


Volume 14 Number 4
The Voices of Doctor Who – How Stylometry Can be Useful in Revealing New Information About TV Series
Abstract
This article presents possibilities of effectively using stylometric methods popular in the analysis of literary texts in the study of texts written for television, on the example of Doctor Who. The article examines the changes driving the development of the show moving from character-oriented in the so-called “Classic Who” (1963-1989) to showrunner-oriented in its revival started in 2005. It also seeks to describe stability of the characterization of the protagonist as evidenced in the dialogues, and to discuss authorial relations between showrunners and their teams.
Introduction[1]
1. Distant reading and television studies
1.1 Quantitative approaches to television studies
1.2 Authorship in television
This perspective on authorship by responsibility is also often linked to television, however, in relation not to directors but to showrunners (e.g. Steiner 2015, Jensen 2018, Lavik 2015). A showrunner is an informal term used to describe a person who holds most creative power in the show, usually combining the duties of main scriptwriter and executive producer. The concept is used mostly in relation to American culture (e.g. David Chase, Joss Whedon, Shonda Rhimes, David Simon), but there are also examples of showrunners in the UK (e.g. Russell T Davies, Charlie Brooker) and Scandinavia (Hans Rosenfeldt). Detailed origin and characteristics of this job have so far been subject to few studies, with the most comprehensive analyses by Brett Martin (2013) and Erland Lavik (2015). In his book, Martin looks into the phenomena associated with the popularity of series authored by some of the earliest openly-appointed showrunners and, based on conversations with them and their collaborators, he details existing forms of this mode of work. With all the information he collected, Martin does not hesitate to refer to TV showrunners (such as David Chase) as authors, comparing the conditions of their work to serial Victorian writers, such as Charles Dickens, Anthony Trollope or George Eliot. He also points out that given their decision-making over “story direction to casting to the color of seemingly insignificant characters’ shirts” [Martin 2013, 8] they seem “all-knowing deit[ies].” Martin also observes that showrunners are typically writers (with few examples of showrunners holding only producer credits) and that they tend to emphasize their power over words and world-shaping. While typically there are many writers involved in the writing of a series, there are various ways their work can be organized: collaboration can include a “writers’ room,” where a showrunner meets with writers to pass/develop ideas together in detail before designating a team member to transform such detailed vision into actual script and again to discuss it in the room; in another manner, writers contribute episodes based on a general season narrative arch developed by a showrunner, who supervises execution and introduces corrections and changes to maintain consistency. In turn, in his book Lavik compares American, Dutch and Norwegian styles of showrunning and argues that outside of the American perspective detailed by Martin, showrunners in Europe give their writers much more authorial freedom and have themselves more creative than administrative responsibilities. Interestingly, Lavik also distinguishes between focused (one showrunner for the whole production of the show) or distributed (showrunners changing every (few) seasons) overarching authorship of showrunners, and actual authorship of writers.the literary writer is ultimately celebrated for authorship by origination, assumed (however erroneously) to have written every word as an individual, a film's director is granted authorship by responsibility, ultimately making the necessary creative choices by supervising and guiding all of the film's many collaborators, even if much of the specific work was done by others. [Mittell 2017, 36]
Jensen also notes that despite this complex authorship of television productions, the works of particular showrunners bear similarities across various series, both in style and in specific interests of the authors [Jensen 2017, 33]. He emphasizes interest in “seeing how the various works across an oeuvre depict a topic in different ways, maybe even in contradictory ways” [Jensen 2017, 34] – this is to be expected from an author able to create well-developed characters that differ in their ideas and nature as expressed in their dialogue lines, and can be used to evaluate character-building skills of the author. One method to do so may consist in contrastive analysis discussed later in this paper.other writers work to support the vision founded by the showrunner, or creator. That, however, does not mean that these writers (...) do not make a difference in the final outcome of a series (they most certainly do), but they do so within a paradigm laid down by the creator(s) of the show. [Jensen 2017, 37]
2. Doctor Who – the background of the series
2.1 About the show
2.1 Internal classification of the show
3. Empirical study
3.1 Problems
3.1.1 Obtaining the data
3.1.2. Dataset
3.2 Methods
3.2.1 Conducted types of analysis
3.2.2. Identifying features to be used in the analysis
4 Results
4.1 Development of the show
4.1.1 Episodes
Whole episode perspective:


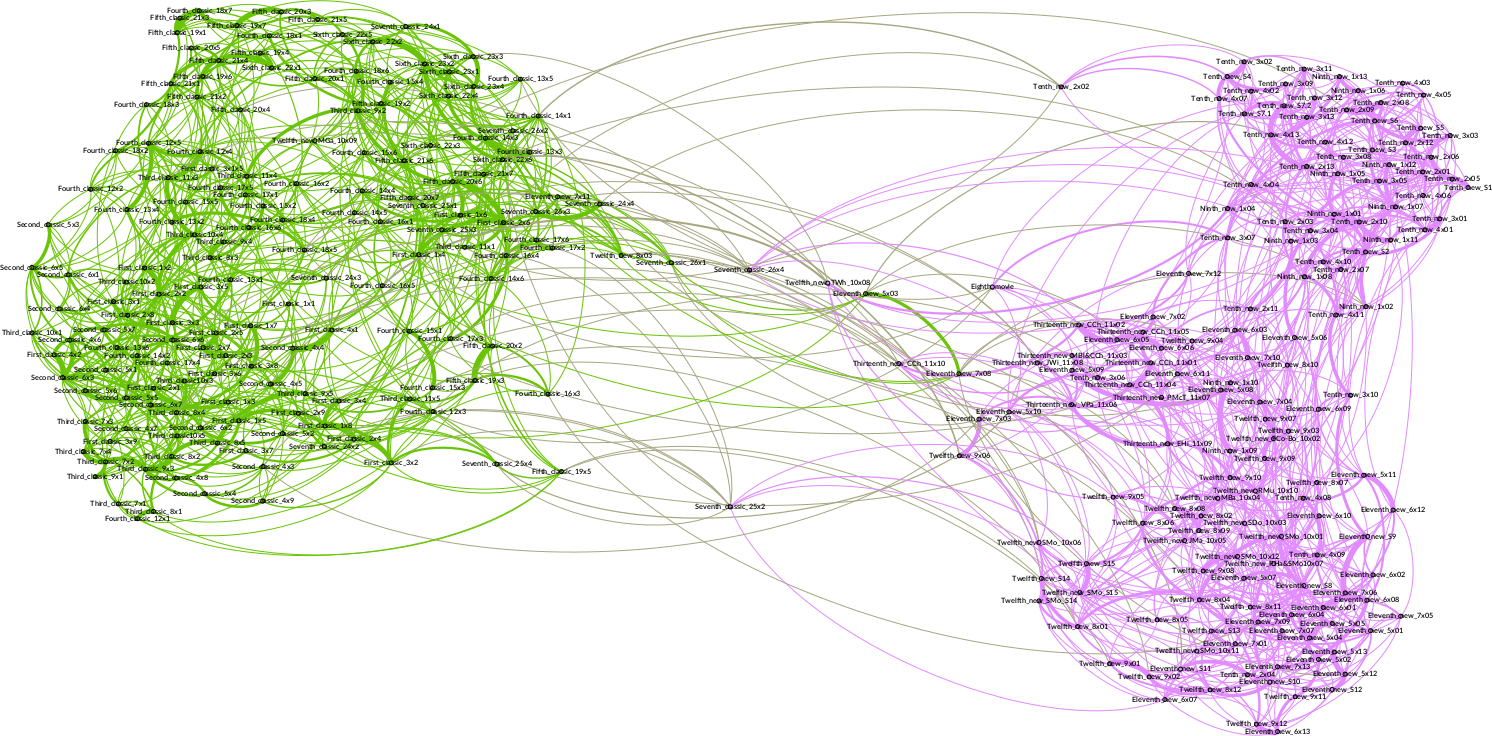
Sampled perspective:
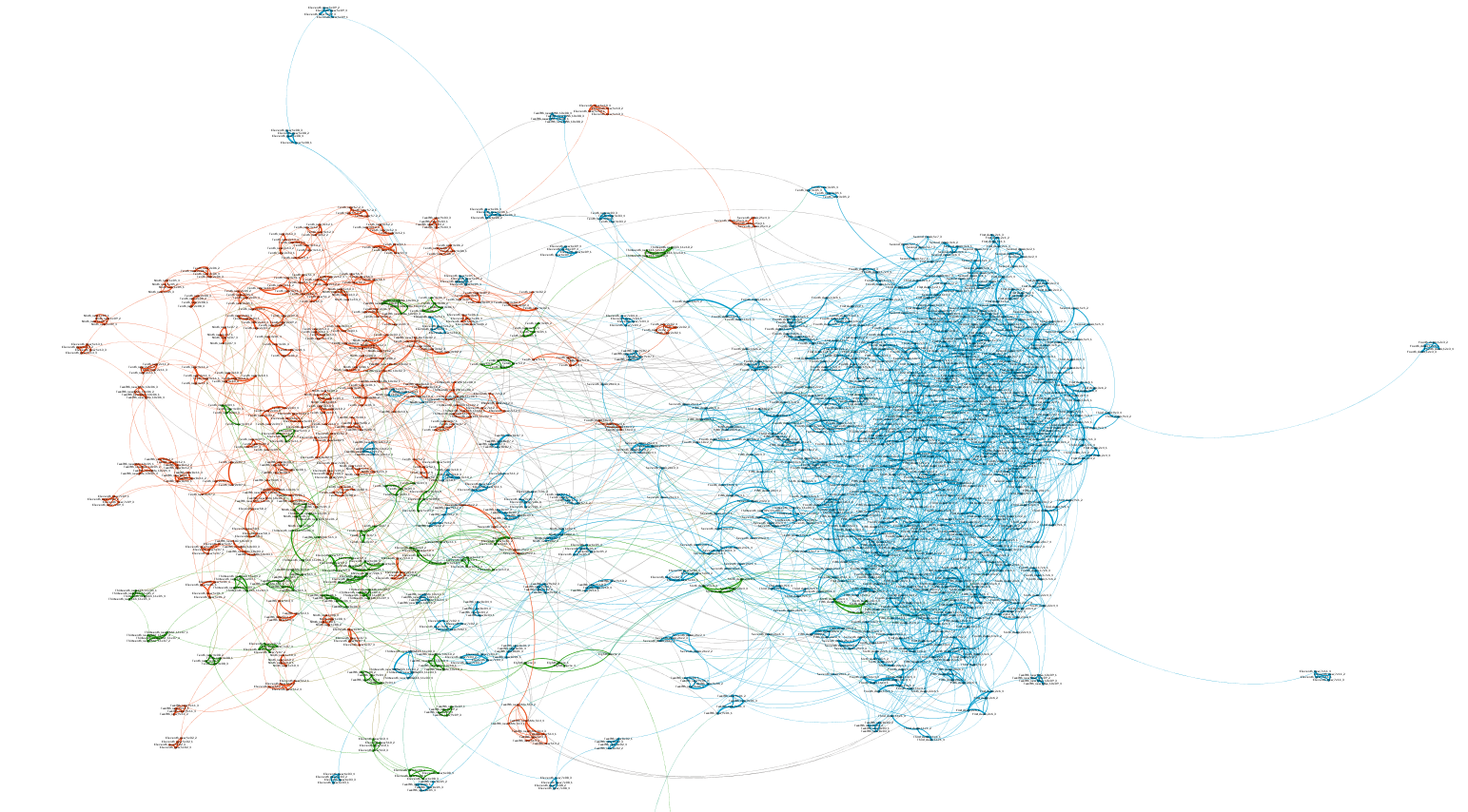
4.1.2 Doctor
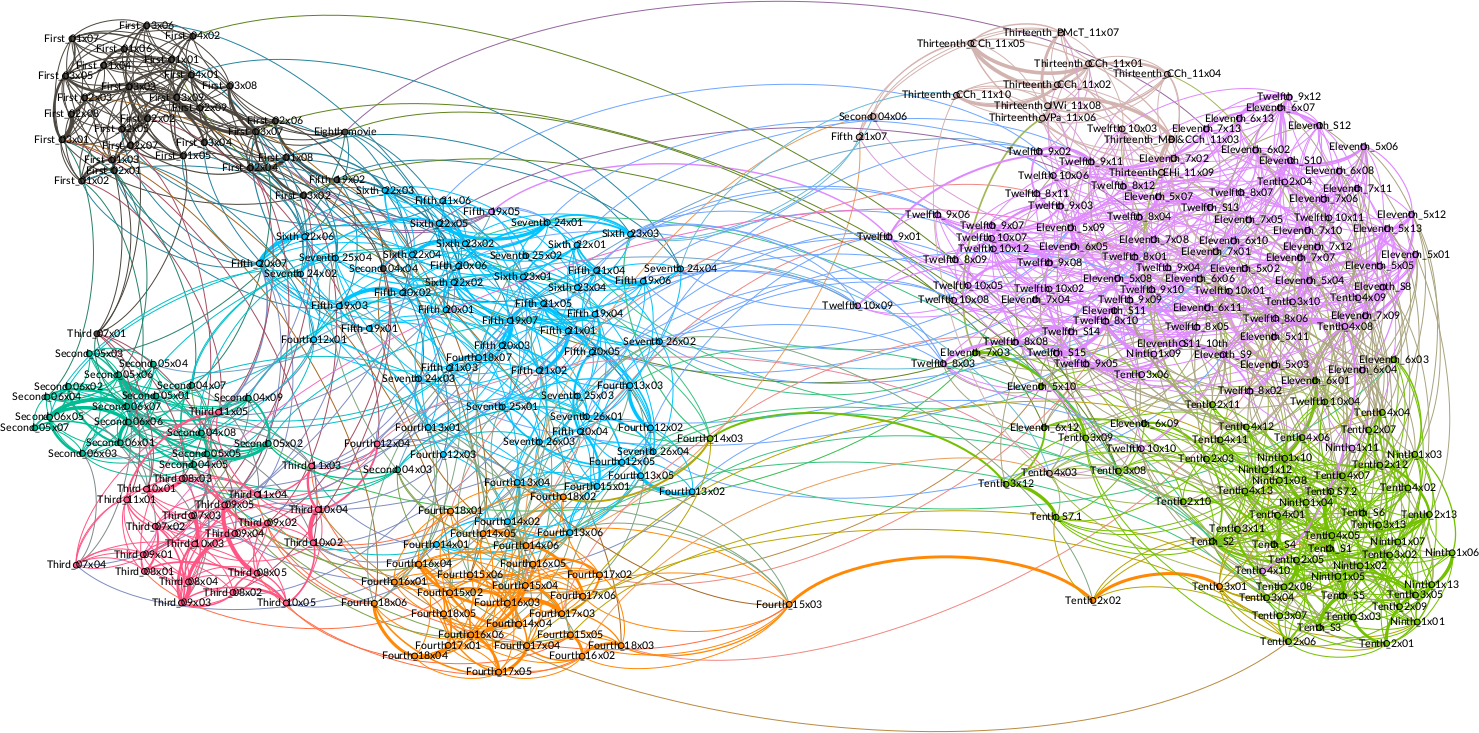
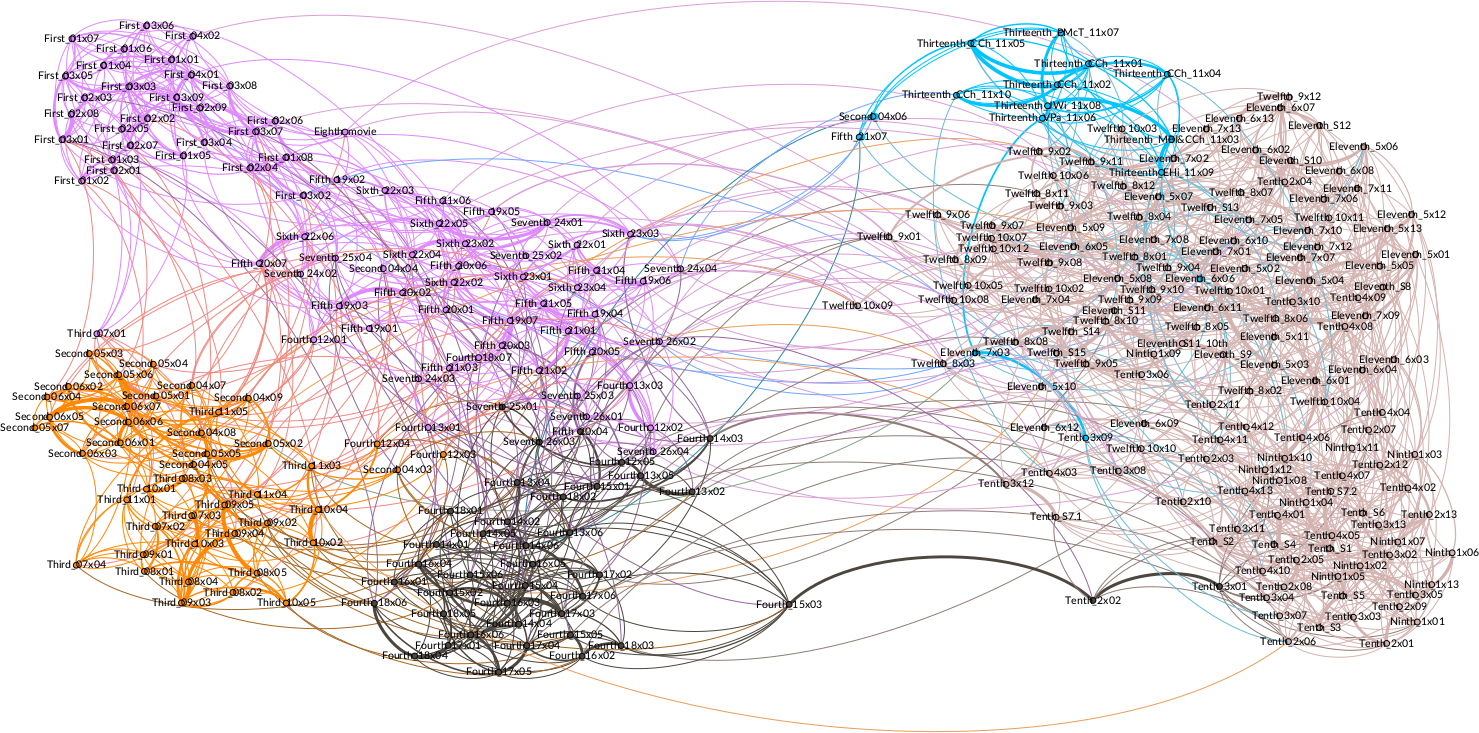
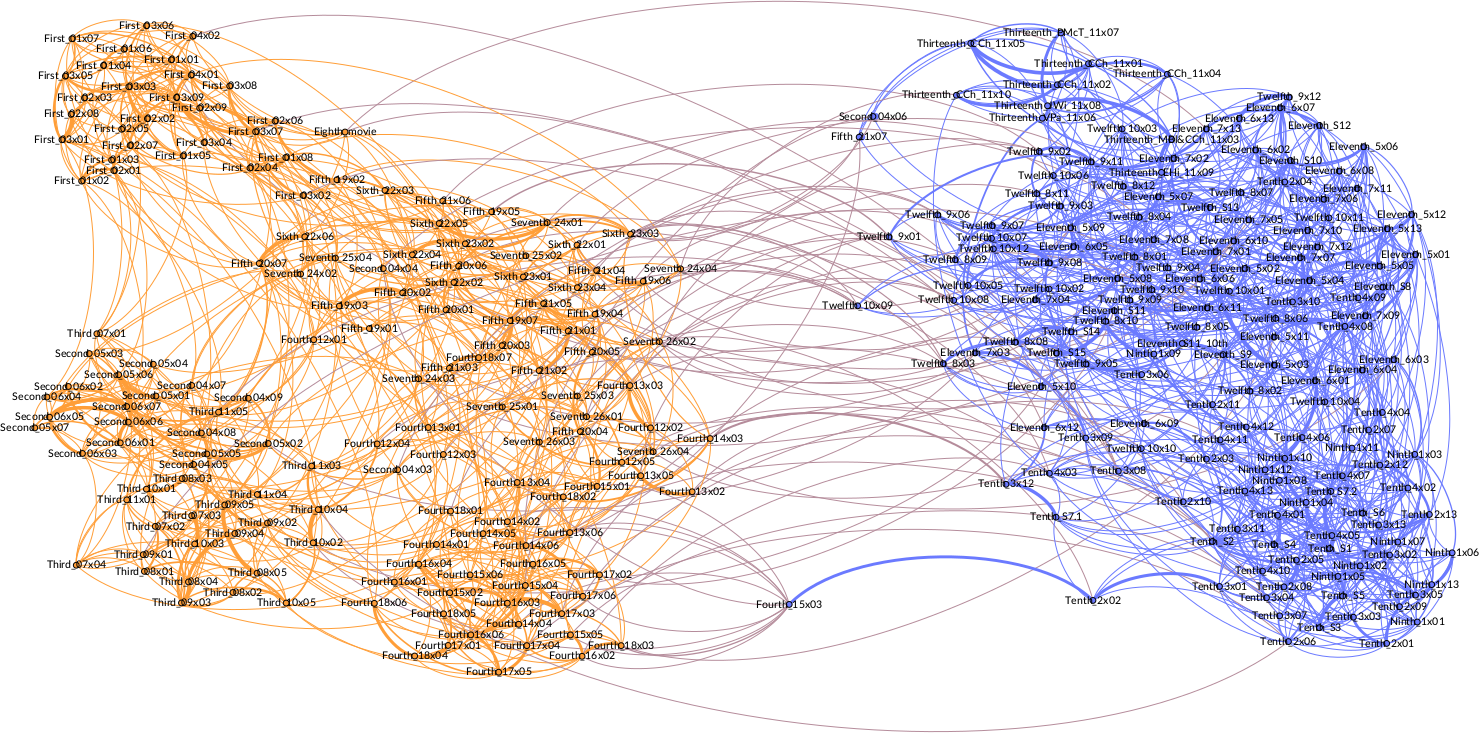
4.2 Authorial influence
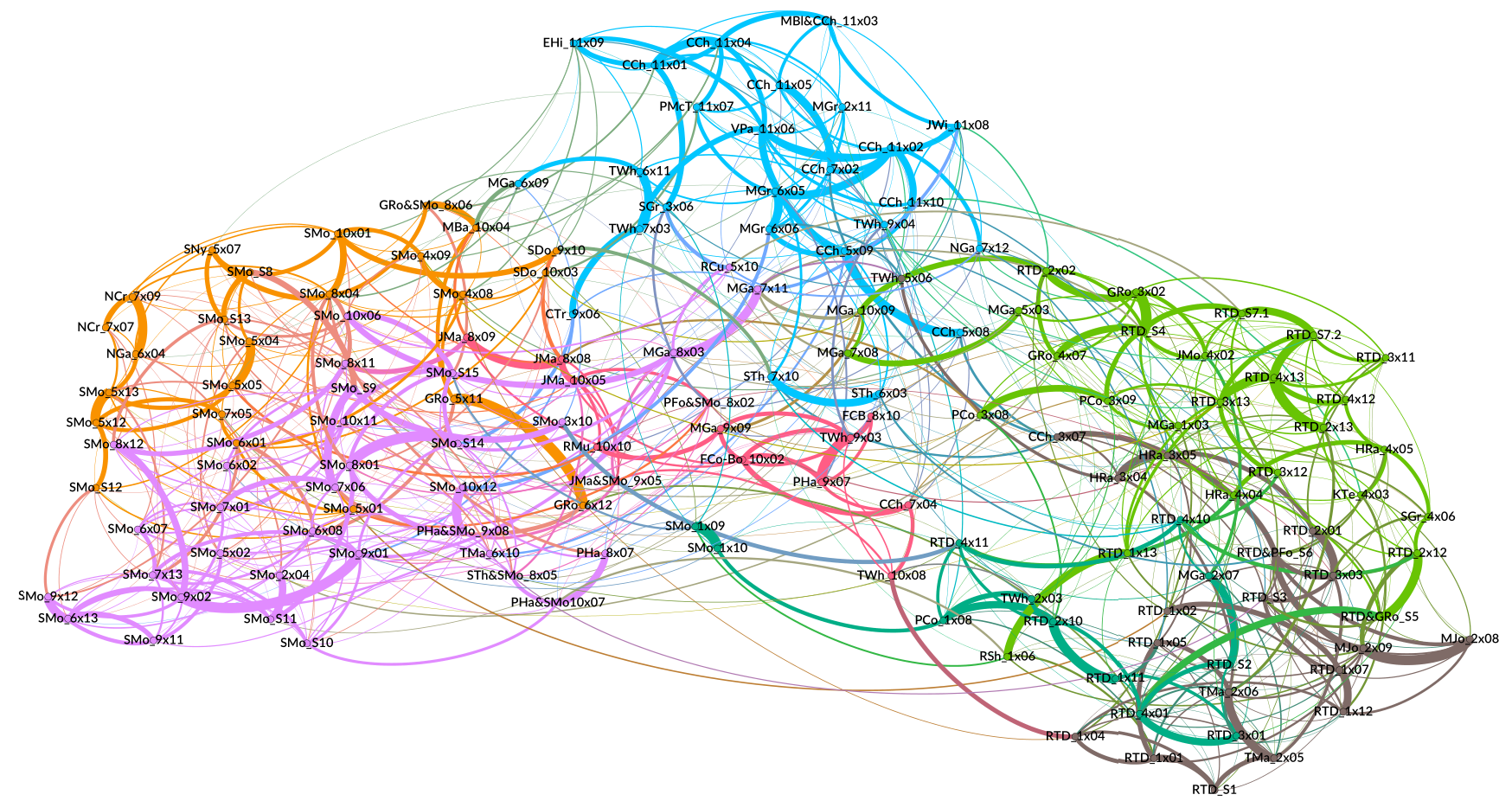

Detailed study of authorial influence:
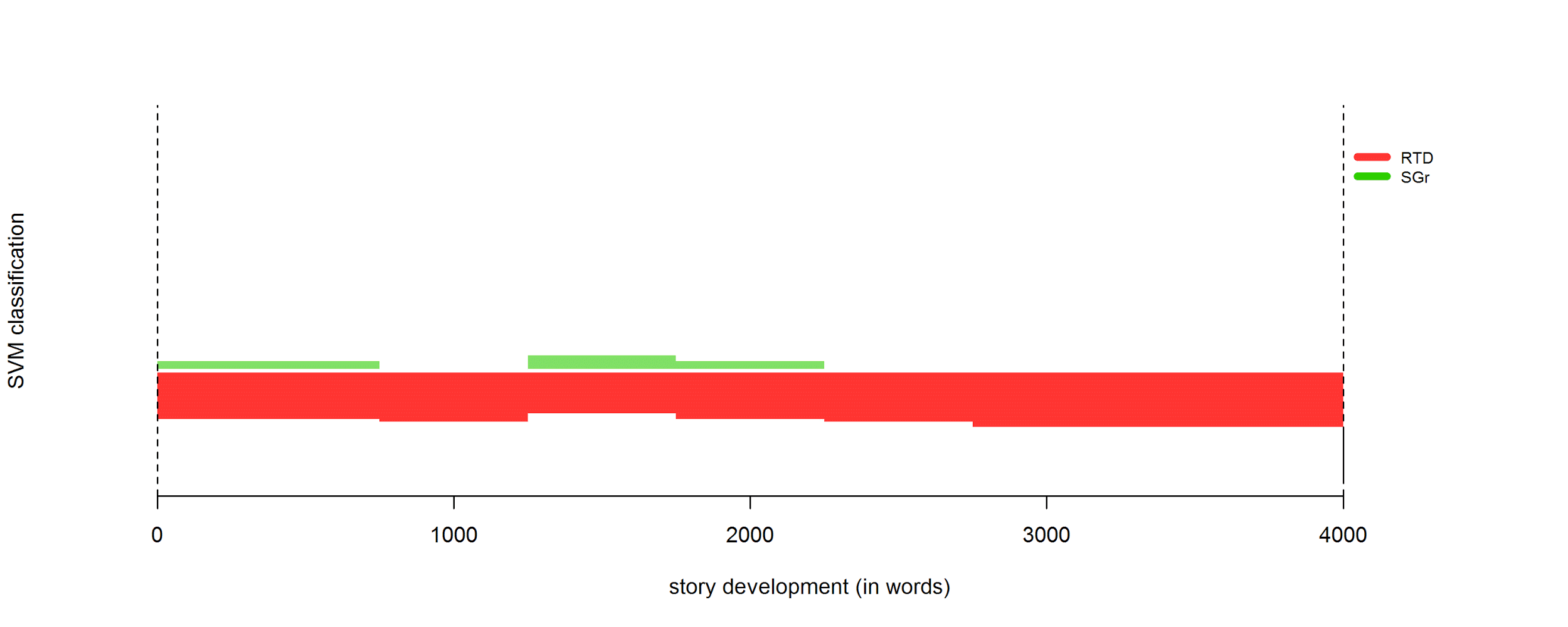
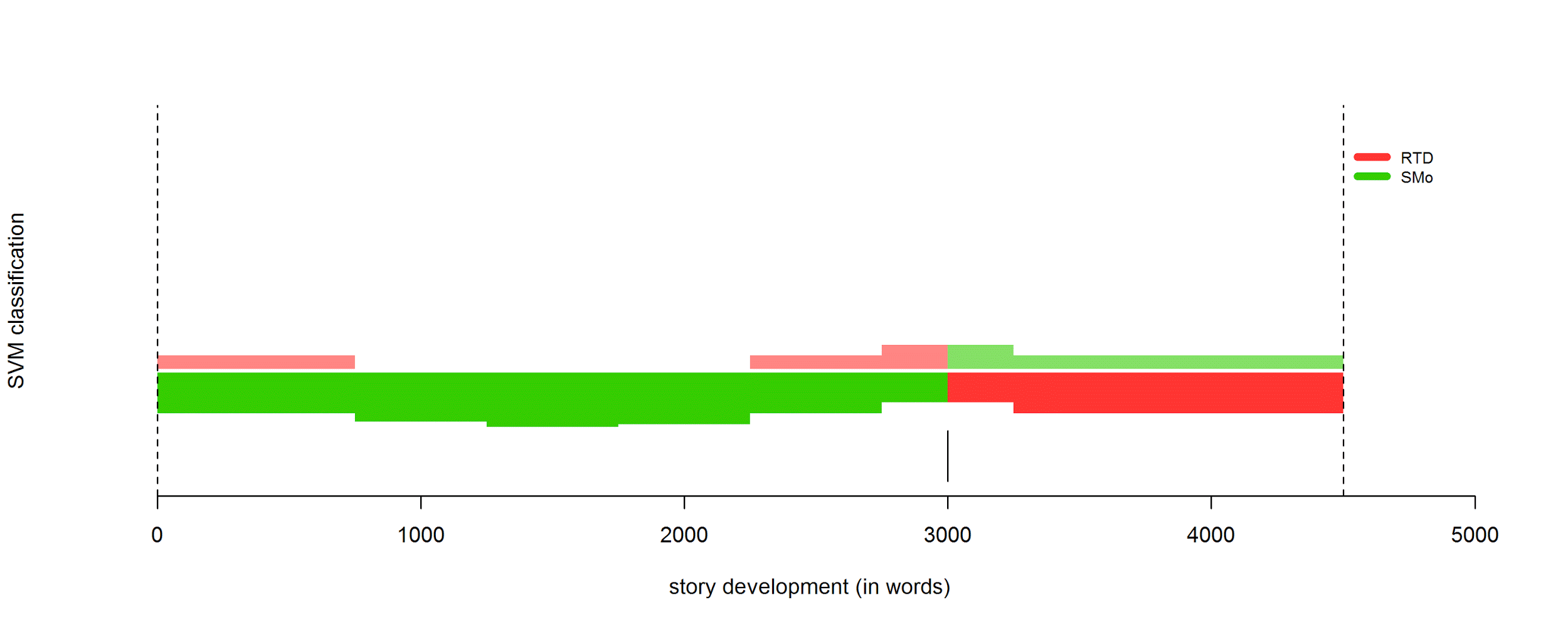
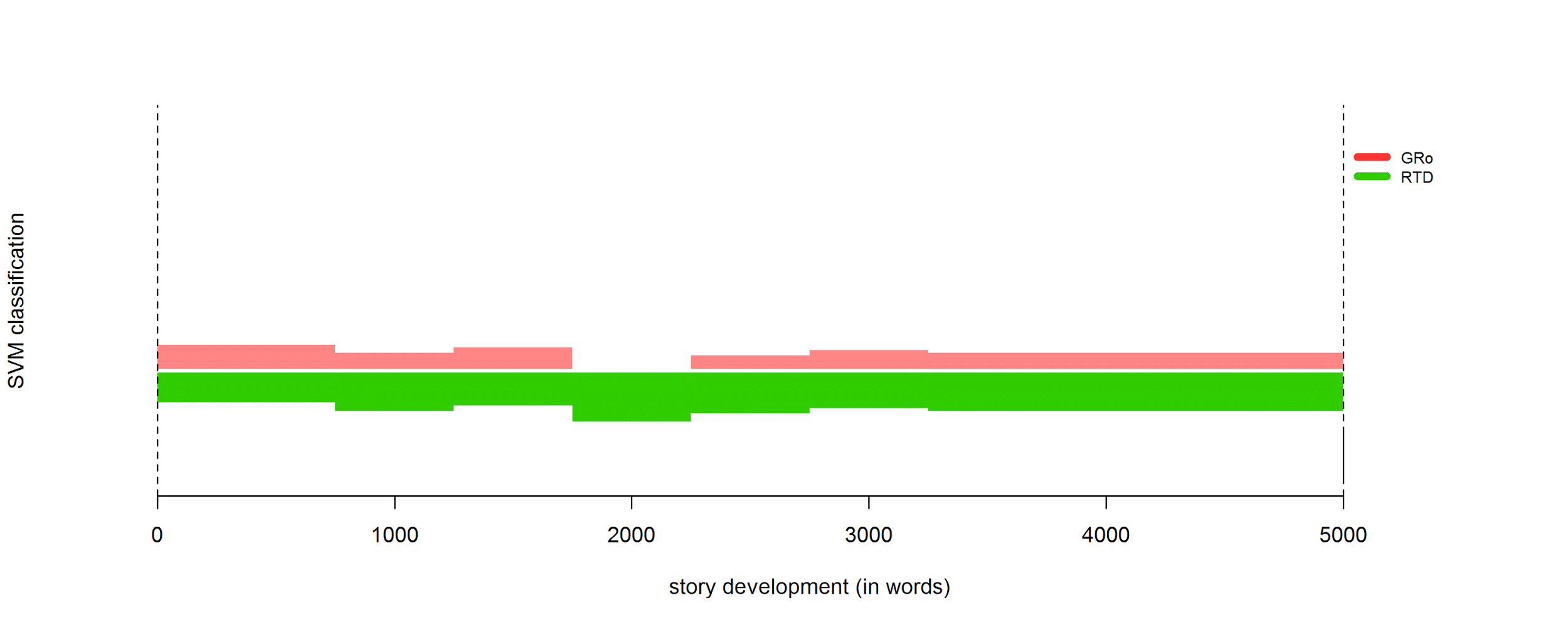

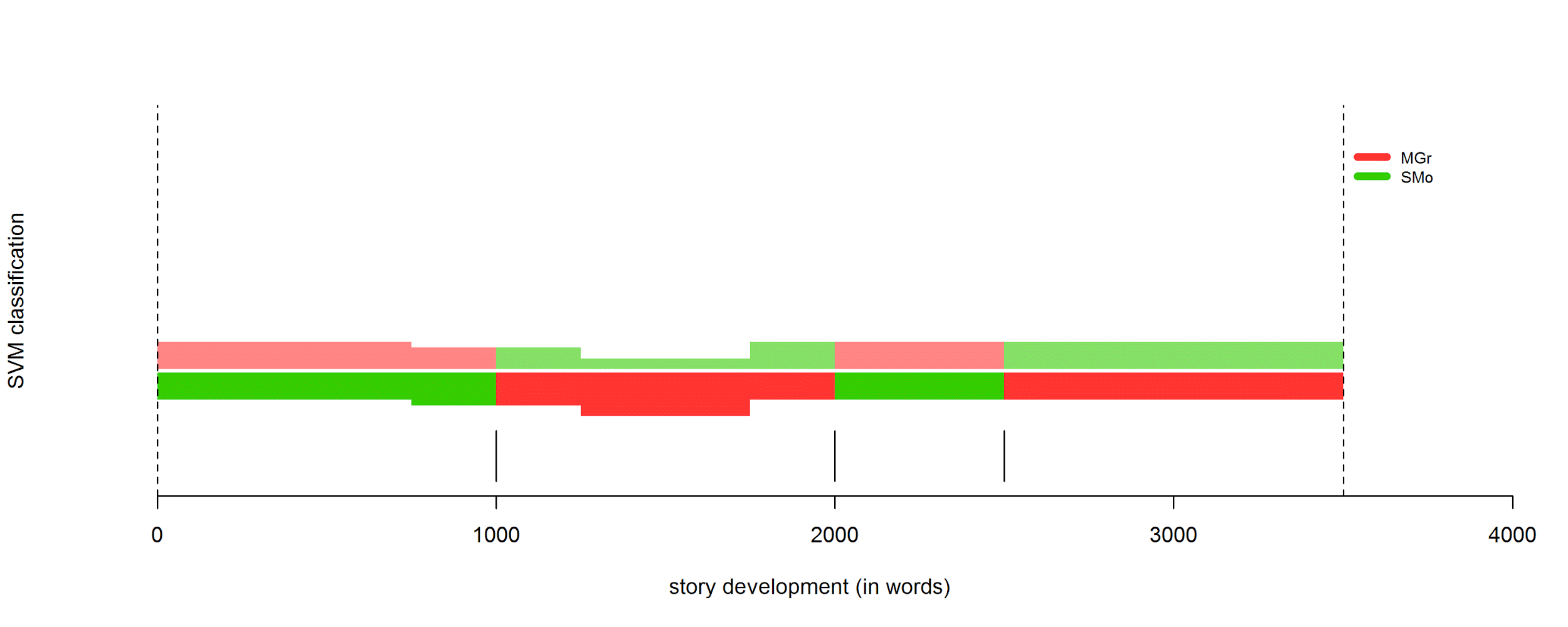
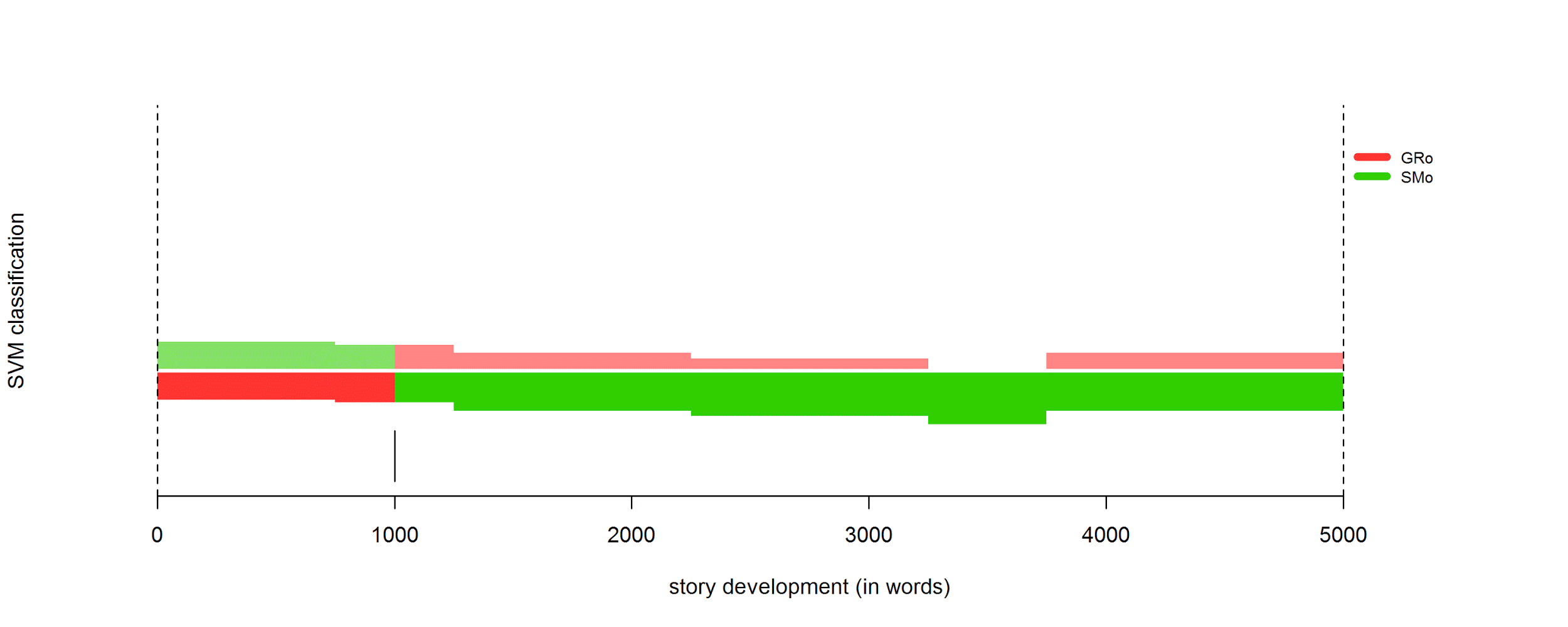
4.3 Character features
5. Conclusions
Acknowledgements
Notes
Works Cited

Comments: dhqinfo@digitalhumanities.org
Published by: The Alliance of Digital Humanities Organizations and The Association for Computers and the Humanities
Affiliated with: Digital Scholarship in the Humanities
DHQ has been made possible in part by the National Endowment for the Humanities.
Copyright © 2005 -

Unless otherwise noted, the DHQ web site and all DHQ published content are published under a Creative Commons Attribution-NoDerivatives 4.0 International License. Individual articles may carry a more permissive license, as described in the footer for the individual article, and in the article’s metadata.
