patrocle,
Ulysse et Ajax dans la cuisine, et dire toutes les choses que le
Poète ne fait point de difficulté de représenter (...) je me suis
servi de termes généraux dont notre langue s’accomode mieux que de
tout ce détail.[9]
La Valterie has no real philological ambition. Indeed, from what we can get
studying his translations, La Valterie is an extremely poor Hellenist (it is
almost doubtful that he read any Greek at all) and mainly translated from
Latin, but also from existing translations (this is quite visible in our
program when you compare La Valterie’s translation [
de la Valterie 1709] to Boitel’s [
Boitel 1638], as
they have very rare terms in common in the same places and follow the same
syntactic structure, almost amounting to plagiarism).
Our program does help us to see immediately that La Valterie’s translation is
extremely far from the original text, and even contradictory with its
supposed source. A frequency study shows that the whole (or at least the
majority) of La Valterie’s translation is sewed with hapaxes (it is both far
from the Greek text and never used in any of the French translations), which
made it the most difficult text to align. We can also see that, although
most translators tend to reproduce important syntactic marks in Greek (full
stops, etc), La Valterie’s translation is the only one with no resemblance
whatsoever to the Greek syntax. This is visible in our example. Sentences
are long, there are frequent clarifications, tangible modalisations, and, of
course, many mistakes. It is also clear in this example that La Valterie
tends to avoid what he considers as trivial words and expressions, which
need to be either modernized or deleted. The word “cérémonies” may be justified (though it erases the
polysemic “εὐχωλῇσι” and
“λιτῇσί”, both
supplications and liturgical prayers), “se rebutter des incommodités de leur
vieillesse” (“grieving about the harshness of old age”) is a complex manner of
defining a much simpler down to earth single word in Greek, “πολύτλητος” (then again this whole
expression is an hapax, as no other translator will bother to be so
disdainful of a simple practical term). The word “Capitaines” is a condensation of war heroes adapted to
the 17th century.
Therefore, La Valterie’s translation is both very far from being accurate or
even faithful to the Greek. In later critical essays on Homeric
translations, especially in Madame Dacier’s work, which is discussed below,
La Valterie is seen as someone who has been left behind by the progress of
translation. His translation has been edited, reprinted, but there are still
no serious critics who say anything positive about it, quite the opposite in
fact. A few years late, La Valterie becomes the paragon of a moralist
translator; fit to feebly teach some moral values, but clearly unfit to
reveal Homer’s beauty. From the 17th century onward, practising translation
as a mere imitation is no longer an unquestionable principle.
Figures 9 and 10 show an alignment around La Valterie’s text and a small part
of the same text tokenized in blocks in the interface.
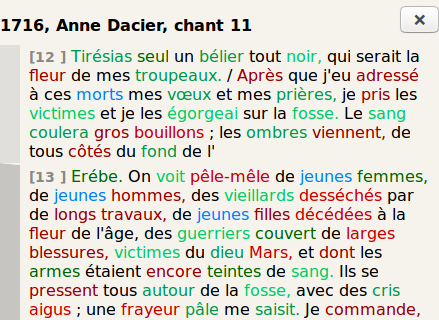
Anne Dacier, 1716
Madame Dacier’s note on this part:
Les six vers qui suivent celuici : Parce,
disaient-ils, qu’il n’est pas encore temps que ces Ames viennent,
& que d’ailleurs il n’est pas possible que les blessures
paraissent sur les Ames. Mais cette critique me parait trèsfausse.
Pourquoi n’est-il pas temps que ces Ames viennent, Homere ne dit-il
pas que les ombres des morts viennent de tous côtez du fond de
l’Erebe ? & ne reçoivent-ils pas ce vers ? Les six qui le
suivent n’en font que l’explication. Quant aux blessures, il est
bien vrai qu’elles ne peuvent paroître sur la partie spirituelle de
l’Ame, aussi n’est-ce pas de celle-là dont Homere parle, puisque
les Morts ne l’avaient plus ; il parle du corps subtil de l’Ame,
& tout ce qui avait blessé le corps terrestre, avait aussi
blessé le corps subtil, & y avait laissé sa marque. Voilà
pourquoi il est dit que dans les songes on voit les Ames dans le
même état où sont les corps, & voilà aussi d’où vient la
difference qu’Ulysse remarque dans ces ombres. Ce qui me parait le
plus surprenant ici, c’est ce qu’Ulysse ajoute, que ces Ames avaient
encore leurs armes, & que ces armes étaient encore teintes de
sang. Comment ces Ames, ces Ombres, qui n’étaient que le corps
subtil de l’Ame, pouvaient-elles conserver leurs armes ? Je crois
que c’est un point nouveau qu’Ulysse ajoute ici à la Theologie
reçue, & qu’il ajoute, parce qu’il parle aux Pheaciens, peuple
peu instruit.
The first turning point in contrast with this tendency seems to appear with
Madame Dacier’s translations (from what we gathered from the program,
studying the texts diachronically). Anne Lefebvre Dacier (known as “Madame
Dacier”), wrote her translations as a reaction to Homeric imitations.
Many translators had followed the same principles as La Vallterie for at
least a century. The
Iliade by La Motte [
Houdart de La Motte 1714] is one of the many examples of a tendency to
transform the epics into an “up-to-date” version. In this general
atmosphere, Madame Dacier is an exception. She was very fond of Greek and
Latin from a very young age, and was given the chance to grow up with just
as much education as a man thanks to her father. Though small and, above
all, a woman, her strong character and her excellent knowledge of Greek
forced her peers to acknowledge the quality of her many
publications
[10]. She is a paragon of scientific, archaeological and
philanthropic knowledge of Homer’s works. As she says herself in her
Iliade:
Je n’écris pas pour les savants qui lisent
Homère en sa langue (...) j’écris pour ceux qui ne le connaissent
point, c’est à dire pour le plus grand nombre, à l’égard desquels ce
poète est comme mort.
[Dacier 1712]
Although she states that her work is not made to be a philological
translation, it is clear that the amount of research and stylistic work in
her translations is enormous
[11]. The
Odyssey
[
Dacier 1717] is heavily annotated (the notes generally take
three quarters of a single page). She wants her readers to see Homer as he
is, not as he should be in a contemporary world. Therefore, she has to
explain many of the incoherences and cultural gaps that would make Homer
incompatible with the modern world. She tends to justify shocking
descriptions or attitudes in the
Odyssey by
saying that those were acceptable because they were different, and justifies
her assertions both philologically and archaeologically. She also tends to
erase most of Homer’s stylistic specificities, as they have no scientific
purpose.
Dacier uses common terms for the society she lives in, uses simplified
syntax, and above all annotates her text enormously. We included the notes
and explanations directly in the text but did not align them. What is most
visible in this abstract is that Dacier tends to respect the length and
syntax of the Greek text, much more than her predecessors. It is also
visible that she initiates this tendency for the following translators such
as Bitaubé (for more details on syntactic proximity after Madame Dacier, see
our website). She erases the polysemy of the Greek word “κελαινεφές”, interpreting it in a
logical and clarified way (leaving aside both the smoky effect and its
blackness). She just translates the expression “νεκύων κατατεθνηώτων” by “les ombres”, erasing the redundancy like “the dead
that have lived”. Dacier definitely wants to imitate the Greek
syntax, keeping the paratactic “τε”:
this is quite visible in the important similarity to the Greek throughout
the text (see greyer colums). She also chooses to clarify the polysemous
word “νεοπενθέα”, with the images of
both sorrow and flowers. She adapts the deity Ares into Mars who would be
more familiar to her audience, and she is one of the rare translators (along
with Bitaubé) to use this adaptation. We decided to add the footnote we
included, as it shows Dacier’s desire to explain the war heroes’ death in
terms of Christian beliefs. There is no phonetic proximity to the Greek
whatsoever. She does not simply want to imitate Homer but to make him
understandable for her readers and so phonetic imitation, which is seen
later in Leconte de Lisle, would be counter-productive. It is also
noticeable that this abstract contains a large amount of green words, while
earlier translations do not.This means that many of the words she uses were
then imitated and reproduced by her followers. From the imitative flowery
pomp we got from the previous century, we now get a form of puritanism from
this erudite translator.
Figures 11 and 12 show an alignment around Dacier’s text and a small part of
the same text tokenized in blocks in the interface.
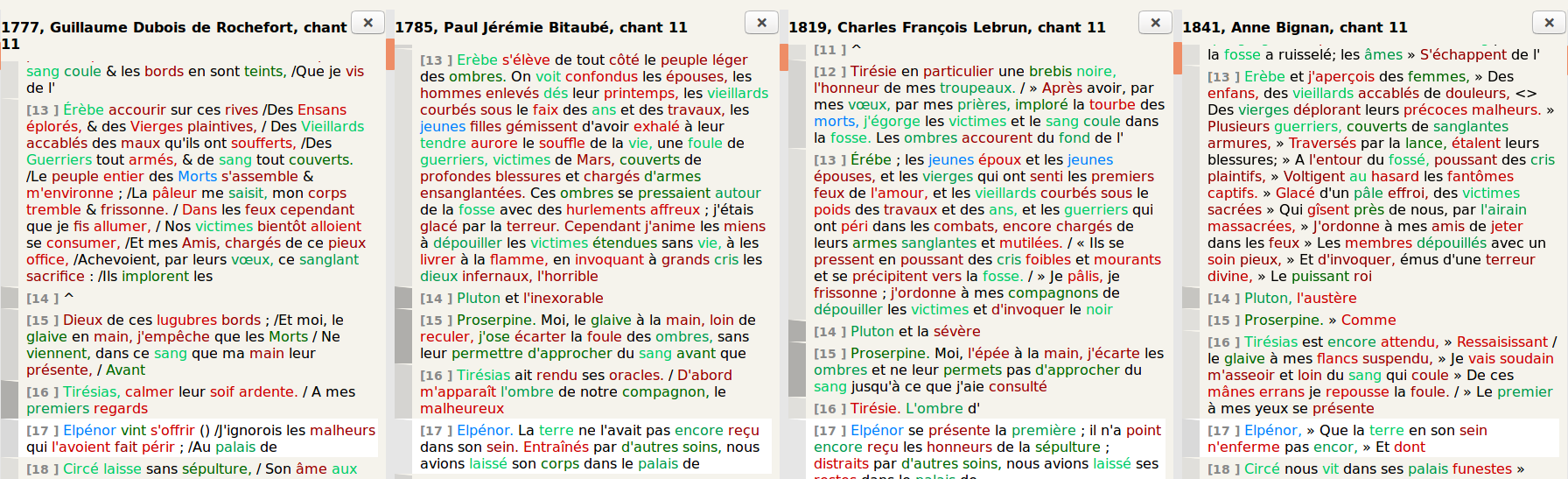
Paul Jérémie Bitaubé, 1785
Bitaubé’s works show similar tendencies as Dacier’s. Bitaubé’s native
language was German. When he decided to learn French, he saw it as a
scholarly language, a language that tends towards excellence. Thanks to his
first publication of the
Odyssey
[
Bitaubé 1764], he became an academic in Berlin. He decided
for a scholarly style that he calls “
prose
cadencée” (“prose in rythm”):
Il n’est pas aisé
d’écrire dans une prose cadencée, harmonieuse, qui s’élève (elle
le peut), au ton de la poésie ; et je soutiens que la gêne d’une
grande fidélité, lorsqu’on s’y assujettit scrupuleusement, n’est
pas si éloignée qu’on le pense de celle de traduire en
vers.[12]
To assert this scientific ambition, Bitaubé is one of the first to
explicitly mention any translator before him. What is more, not only does
Bitaubé want to be exact in the meaning, he also aims at accuracy
concerning style, imitating, as much as possible, Homer’s brevitas. As a result, in only one century, the
reader goes from imitative flowery pomp to scholarly puritanism. In our
text, Bitaubé tries to maintain both the Greek syntax (just as Dacier did),
but also its polysemous terms. For example, where Dacier used two
coordinates, for “λαβὼν” and
“ἐλλισάμην”, Bitaubé
chooses juxtaposition, maintaining the Greek hypotyposis. The blackness and
the liquid aspect of the “κελαινεφές” is now explicit (“les noirs torrents”). Bitaubé also attempts, as much
as possible, to reproduce the Greek redundancy “νεκύων κατατεθνηώτων”. Finally, he strictly imitates
the Greek syntax, maintaining the paratactic syntax and the adjectives
describing the dead.
After Bitaubé, the 19th century flourishes with many translations of Homer’s
epics. The French Revolution, and especially the Terror has given a new
gleam to the ancient poets, supposed to be the witnesses of a higher moral
value, lost in modern times, both aesthetically and politically. Bitaubé is
in an in-between conception of the Greek literature as the “Dictionnaire bibliographique à l’usage des
collèges” will say about him,
Il s’applique à conserver
la marche et les formes de la phrase grecque, il imite assez bien
l’abondance et la rondeur de l’original, et sa traduction a un air
antique, et ne manque pas d’un certain charme ; mais l’audace, la
majesté, l’éloquence variée d’Homère, la richesse de ses couleurs,
le mouvement rapide de son style, la hardiesse et l’impétuosité du
langage, on les cherche en vain ; on lui demanderait plus vainement
encore la mollesse et la grâce, l’harmonie générale du style
homérique, les expressions touchantes, cette mélodie suave[13]
A major evolution can be noticed here; a greater attention is given to
Homer’s style rather than moral teachings, and Bitaubé, although frequently
reprinted at the time, especially in school books, is not criticized for the
possible rashness of his translation, but on the contrary for his lack of
Homeric style.
Figures 13 and 14 show an alignment around Bitaubé’s text and a small part of
the same text tokenized in blocks in the interface.
Charles François Lebrun, 1819
The thermidorian reaction to this way of perceiving the Classics puts to an
end the cult of a lost Antique virtue. Volney, for example, will say:
Ce sont ces
livres classiques si vantés, ces poètes, ces orateurs, ces
historiens, qui, mis sans discernement aux mains de la jeunesse,
l’ont imbue de leurs principes ou de leurs sentiments. Ils ont
oublié que cette prétendue république, diverse selon les époques,
fut toujours une oligarchie composée d’un ordre de noblesse et de
sacerdoce, maître presque exclusif des terres et des emplois, et
d’une masse plébéinne grevée d’usures, n’ayant pas quatre arpents
par tête, et ne différant de ses propres esclaves que par le droit
de les fustiger, de vendre son suffrage, et d’aller vieillir ou
périr sous le sarment des centurions, dans l’esclavage des camps et
les rapines militaires.[14]
As a result of this violent reaction, the Greek will again be given to the
youth of the time, but not as a moral model, but much more as a potential
source of erudition and scientific knowledge. Le Prince Lebrun is one of the
heirs of such teachings.
Le Prince Lebrun is, above all, a
homo
publicus. He escapes many of the massacres from the French
Revolution, avoids death during the final period of Napoleon’s reign, and
holds many public offices. His
Iliad,
translated when he was young, was an exercise to make himself famous among
the erudite society. His
Odyssey
[
Lebrun 1819], however, is the work of a man that has already
achieved social fame. He is one of the many men of power to demonstrate, by
publishing poorly translated works, his ability to be both an important man
and a scholar. His works, as a result, though very well known at the time
and republished many times, were completely forgotten thirty years after his
death.
In our text, we can see that he tends to strictly imitate the Greek, often in
a clumsy way, and sometimes with great inaccuracy. This entire translation
has no footnotes, no preface, no post-face. He has none of Dacier’s or
Bitaubé’s ethnographic care, although it is clear that he has read Bitaubé,
as we can see from our program, as he reuses many words that had previously
only be used by Bitaubé. This translation is the direct result of the
educative principles initiated by Dacier and Bitaubé.
Lebrun’s translation is an echo of the way Greek was taught at the time.
Indeed, an enormous amount of partial scholarly translations appear during
the second half of the 19th century that clearly tend to privilege the
strict accuracy to the Greek text, without the help of Latin. The Greek
Classics have become a source of linguistic benefits (the necessity to learn
Greek at the time is often justified by the ability it should give to
students to enhance their intellectual capabilities as well as their
analytic skills, reasoning, and logic) and ethnological information (the
Greek text should be perceived as a literary testimony).
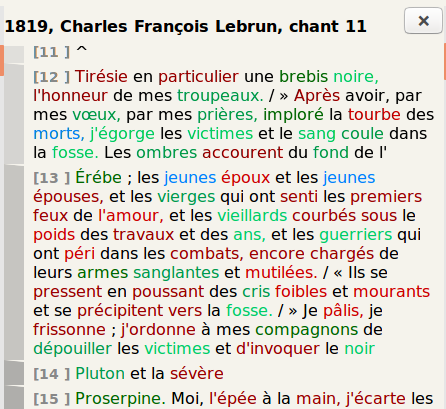
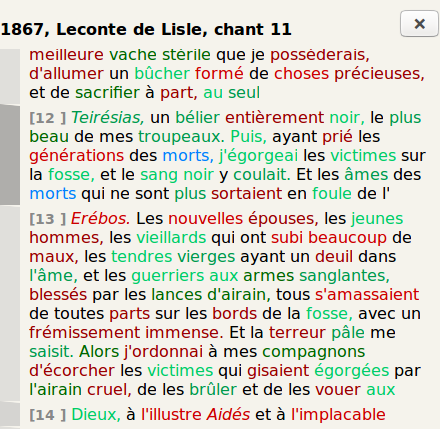
Figures 15 and 16 show an alignment around Lebrun’s text and a small part of
the same text tokenized in blocks in the interface.
Edouard Sommer, 1854
From the second half of the 19th century, many juxtalinear translations are
published. For the first time, the aim is to publish a large amount of
abridged translations, and if a certain abstract has more success than
others, publish the entire translation. These translations are
typographically recognizable; the first page is a word-to-word translation,
unreadable and not supposed to be fluent, and the second page is a
linguistically acceptable translation. This practical use of translation
reveals two essential points in the evolution of translation practices.
Firstly, in order for a translation to be judged adequate, it must show that
the translator perfectly understood the syntactic problems of the Greek text
and secondly, that Greek and Latin studies have never been more important in
general education.
However, Sommer’s many translations [
Sommer 1854] do not aim at
being original or stylistically distinguishable, but mainly tend to explain
Greek syntactic problems. In our text, Sommer never omits a single word,
keeping each redundancy, without seeking poetic effects (e.g.: the “
ψυχαὶ
νεκύων κατατεθνηώτων” is simply translated by
“
les
âmes des morts”). What is more, Sommer tends to
maintain Greek temporality: he keeps aorists and imperfects, not considering
French habits (“
la pâle crainte s’emparait de moi”,
“the pale dread was getting
to me”). Sommer’s translation is clearly and without any doubt
the nearest text to the Greek syntax. The syntactic similarities are at
their highest points throughout the text. What is more, the text displays an
enormous amount of green and blue words, that is to say extremely frequent
words. He does not aim at originality, but at reproducing the meaning word
by word. Finally he is one of the rare 19th century translators (along with
Leconte de Lisle) who share such a close proximity to the Greek at this
precise point.
Both Latin and Greek Classics seem at this time to have regained a certain
prestige. Many of the abridged translations are made for school use, and
their notes and parallel analysis show a new grammatical perception of both
languages. Almost paradoxically, the extreme accuracy asked for from the
students will sometimes generate much bolder translations such as Leconte de
Lisle’s.
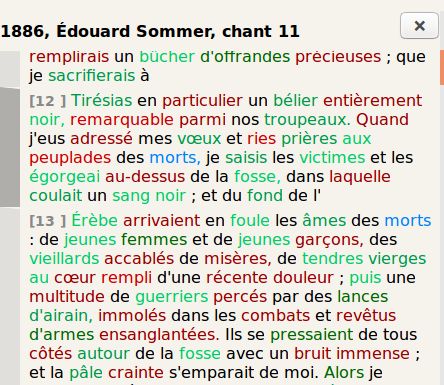
Figures 17 and 18 show an alignment around Sommer’s text and a small part of
the same text tokenized in blocks in the interface.
Charles Marie René Leconte de Lisle, 1867
In this period translators stop adapting the text to their own language and
culture, but enrich their own style with the contact of strangeness. The
climax of this tendency seems to be reached with Leconte de Lisle [
Leconte de Lisle 1867]. Not only does he use rare terms or even
hapaxes, but he also creates neologisms, and imitates the Greek itself as a
sound. Leconte de Lisle was one of the reasons we used the Greek text as
pivot as he is often quite literal in his phonetic imitations (he is without
doubt the author that has the more italics in his text); this means it tends
to be very different from traditional syntax. Indeed, the goal might have
been first to disassociate the reader from his own
hic et nunc, for lost and far away realities, but also to
create a form of poetic hermetism. As a result, the program points out that
in Leconte de Lisle’s translation there are many hapaxes and many word
similarities with the Greek, which is to say archaisms
[15]. The goal is clearly to recreate a complete work of art,
poetic and independent from its source for a renewed modern language. In our
text, what is most noticeable is that Leconte de Lisle maintains most of the
Greek syntax and uses an enormous amount of hapaxes (the first in our whole
corpus to use so many hapaxes). In the first sentence, he strictly imitates
Greek temporality, and he is the first to explicitly keep the perfect
participle
κατατεθνηώτων (accomplished
fact) with “
les morts qui ne sont plus” (“the dead that are no
more”). The
Ἐρέβευς is also
phonetically imitated, as shown with the italics, translated as “
Erebos”. The following sentence exactly
maintains the Greek syntax (nominative juxtapositions, demonstrative pronoun
“
οἳ”). But what is more,
Leconte de Lisle maintains, as much as possible, every assonance and
alliteration present in the Greek text (“
θεσπεσίῃ
ἰαχῇ”, with three and two syllables: “
frémissement immense”, with three and two
syllables). Even the books themselves are not books anymore but
“rhapsodies”. This tendency illustrated by Leconte de Lisle is
clearly seen at the time as an emancipation. Translating means working not
only on a source language, but on French itself. The fact that a new kind of
French is needed is visible in the way translators deliberately skew common
meanings and usage. Translation is not perceived only as a symbolic means of
understanding ideas and culture, but also as a new way to express impression
and sound. Translation itself is a new work of art.
However popular Greek studies might have been during the second half of the
19th century, their descent is quite tangible throughout the 20th, and so is
a drop in interest for literary Greek translation, especially in the first
twenty years of the century. This descent goes hand in hand with the
increasing specialization of scientific and documentary matter. Knowing
Greek means more and more that one should be familiar with a precise
contextualized Greek reality and history. The study of Greek becomes the
study of Greek history and archaeological value, not so much as purely
developing a stylistic and grammatical ability.
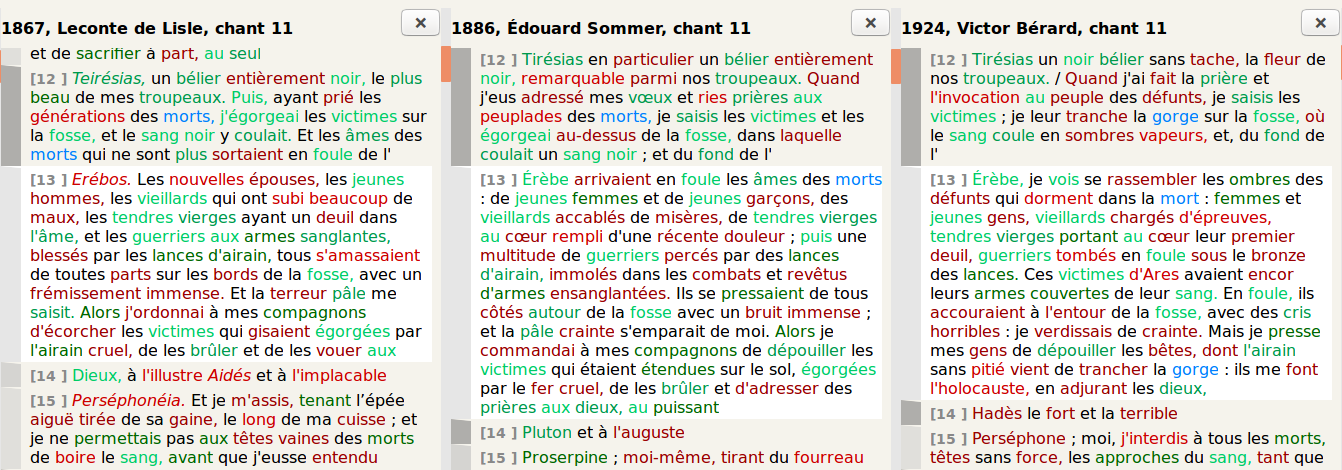
Figures 19 and 20 show an alignment around Leconte de Lisle’s text and a
small part of the same text tokenized in blocks in the interface.
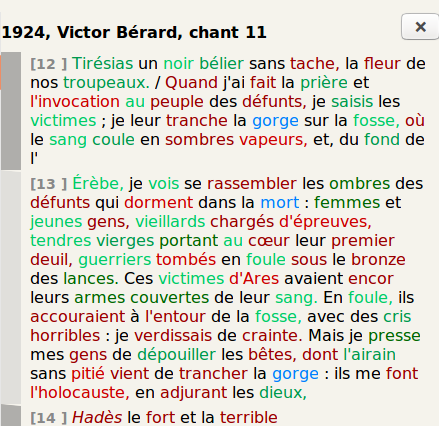
Victor Bérard, 1924
Victor Bérard considered Homer’s
Odyssey both
as a literary masterpiece and a considerable source of archaeological
information; he saw the epics as both a poem and a document. As a result,
Bérard’s translation [
Bérard 1924] was paradoxically easy and
challenging to align. It was easy because Bérard tends, writing in
hexameters, to reproduce the syntactic movement of the Greek verse. He also
tends to keep the polysemous aspects of each particular word as well as
keeping in mind the principle of
brevitas.
As a result, if we compare the syntax of each aligned chunk with its Greek
correspondent, we find an extraordinary proximity of length and syntax,
almost as high as Sommer’s. However, it was also, in some parts, difficult
to align. This is because because, being an archaeologist, Bérard tends to
force the original text into his own present reality. For example, he tends
to change toponyms so that they match real places in modern Greece. This
characteristic found in many of Bérard’s translations and works on Antiquity
has been qualified as the “
complexe de Victor Bérard”
[
Montalbetti 1997]. Bérard wanted to locate every single
topos described in the
Odyssey
in the modern world. To do so, from 1902 to 1912, he travelled throughout
the Mediterranean sea, and wrote four volumes of 400 pages each entitled
Les Navigations d’Ulysse
[
Bérard 1927]. These
Navigations
follow Ulysses’ path throughout the
Odyssey.
Later in the
Sillage d’Ulysse
[
Bérard 1933], Bérard collects all the photographs Fred
Boissonnas, who accompanied him on his trips, took in Greece and identified
each one as a specific Homeric
topos. This
is symbolic of what Bérard thinks about the art of translation, that it is
as much archaeological research as it is a poetic activity. He views it as a
way of combining past and present into a single universal reality. In our
text, Bérard mainly imitates the natural movement of the Greek line, using
the hexameter. For the first time, every Greek word is translated, this time
in the iconic
brevitas style, which makes
this translation a true masterpiece, being both poetic and precise. For
example, “
κελαινεφές” is translated by “
les sombres
vapeurs” which is the shortest and yet the most
literal translation we have. The same thing can be noticed about the word
“
θύμος”, erased from so many translations before,
literally maintained without awkwardness, by “
portant au
coeur” (“bearing in their heart”). Let us also notice that the dread does
not have a clarity, but a color, a characteristic that he will be the first
one to use, and the nearest to the Greek so far. What is more, Bérard is
the first since Certon to fully express Odysseus’ fear with the hypotyposis
present throughout the description of the dead, and keeping the paratactic
asyndeton. We can notice a true evolution with Bérard’s translation,
initiated, we may suppose, by Leconte de Lisle. The strangeness of Greek
must be assumed both as a philologic information for the Hellenist and an
aesthetic novelty for the poet. We can therefore also see Bérard, apart from
Leconte de Lisle, as one of the first to assume fully Greek proper nouns,
many of which are in italics. We can also see that his translation, still
one of the most well known in France today, has been reused and changed (in
very different ways), both by Philippe Jaccottet and Frédéric Mugler.
Indeed, Frédéric Mugler is often seen to reuse Bérard’s translations without
citing him, which we can see in our program as he uses expressions that have
a very low frequency and that are only present in Bérard’s translation. For
example, just like in Bérard, the invocation is made to the “
peuple des
défunts”, the animal’s throat is “
tranchée” (just as in, and only in, Bérard and
Jaccottet), the old men are “
chargés d’épreuves”, and
finally the dread is described with exactly the same words, “
je
verdissais de crainte”. Concerning Jaccottet, it
seems to be a quite different matter, as he is the first, after Bérard, to
use French verses to translate the Greek epics.
Figures 21 and 22 show an alignment around Bérard’s text and a small part of
the same text tokenized in blocks in the interface.
Philippe Jaccottet, 1955
We chose to analyze Jaccottet’s translation here [
Jaccottet 1955], as Jaccottet declares himself as an heir to Bérard (although not
entirely). We should just stress that with the program we could spot two
schemes: firstly Jaccottet’s lines, just like Bérard’s, tend to reproduce
Greek syntax, secondly, Jaccottet uses high frequency and everyday words,
which sets him apart from Bérard. This tends to illustrate what Jaccottet
may say himself about his own style: expression should be “
loyale” (both “accurate” and
“faithful”). From a translator’s point of view, this first means
that there is a promise of truth between the word and the object it
represents, but also between a foreign word and a familiar word. As
Jaccottet states himself:
Y entendre ne fût-ce qu’un écho très
affaibli de l’admirable musique originale, il faut alors traduire,
dans la mesure du possible et sans tomber dans l’absurde, selon la
lettre même du texte. De même, il faut écouter plutôt que lire,
ainsi [...] le texte retrouve sa lenteur nécessaire, son mouvement,
quelque chose de sa résonance.[16]
Both Bérard and Jaccottet, though to different extents, embody this
increasing attention to the poetics of their source material and the need to
reproduce an echo of what has been lost. In our text, we can first notice a
symmetric inversion of the syntactic order, emphasizing the liturgical
aspect of the scene and the Homeric tendency to maintain the hesitation
between the narrative and the incantation. The expression “les deux
bêtes” (“the two
beasts”), most unusual, may be due less to the context than to
the phonic imitation of δὲ. The word
“trou” is almost shocking, but
then again reflects the phonic imitation of βόθρον, and its extreme simplicity (an essential notion in
Jaccottet’s poetry). The problematic expression “ψυχαὶ νεκύων
κατατεθνηώτων” is translated with apparent ease,
both keeping the pleonasm and the naturalness of the language, with “les âmes des défunts
trépassés” (“the
souls of the departed dead”). The adjective “étrange” (“strange”) maintains
Odysseus’ uneasy feeling (implied by “θεσπεσίῃ”), and while Jaccottet maintains the final
imperfect (also visible in the Greek text), he gives it an inchoative
connotation, which is most original. Finally, let us point out that there
are no capitals in Jaccottet’s poetry, corresponding both to his own
principle of “effacement”
(“disappearance”) and to a vision of poetic rhythm (conceived as a
blow, a wind, which should not be stopped).
Here we showed a larger sample of Jaccottet’s abstract, as a smaller sample,
similar to ones used for other translations, would not have highlighted
Jaccottet’s exceptional attention to accurately recreating the Greek. As we
saw, he tends to reproduce as many phonemes as he can, and many of his
proper nouns, but also many inner words, are in italics, and he has an
exceptional high similarity with the Greek syntax, comparable only to
Sommer’s.
Both Bérard and Jaccottet, following the path Leconte de Lisle had
initiated, have contributed to a new perception of translation, as a
masterpiece both in debt and independent from its source. We would like to
conclude this analysis of Jaccottet’s work with one of his own elegant
statements about translation in his preface:
Et tel aura été le
rêve, utopique, de cette traduction, défectueuse comme toute
traduction : que le texte vienne à son lecteur ou, mieux peutêtre,
à son auditeur un peu comme viennent à la rencontre du voyageur
ces statues ou ces colonnes lumineuses dans l’air cristallin de la
Grèce, surtout quand elles le surprennent sans qu’il y soit
préparé ; mais même quand il s’y attend, elles le surprennent,
tant elles viennent de loin, parlent de loin, encore qu’on les
touche du doigt. Elles demeurent distantes, mais la distance d’elles
à nous est aussi un lien radieux.[17]
Figures 23 and 24 show an alignment around Jaccottet’s text and a small part
of the same text tokenized in blocks in the interface.
The program we made was extremely effective at analysing and identifying
different trends and patterns in a range of French translations from the
16th to the 20th century. Thanks to our efforts in alignment and improvement
of NLP tools within a single interface, we tried to give the common user
access to potentially enriched literary analysis. This has only been a
sample, but we hope to develop both our corpus (in different languages) and
our tools in future months.
Conclusion and future work
Translation studies, but other fields as well, would benefit from such a
quantitative and qualitative approach, as many researchers would not have to
rely on intuition or personal estimation of manual comparisons, but could have
access to actual quantitative and qualitative results and facts, that could not
be obtained otherwise. Here we gave an example of a possible diachronic
interpretation done with the help of such a tool. Many works on the history of
translation
[18] have been
printed where the researchers’ potential could not be given its full expression
due to the lack of data or the massive aspect of the analyzed corpus. Although
our work is still in progress, our goal is to fill that gap.
In our analysis we tried to show that there is a tangible and possibly
explainable evolution in the way French translators saw and practised
translation from the 16th to the 20th century. At the beginning, when the
Homeric text was barely known and barely accessible in common language,
translation was more a matter of imitatio than
proper translatio. The source text would be
used as a moral pivot to enhance the inner stylistic value of the target
language. Translations were then quite far from the original, both because Greek
language was very poorly known, and because there was a need for a national
poetry that could not be satisfied by merely copying pro
verbo. This perpetual adaptation and, some might say, mutilation
of the Greek text found its counterpart later on in a renewed interest in the
Greek text itself. This view led to the idea that the original text needed to be
re-evaluated and cleaned of all its modern modifications. Following this, there
was a movement to make the Greek language and Greek archaeological culture more
accessible to scholars and the wider public. Translations were then nearer to
their source and more respectful of its historical foundation. This new
scholarly interest in the Greek itself led to a wider grammatical and scientific
study of the language both in universities and schools. All translations of the
19th century are conditioned by this new linguistic approach, less and less
caring about its moral potential teachings. But the knowledge of the Greek,
precisely because of this grammatical and linguistic specialisation, was
progressively confined to a more restricted and scholarly area. The Homeric
epics became considered, especially after the First and Second World Wars of the
20th century, both as a poem and as a document. Therefore, up to Jaccottet’s and
Mugler’s translation, it did not lose its poetical value, but it was more
recently perceived as some forgotten sound, some echo of a culture that is
nowadays lost and that one cannot pretend to fully adapt to modern times.
The program discussed in this paper has a variety of applications depending on
the interests of the researcher. These applications include analysing individual
authorial style or analysing the style of individual translations; they also
include comparing translations with the source text as well as comparing
different translations. The analysis presented in this paper is focused on a
short sample of the Odyssey and various
translations. A longer work would be able to address questions of whether these
translations are representative of contemporary literary fashions and styles, as
well as common cultural conceptions of the eras in which they were written.
If these results are interesting in one language, it would be even better to
conduct research on diachronic translation corpora in different languages. Since
the alignment program works for many European idioms, similar research would be
possible using the same system. Aligning multilingual translations we could both
compare the features of contemporary translators in different languages aligned
to the original text and align different translators between themselves (for
example, we could align Madame Dacier’s Iliade with
Casanova’s Iliade), a direct way to compare styles
and approaches. We would like to compare, for example, the set of French
translations of the 11th book with a small group of Italian translations of the
same text, to identify unique and different trends in different languages.
Works Cited
Allauzen 2009 Allauzen, A., Wisniewski, G.
"Modèles discriminants pour l’alignement mot-à-mot", Traitement Automatique des Langues, 50 (2009): 173–203.
Bitaubé 1764 Bitaubé, PJ. L’Iliade: Traduction Nouvelle, Précedée De Réflexions Sur Homere.
Prault (1764).
Boitel 1638 Boitel, C. L’
Odissee D’Homere. La Coste (1638).
Boschetti 2009 Boschetti, F., Romanello, M.,
Babeu, A., Bamman, D. and Crane, G. "Improving OCR accuracy for classical
critical editions", In International Conference on Theory
and Practice of Digital Libraries. Springer (2009), pp.
156–167.
Boschetti 2013 Boschetti, F. "Acquisizione e
Creazione di Risorse Plurilingui per gli Studi di Filologia Classica in Ambienti
Collaborativi.” In M. Agosti and F. Tomasi (eds), Collaborative Research Practices and Shared Infrastructures for Humanities
Computing, Proceedings of Revised Papers AIUCD (2013).
Brown 2003 Brown, P. F., Pietra S. A. D., Pietra V.
J. D., Mercer R. L. “The mathematics of statistical machine translation:
parameter estimation”, Computational linguistics,
19 (1993): 263–311.
Bérard 1924 Bérard, V. L'Odyssée: Chants VIII - XV. Les Belles Lettres (1924).
Bérard 1927 Bérard, V., Bérard, A. Les Navigations d’Ulysse. Armand Colin (1927).
Bérard 1933 Bérard, V., Boissonnas, F. Dans le sillage d’Ulysse (photographies de Fred.
Boissonnas). Librairie Armand Colin (1933).
Certon 1604 Certon, S., L'Odyssée d'Homère au Roy, de la version de Salomon Certon,
Langelier, (1604).
Chevrel 2012 Chevrel, Y., Hulst, L d’., Lombez,
C. (eds), Histoire des traductions en langue française, XVe
et XVIe siècles. Verdier, Lagrasse (2012).
Chevrel 2012a Chevrel, Y., Hulst, L d’., Lombez,
C. (eds), Histoire des traductions en langue française,
XIXe siècle. Verdier, Lagrasse (2012).
Chevrel 2014 Chevrel, Y., Cointre, A.,
Tran-Gervat, YM. (eds), Histoire des traductions en langue
française, XVIIe et XVIIIe siècles. Verdier (2014).
Colonne 1476 Colonne, G. Historia destructionis Troiae. Van Westfalen, Johannes
(1476).
Dacier 1692 Dacier, A. Comédies grecques [d’Aristophane]. G. Gallet (1692).
Dacier 1699 Dacier, A. Les
poesies d’Anacreon et de Sapho, traduites de grec an françois, avec des
remarques. Par Madame Dacier. chez Paul Marret, marchand libraire
dans le Beurs-Straat, à la renommée (1699).
Dacier 1712 Dacier, A. Ilias. Aux dépens de la Compagnie (1712).
Dacier 1714 Dacier, A. Des
causes de la corruption du goust. Rigaud (1714).
Dacier 1717 Dacier, A. L’Odyssée d’Homère. aux dêpens de la Compagnie (1717).
Dekker 2011 Dekker, RH., Middell, G.
"Computer-Supported Collation with CollateX: Managing Textual Variance in an
Environment with Varying Requirements", Supporting Digital
Humanities, (2011): 17–18.
Dekker 2015 Dekker, RH., Van Hulle, D., Middell,
G., et al. "Computer-supported collation of modern manuscripts: CollateX and the
Beckett Digital Manuscript Project", Digital Scholarship in
the Humanities, 30 (2015): 452–470.
Déchelotte 2007 Déchelotte, D., Schwenk, H.,
Bonneau-Maynard, H., et al. "A state-of-the-art statistical Machine Translation
System based on Moses", In MT Summit. (2007), pp.
127–133.
Gabbrielli 2010 Gabbrielli, M., Martini, S.
Programming Languages: Principles and
Paradigms. First. Springer London (2010).
Gale 1991 Gale, William A., and Kenneth Ward Church.
“Identifying Word Correspondences in Parallel
Texts”. HLT. Vol. 91, (1991).
Gamma 1995 Gamma, E., Helm, R., Johnson, R., et al.
Design Patterns: Elements of Reusable Object-oriented
Software. Addison-Wesley Longman Publishing Co., Inc., Boston, MA,
USA (1995).
Gao 2008 Gao, Q., Vogel, S. "Parallel implementations
of word alignment tool", In Software Engineering, Testing,
and Quality Assurance for Natural Language Processing. Association
for Computational Linguistics (2008), pp. 49–57.
Gao 2008a Gao, Q., Vogel, S. "Parallel
implementations of word alignment tool", In Software
Engineering, Testing, and Quality Assurance for Natural Language
Processing. Association for Computational Linguistics (2008), pp.
49–57.
Gao 2011 Gao, Q., Lewis, W., Quirk, C., et al.
"Incremental training and intentional over-fitting of word alignment", Proceedings of the Thirteenth Machine Translation
Summit, (2011): 106–113.
Garnier 2002 Garnier, B. "Anne Dacier, un esprit
moderne au pays des Anciens", Portraits de
traductrices, (2002): 13–54.
Germann 2016 Germann, U. "Bilingual document
alignment with latent semantic indexing", In Proceedings of
the First Conference on Machine Translation. (2016).
Gomaa 2013 Gomaa, WH., Fahmy, AA. "A survey of text
similarity approaches", International Journal of Computer
Applications, 68 (2013).
Hasan 2007 Hasan, FM., Uzzaman, N., Khan, M.
"Comparison of different POS Tagging Techniques (N-Gram, HMM and Brill’s tagger)
for Bangla", In Advances and Innovations in Systems,
Computing Sciences and Software Engineering. Springer (2007), pp.
121–126.
Henning 2009 Henning, M. "API Design Matters",
Communications of the ACM, 52 (2009):
46–56.
Hepp 1968 Hepp, N. Homère en
France au XVIIe siècle. (1968).
Houdart de La Motte 1714 Houdart de La Motte, A.
L’Iliade: poëme. Gr. Dupuis (1714).
Jaccottet 1955 Jaccottet, P., Hartog, F. "Homère:«L’Odyssée»", Paris, Club français du livre
(traduction qu’a reprise, en 1982, la Librairie François Maspéro, puis, en
1992, La Découverte), (1955).
Lebrun 1819 Lebrun, C-F. Odyssée, traduite en français par le Prince Lebrun. Ch. Gosselin
(1819).
Leconte de Lisle 1867 Leconte de Lisle, C. M. R.,
L’Odyssée, traduction nouvelle par Leconte de
Lisle, Lemerre (1867).
List 2013 List, J-M., Moran, S. "An Open Source
Toolkit for Quantitative Historical Linguistics.", In ACL
(Conference System Demonstrations). (2013), pp. 13–18.
Ma 2006 Ma, X. "Champollion: A robust parallel text
sentence aligner", In LREC 2006: Fifth International
Conference on Language Resources and Evaluation. (2006), pp.
489–492.
Maffei 1523 Maffei, R. Homeri
Odyssea. Hittorpius (1523).
Manmatha 2006 Manmatha, R., Feng, S. "A
hierarchical, HMM-based automatic evaluation of OCR accuracy for a digital
library of books", In Proceedings of the 6th ACM/IEEE-CS
Joint Conference on Digital Libraries (JCDL’06). IEEE (2006), pp.
109–118.
Manning 2014 Manning, CD., Surdeanu, M., Bauer,
J., et al. "The Stanford CoreNLP Natural Language Processing Toolkit.", In
ACL (System Demonstrations). (2014), pp.
55–60.
Meschonnic 1999 Meschonnic, H. Poétique du traduire. Editions Verdier (1999).
Michaud 1843 Michaud, LG., Desplaces, E.
"Bitaubé", In Biographie universelle, ancienne et moderne,
ouvrage rédigé par une société de gens de lettres. (1843), pp.
376–378.
Monro 1902 Monro, DB., Allen, TW. Homeri Opera, recognovit brevique adnotatione critica
instruxit. Scriptorum Classicorum Bibliotheca Oxoniensis. E
typographeo Clarendoniano, Charles Baley (1902).
Montalbetti 1997 Montalbetti, C. "La réalité
peut-elle être homérique ? Les filtres de la fiction", In Le voyage, le monde et la bibliothèque. Presses universitaires de
France (1997).
Needleman 1970 Needleman, SB., Wunsch, CD. "A
general method applicable to the search for similarities in the amino acid
sequence of two proteins", Journal of molecular
biology, 48 (1970): 443–453.
Nelken 2006 Nelken, R., Shieber, SM. "Towards
Robust Context-Sensitive Sentence Alignment for Monolingual Corpora.", In EACL. (2006).
Och 1999 Och, FJ., Tillmann, C., Ney, H. "Improved
alignment models for statistical machine translation", In Proceedings of the Joint SIGDAT Conf. on Empirical Methods in Natural
Language Processing and Very Large Corpora. (1999), pp.
20–28.
Och 2003 Och, FJ., Ney, H. "A systematic comparison
of various statistical alignment models", Computational
linguistics, 29 (2003): 19–51.
OpenNLP, A. 2011 OpenNLP, A. "Apache software
foundation", URL http://opennlp.apache.org, (2011).
Reiter 2014 Reiter, N. "Discovering Structural
Similarities in Narrative Texts using Event Alignment Algorithms".
(2014).
Robert 2000 Robert, MC. "Design principles and
design patterns". Object Mentor, (2000):
1–34.
Salel 1545 Salel, H. Les Dix
premiers livres de l’Iliade d’Homere, prince des poetes : Traduictz en vers
Francois, par M. Hugues Salel... Jean Loys pour Vincent Sertenas
(1545).
Sommer 1854 Sommer, E. L’Odyssée: chants, 2, 6, 9 à 12. Hachette (1854).
Tulach 2008 Tulach, J. Practical API Design: Confessions of a Java Framework Architect.
1st ed. Apress, Berkely, CA, USA (2008).
Viterbi 1967 Viterbi, A. "Error bounds for
convolutional codes and an asymptotically optimum decoding algorithm". IEEE transactions on Information Theory, 13 (1967):
260–269.
Volney 1799 Volney, CF. "Leçons d’Histoire". In
Lecons d’histoire prononcees a l’ecole normale ... accompagnees de notes et de 3
plans (etc.). Brosson (1799), p. 230.
de la Valterie 1708 de la Valterie, A.
"Préface", In L’Iliade. (1708), pp. 1–16.
de la Valterie 1709 de la Valterie, A. L’Odyssée D’Homere. Traduite En Francois. Par M. D*** Enrichie
de Figures en Taille Douce. Chez Michel Brunet (1709).