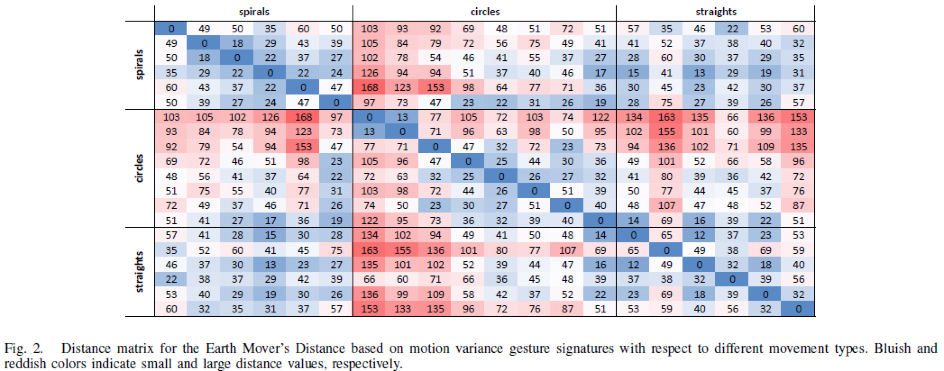
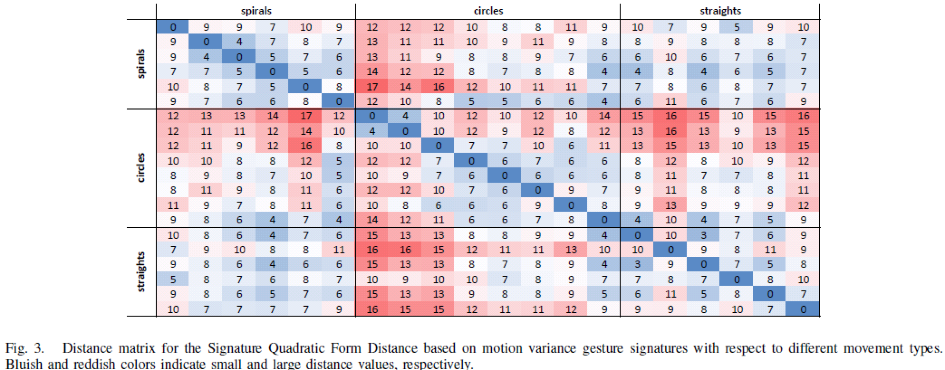
Works Cited
Bavelas 1992 Bavelas, J. B., Chovil, N., Lawrie, D.
A. and Wade, A. “Interactive Gestures”, Discourse Processes, 15 (1992): 469-489.
Beecks 2010 Beecks, C., M.S. Uysal, and Seidl, T.
“A Comparative Study of Similarity Measures for Content-Based
Multimedia Retrieval”. Proceedings of the IEEE
International Conference on Multimedia and Expo, pp. 1552-1557
(2010).
Beecks 2010a Beecks, C., M.S. Uysal, and Seidl, T.
“ Signature Quadratic Form Distance”. Proceedings of the 9th International Conference on Image and Video
Retrieval, pp. 438-445 (2010).
Beecks 2011 Beecks, C., Lokoc, J., Seidl, T., and
Skopal, T. “Indexing the signature quadratic form distance for
efficient content-based multimedia retrieval”. In Proceedings of the ACM International Conference on Multimedia Retrieval,
2011, pp. 24:1–8.
Beecks 2013 Beecks, C., S. Kirchhoff, and Seidl, T.
“On Stability of Signature-Based Similarity Measures for
Content-Based Image Retrieval”. Multimedia Tools and
Applications, pp. 1-14.
Beecks 2013a Beecks, C., S. Kirchhoff, and Seidl, T.
“Signature matching distance for content-based image
retrieval”. Proceedings of the ACM International
Conference on Multimedia Retrieval, pp. 41-48 (2013)
Beecks 2015 Beecks, C., Hassani, M., Hinnell, J.,
Schüller, D., Brenger, B., Mittelberg, I. and Seidl, T. “Spatiotemporal Similarity Search in 3D Motion Capture Gesture Streams”.
Proceedings of the 14th International Symposium on Spatial
and Temporal Databases, pp. 355-372 (2015).
Beecks 2015a Beecks, C., J. Lokoc, T. Seidl, and
Skopal, T. “Indexing the Signature Quadratic Form Distance for
Efficient Content-Based Multimedia Retrieval”. Proceedings of the ACM International Conference on Multimedia Retrieval,
pp. 24:1-8 (2015).
Berndt 1994 Berndt, D. and Clifford, J. “Using dynamic time warping to find patterns in time series”.
AAAI94 Workshop on Knowledge Discovery in Databases,
pp. 359-370 (1994)
Beskow 2011 Beskow, J., Alex, S., Al Moubayed, S.,
Edlund, J. and House, D. “Kinetic Data for Large-Scale Analysis
and Modeling of Face-to-Face Conversation”. In Proceedings of the International Conference on Audio-Visual Speech
Processing, Stockholm, pp. 103–106 (2011).
Bourdieu 1987 Bourdieu, P. Sozialer Sinn. Kritik der theoretischen Vernunft. Suhrkamp, Frankfurt am
Main (1987).
Bressem 2013 Bressem, J. “A
Linguistic Perspective on the Notation of Form Features in Gestures”. In
Müller, C. et al. (eds): Body – Language – Communication. An
International Handbook of Multimodality in Human Interaction. (HSK 38.1).
De Gruyter Mouton, Berlin/Boston,pp. 1079–1098 (2013).
Chen 2005 Chen, L., Özsu, M.T. and Oria, V. “Robust and Fast Similarity Search for Moving Object
Trajectories”. Proceedings of the ACM SIGMOD
International Conference on Management of Data, pp. 491-502 (2005).
Cienki 2005 Cienki, A. “Image
Schemas and Gesture”. In Hampe, B. (ed). From Perception to Meaning: Image Schemas in Cognitive Linguistics. Mouton de
Gruyter, Berlin/New York (2005).
Cienki 2013 Cienki, A. “Cognitive
Linguistics: Spoken Language and Gesture as Expressions of
Conceptualization”. In Müller, C., Cienki, A., Fricke, E., Ladewig, S.,
McNeill, D. and Teßendorf, S. (eds), Body–
Language–Communication: An International Handbook on Multimodality in Human
Interaction, Vol. 1. Mouton de Gruyter, Berlin/New York, pp. 182–201
(2013).
Duncan 2007 Duncan, S., Cassell, J. and Levy E.T.
(eds), Gesture and the Dynamic Dimension of Language.
John Benjamins, Amsterdam/ Philadelphia, pp. 269–283 (2007).
Enfield 2009 Enfield, N. The
Anatomy of Meaning. Speech, Gestures, and Composite Utterances. Cambridge
University Press, Cambridge (2009).
Fang 2009 Fang, S. and Chan, H. “Human Identification by Quantifying Similarity and Dissimilarity in
Electrocardiogram Phase Space”. Pattern
Recognition, vol. 42, 9 (2009): 1824-1831.
Fricke 2010 Fricke, E. “Phonaestheme, Kinaestheme und Multimodale Grammatik”. Sprache und Literatur, 41 (2010): 69–88.
Gibbs 2006 Gibbs, R. W., Jr. Embodiment and Cognitive Science. Cambridge University Press, Cambridge
(2006).
Goldin-Meadow 2003 Goldin-Meadow, S. Hearing Gesture: How Our Hands Help Us Think. Harvard
University Press, Cambridge, MA (2003).
Goldin-Meadow 2007 Goldin-Meadow, S. “Gesture with Speech and Without It”. In Duncan, S. (ed),
Gesture and the Dynamic Dimension of Language: Essays in
Honor of David McNeill. John Benjamins Publishing Company,
Amsterdam/Philadelphia, pp. 31–49 (2007).
Gonzalez-Marquez 2007 Gonzalez-Marquez, M.,
Mittelberg, I., Coulson, S. and Spivey, M.J. (eds). Methods in
Cognitive Linguistics. John Benjamins, Amsterdam/Philadelphia
(2007).
Hetland 2013 Hetland, M.L., Skopal, T., Lokoc, J. and
Beecks, C. “Ptolemaic Access Methods: Challenging the Reign of
the Metric Space Model”. Information Systems,
vol.38, no.7 (2013): 989-1006.
Hillier 1990 Hillier, F. and Lieberman, G.. Introduction to Linear Programming.
McGraw-Hill.(1990)
Itakura 1975 Itakura, F. “Minimum
Prediction Residual Principle Applied to Speech Recognition”. IEEE Transactions on Acoustics, Speech and Signal
Processing, vol.23, no.1 (1975): 67-72.
Johnson 1987 Johnson, M. The
Body in the Mind: The Bodily Basis of Meaning, Imagination, and Reason.
University of Chicago Press, Chicago (1987).
Jäger 2004 Jäger, L. & Linz, E. (eds) Medialität und Mentalität. Theoretische und empirische Studien zum
Verhältnis von Sprache, Subjektivität und Kognition. Fink Verlag, München
(2004).
Kendon 1972 Kendon, A. “Some
Relationships between Body Motion and Speech. An analysis of an example”.
In Siegman, A. and Pope, B. (eds), Studies in Dyadic
Communication. Pergamon Press, Elmsford, NY, pp. 177–210 (1972).
Kendon 2004 Kendon, A. Gesture:
Visible Action as Utterance. Cambridge University Press, Cambridge
(2004).
Keogh 2002 Keogh, E. “Exact
Indexing of Dynamic Time Warping”. Proceedings of 28th
International Conference on Very Large Data Bases, 406-417 (2002).
Ladewig 2011 Ladewig, S. “Putting
the cyclic gesture on a cognitive basis”. CogniTextes, 6 (2011).
Latecki 2005 Latecki, L.J., Megalooikonomou, V.,
Wang, Q., Lakämper, R., Ratanamahatana, C.A. and Keogh, E.J. “Elastic Partial Matching of Time Series.Knowledge Discovery in Databases”,
9th European Conference on Principles and Practice of
Knowledge Discovery in Databases, Lecture Notes in Computer Science, vol.
3721 (2005), Springer, pp. 577-584.
Lu 2010 Lu, P. and Huenerfauth, M. “Collecting a Motion-Capture Corpus of American Sign Language for Data-Driven
Generation Research”. In Proceedings of the NAACL HLT
2010 Workshop on Speech and Language Processing for Assistive
Technologies. Los Angeles, pp. 89–97 (2010).
McNeill 1985 McNeill, D. “So You
Think Gestures are Nonverbal?”. Psychological
Review, 92,3 (1985): 350–371.
McNeill 1992 McNeill, D. Hand
and Mind: What Gestures Reveal about Thought. Chicago University Press,
Chicago (1992).
McNeill 2000 McNeill, D. (ed). Language and Gesture. Cambridge University Press, Cambridge
(2000).
McNeill 2001 McNeill, D., Quek, F., McCullough,
K.-E., Duncan, S., Furuyama, N., Bryll, R., Ma, X.-F. and Ansari, R. 2001. “Catchments, Prosody and Discourse”, Gesture 1, 1 (2001): 9–33.
McNeill 2005 McNeill, D. Gesture and Thought. Chicago
University Press, Chicago (2005).
McNeill 2012 McNeill, D. How
Language Began: Gesture and Speech in Human Evolution. Cambridge
University Press, Cambridge (2012).
Mitteberg 2014 Mittelberg, I. and Waugh, L.R.
“Gestures and Metonymy”. In Müller, C., Cienki, A.,
Fricke, E., Ladewig, S.H., McNeill, D. and Bressem, J. (eds), Body – Language – Communication. An International Handbook on Multimodality in
Human Interaction. Vol. 2. Handbooks of Linguistics and Communcation
Science. De Gruyter Mouton, Berlin/Boston, pp. 1747–1766 (2014).
Mittelberg 2010 Mittelberg, I. “Geometric and Image-Schematic Patterns in Gesture Space”. In
Evans, V. and Chilton, P. (eds), Language, Cognition, and Space:
The State of the Art and New Directions. Equinox, London, pp., 351–385
(2010).
Mittelberg 2010a Mittelberg, I. “Interne und externe Metonymie: Jakobsonsche Kontiguitätsbeziehungen
in redebegleitenden Gesten”. Sprache und
Literatur 41,1 (2010): 112–143.
Mittelberg 2013 Mittelberg, I. “Balancing Acts: Image Schemas and Force Dynamics as Experiential
Essence in Pictures by Paul Klee and their Gestural Enactments”. In B.
Dancygier, M. Bokrent and J. Hinnell (eds), Language and the
Creative Mind. Stanford: Center for the Study of Language and Information,
pp. 325–346.
Mittelberg 2013a Mittelberg, I. “The Exbodied Mind: Cognitive-Semiotic Principles as Motivating
Forces in Gesture”. In Müller, C., Cienki, A., Fricke, E., Ladewig, S.H.,
McNeill, D. and Teßendorf, S. (eds). Body – Language –
Communication: An International Handbook on Multimodality in Human
Interaction. Handbooks of Linguistics and Communication Science (38.1).
Mouton de Gruyter,Berlin/New York, pp. 750-779 (2013).
Mittelberg 2016 Mittelberg, I., Schüller, D.
“Kulturwissenschaftliche Orientierung in der
Gestenforschung”. In Jäger, L., Holly, W., Krapp, P., Weber, S. (eds.).
Language – Culture – Communication. An International Handbook
of Linguistics as Cultural Study. Mouton de Gruyter, Berlin/New York, pp.
879-890 (2016).
Müller 1998 Müller, C. Redebegleitende Gesten. Kulturgeschichte - Theorie - Sprachvergleich. Berlin Verlag
A. Spitz, Berlin (1998).
Müller 2008 Müller, C. Metaphors
Dead and Alive, Sleeping and Waking. A Dynamic View. University of Chicago
Press, Chicago (2008).
Müller 2010 Müller, C. “Wie
Gesten bedeuten. Eine kognitiv-linguistische und sequenzanalytische
Perspektive”, Sprache und Literatur 41 (2010):
37–68.
Müller 2013 Müller, C., Cienki, A., Fricke, E.,
Ladewig, S., McNeill, D. and Teßendorf, S. (eds). Body–
Language–Communication: An International Handbook on Multimodality in Human
Interaction, Vol. 1. Mouton de Gruyter, Berlin/New York (2013).
Müller 2014 Müller, C., Cienki, A., Fricke, E.,
Ladewig, S., McNeill, D. and Bressem, J.(eds). Body–
Language–Communication: An International Handbook on Multimodality in Human
Interaction, Vol. 2. Mouton de Gruyter, Berlin/New York (2014).
Pfeiffer 2013 Pfeiffer, T. “Documentation with Motion Capture”. In Müller, C., Cienki, A., Fricke, E.,
Ladewig, S.H., McNeill, D. and Teßendorf, S. (eds). Body-
Language-Communication: An International Hand- book on Multimodality in Human
Interaction, Hand- books of Linguistics and Communication Science. Mouton
de Gruyter, Berlin, New York (2013).
Pfeiffer 2013a Pfeiffer, T., Hofmann, F., Hahn, F.,
Rieser, H., and Röpke, I. “Gesture Semantics Reconstruction Based
on Motion Capturing and Complex Event Processing: A Circular Shape
Example”. In M. Eskenazi, M. Strube, B. Di Eugenio, and J. D. Williams (eds).
Proceedings of the Special Interest Group on Discourse and
Dialog (SIGDIAL) 2013 Conference, pp. 270–279 (2013).
Quine 1980 Quine, W.V.O. Wort und
Gegenstand. Reclam, Stuttgart (1980).
Rieser 2012 Rieser H., Bergmann K. and Kopp, S. “How do Iconic Gestures Convey Visuo-Spatial Information? Bringing
Together Empirical, Theoretical, and Simulation Studies.” In Efthimiou, E.
and Kouroupetroglou, G. (eds). Gestures in Embodied
Communication and Human-Computer Interaction. Springer, Berlin/Heidelberg
(2012).
Rodgers 1988 Rodgers, J. and Nicewander, W. Thirteen Ways to Look at the Correlation Coefficient.
American Statistician, pp. 59-66 (1988).
Rovine 1997 Rovine, M. and Von Eye, A. “A 14th Way to Look at a Correlation Coefficient: Correlation as the
Poportion of Matches”. American Statistician,
pp. 42-46 (1997)
Rubner 2000 Rubner, Y., C. Tomasi, and Guibas, L.J.
“The Earth Mover's Distance as a Metric for Image
Retrieval”, International Journal of Computer
Vision, vol. 40,2 (2000): 99-121.
Sakoe 1978 Sakoe, H. and Chiba, S. “Dynamic Programming Algorithm Optimization for Spoken Word Recognition”,
IEEE Transactions on Acoustics, Speech and Signal
Processing, vol. 26, 1(1978): 43-49.
Schölkopf 2001 Schölkopf, B. “The Kernel Trick for Distances”. Advances in Neural
Information Processing Systems, 301-307.
Steen 2013 Steen, L. and Turner, M. “Multimodal Construction Grammar”. In Dancygier, B., Bokrent,
M. and Hinnell, J. (eds). Language and the Creative Mind,
Stanford: Center for the Study of Language and Information (2013).
Streeck 2011 Streeck, J., Goodwin, C. and LeBaron,
C.D. Embodied Interaction: Language and Body in the Material
World: Learning in doing: Social, Cognitive and Computational
Perspectives. Cambridge University Press, New York (2011).
Sweetser 2007 Sweetser, E. “Looking at Space to Study Mental Spaces: Co-speech Gesture as a Crucial Data
Source in Cognitive Linguistics”. In Gonzalez-Marquez, M., Mittelberg, I.,
Coulson, S. and Spivey, M. (eds). Methods in Cognitive
Linguistics. John Benjamins, Amsterdam/Philadelphia, pp. 201¬224
(2007).
Tomasello 1999 Tomasello, M. The Cultural Origins of Human Cognition. Harvard University Press,
Cambridge, MA (1999).
Uysal 2014 Uysal, M.S., Beecks, C., Schmücking, J., and
Seidl, T. “Efficient Filter Approximation using the Earth Mover's
Distance in Very Large Multimedia Databases with Feature Signatures”.
Proceedings of the 23rd ACM International Conference on
Conference on Information and Knowledge Management, pp. 979-988
(2014).