


Volume 11 Number 2
Exploratory Search Through Visual Analysis of Topic Models
Abstract
This paper addresses exploratory search in large collections of historical texts. By way of example, we apply our method to a collection of documents comprising dossiers of the former East-German Ministry for State Security, and classical texts. The bases of our approach are topic models, a class of algorithms that define and infer themes pervading the corpus as probability distributions over the vocabulary. Our topic-centered visual metaphor supports to explore the corpus following an intuitive methodology: First, determine a topic of interest, second, suggest documents that contain the topic with "sufficient" proportion, and third, browse iteratively through related topics and documents. Our main focus lies on providing a suitable bird's eye view onto the data to facilitate an in-depth analysis in terms of the topics contained.
Introduction
Topic Models
- for all topics k = 1,...,K, draw topics βk ~ DirV(η)
- for all documents d = 1,...,D
- draw document d's topic proportion θd ~ DirK(α)
- for all words n = 1,...,Nd in the document
- draw the topic assignment zdn ~ Mult(θd)
- draw the word wdn ~ Mult(βzdn)
Related Work
Exploration Tasks
Definition of Exploration Tasks
Exploration Task 1 - Examining a Topic
Exploration Task 2 - Overview over the Topics
Exploration Task 3 - Finding Different Polysemous and Homonymic Semantics of Terms
Exploration Task 4 - Identifying Documents Covering a Topic
Exploration Task 5 - Finding Related Topics of a Document
Visualization Approach
Visual Implementation of Exploration Tasks
Visual Implementation of Exploration Task 1 - Examining a Topic
Visual Implementation of Exploration Task 2 - Overview over the Topics
Visual Implementation of Exploration Task 3 - Finding Different Polysemous and Homonymic Terms
Visual Implementation of Exploration Task 4 - Documents Covering a Topic
Visual Implementation of Exploration Task 5 - Finding Related Topics of a Document
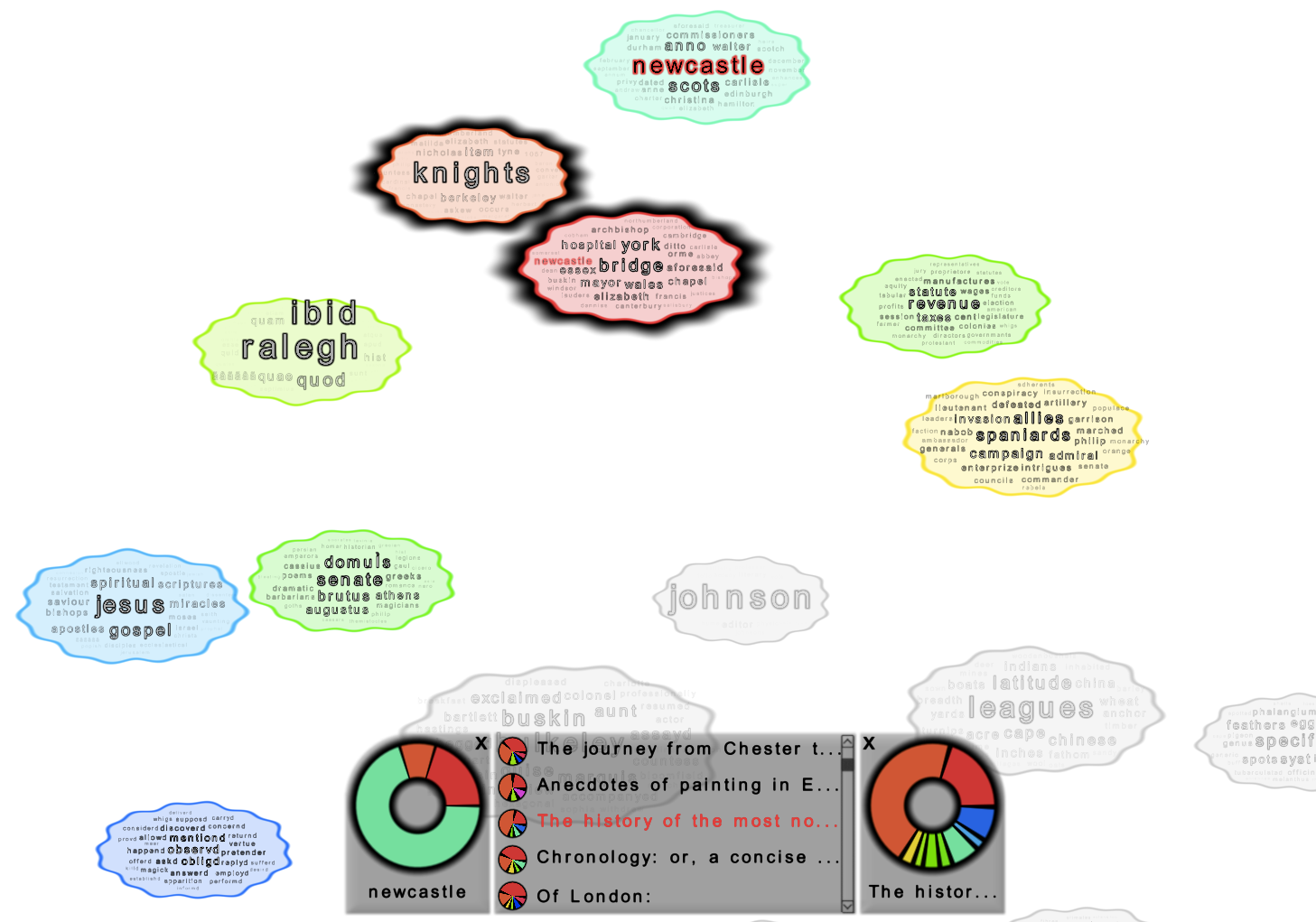
User Interaction Mechanisms
Selecting a Topic
Selecting a Word
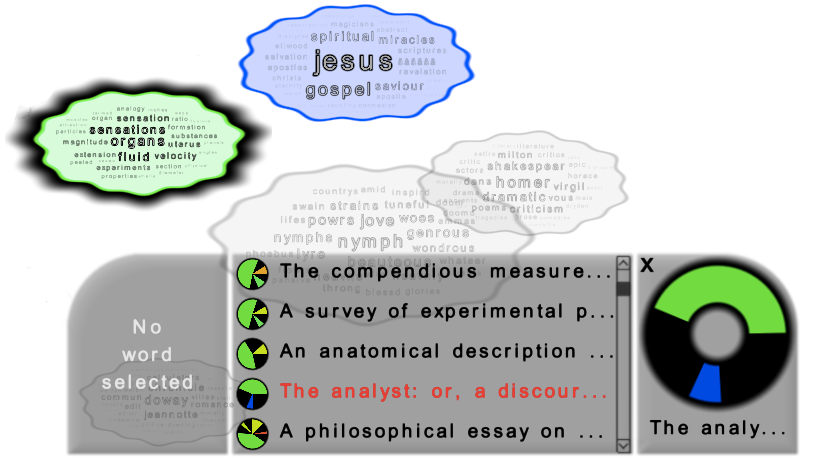
Selecting a Document
Cyclic Analysis Process and Visual Context of Topics
Experiments
Data Sets
Examining a topic


Overview of the Topics
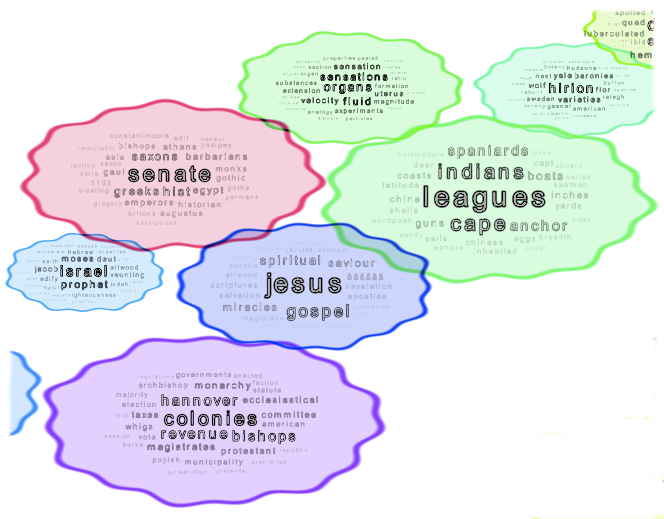

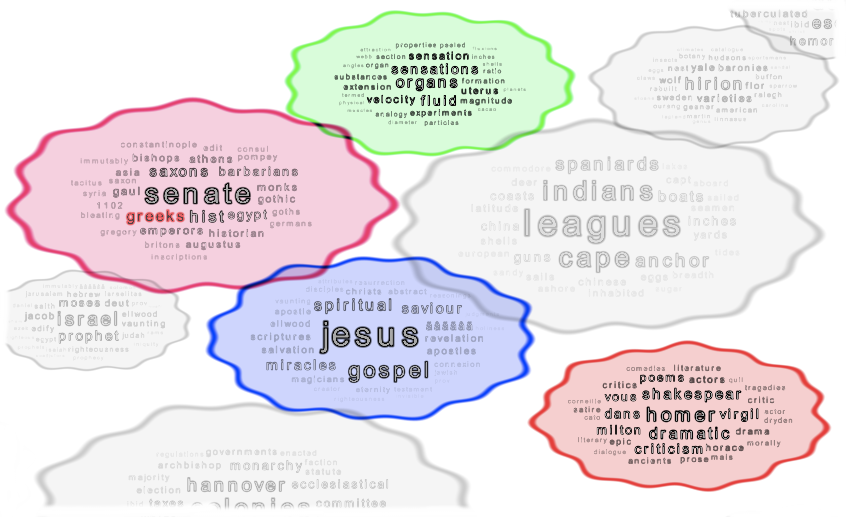
Finding different semantics

Identifying documents covering a topic
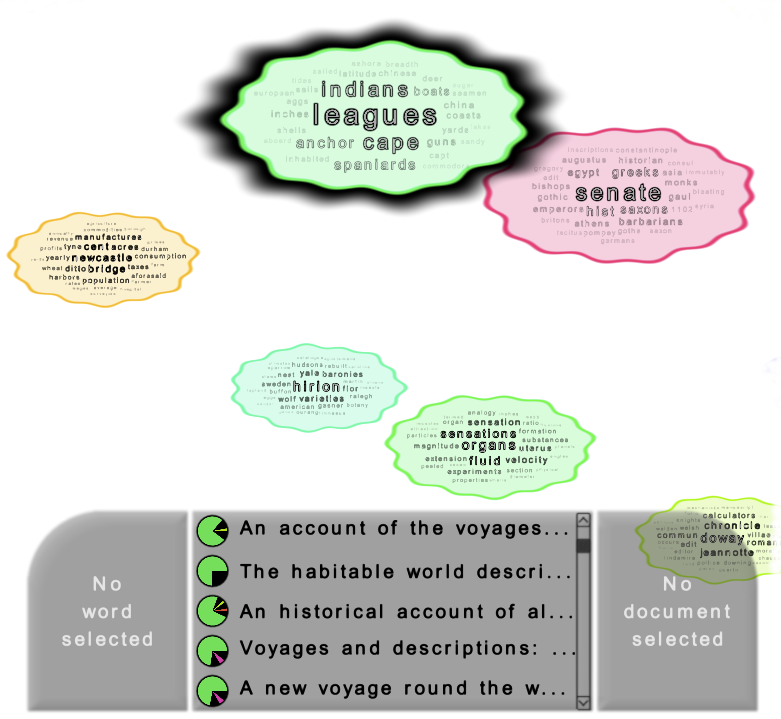

Finding related topics of a document
Discussion and Future Work
Notes
Works Cited

Comments: dhqinfo@digitalhumanities.org
Published by: The Alliance of Digital Humanities Organizations and The Association for Computers and the Humanities
Affiliated with: Digital Scholarship in the Humanities
DHQ has been made possible in part by the National Endowment for the Humanities.
Copyright © 2005 -

Unless otherwise noted, the DHQ web site and all DHQ published content are published under a Creative Commons Attribution-NoDerivatives 4.0 International License. Individual articles may carry a more permissive license, as described in the footer for the individual article, and in the article’s metadata.
